Hive 面试
Hive 简介
【基础】什么是 Hive?
要点
Apache Hive 是一种分布式、容错数据仓库,支持大规模分析。Hive Metastore (HMS) 提供了一个元数据的中央存储库,可以轻松分析以做出明智的数据驱动决策,因此它是许多数据湖架构的关键组件。Hive 构建在 Apache Hadoop 之上,并通过 hdfs 支持在 S3、adls、gs 等上进行存储。Hive 允许用户使用 SQL 读取、写入和管理 PB 级数据。
Hive 可以将结构化的数据文件映射成表,并提供类 SQL 查询功能。用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
特点:
- 简单、容易上手(提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
- 灵活性高,可以自定义用户函数 (UDF) 和存储格式;
- 为超大的数据集设计的计算和存储能力,集群扩展容易;
- 统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
- 执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。
【基础】什么是 HMS?
要点
Hive Metastore (HMS) 是关系数据库中 Hive 表和分区元数据的中央存储库,它使用元存储服务 API 为客户端(包括 Hive、Impala 和 Spark)提供对此信息的访问。它已成为利用各种开源软件(如 Apache Spark 和 Presto)的数据湖的构建块。事实上,整个工具生态系统,无论是开源的还是其他的,都是围绕 Hive Metastore 构建的,下图说明了其中一些。
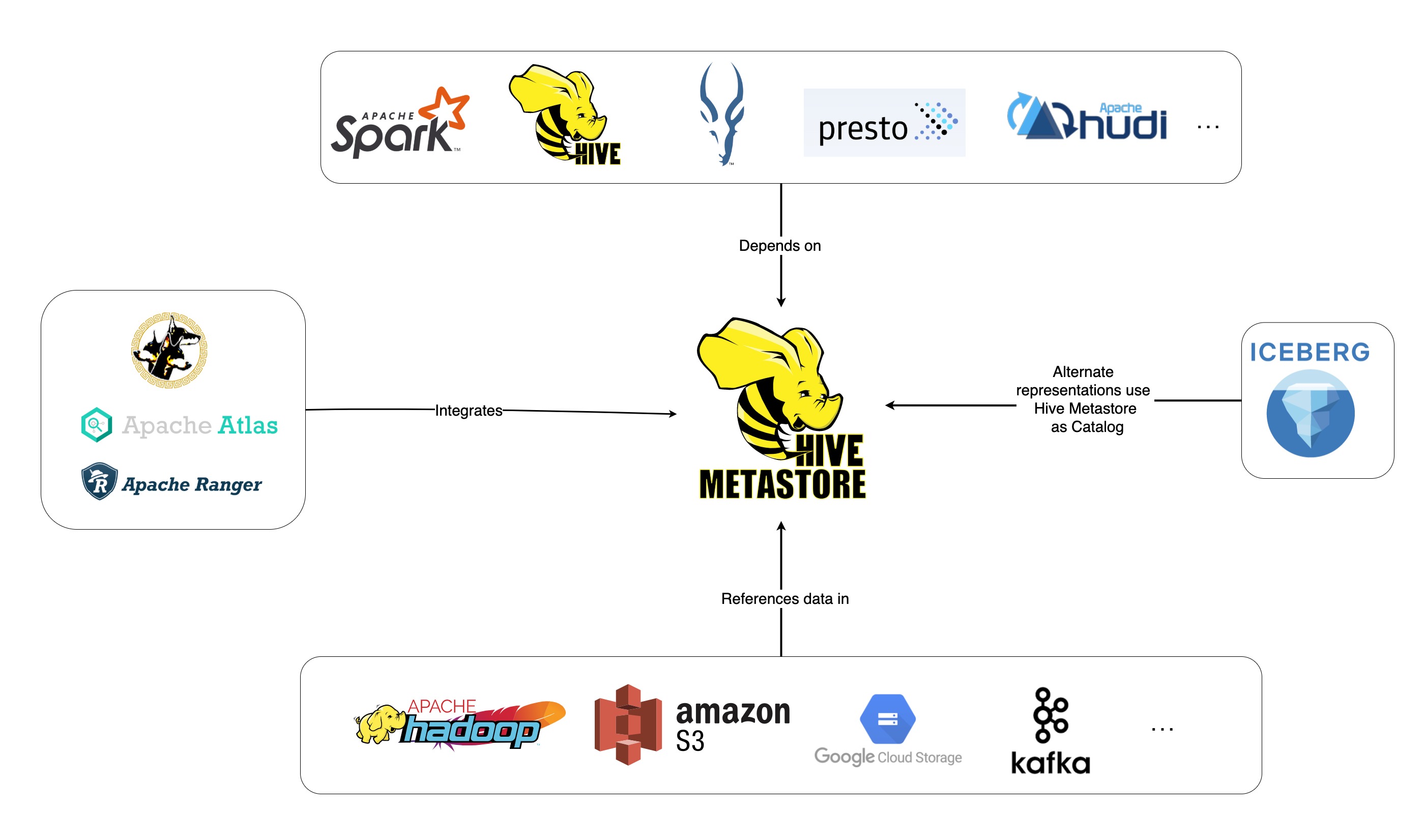
Hive 存储
【基础】Hive 支持哪些数据类型?
要点
Hive 表中的列支持以下基本数据类型:
| 大类 | 类型 |
|---|---|
| Integers(整型) | TINYINT—1 字节的有符号整数 SMALLINT—2 字节的有符号整数 INT—4 字节的有符号整数 BIGINT—8 字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN—TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT— 单精度浮点型 DOUBLE—双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL—用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING—指定字符集的字符序列 VARCHAR—具有最大长度限制的字符序列 CHAR—固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP — 时间戳 TIMESTAMP WITH LOCAL TIME ZONE — 时间戳,纳秒精度 DATE—日期类型 |
| Binary types(二进制类型) | BINARY—字节序列 |
TIMESTAMP 和 TIMESTAMP WITH LOCAL TIME ZONE 的区别如下:
- TIMESTAMP WITH LOCAL TIME ZONE:用户提交时间给数据库时,会被转换成数据库所在的时区来保存。查询时则按照查询客户端的不同,转换为查询客户端所在时区的时间。
- TIMESTAMP :提交什么时间就保存什么时间,查询时也不做任何转换。
此外,Hive 还支持以下复杂类型:
| 类型 | 描述 | 示例 |
|---|---|---|
| STRUCT | 类似于对象,是字段的集合,字段的类型可以不同,可以使用 名称。字段名 方式进行访问 | STRUCT ('xiaoming', 12 , '2018-12-12') |
| MAP | 键值对的集合,可以使用 名称 [key] 的方式访问对应的值 | map('a', 1, 'b', 2) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合,可以使用 名称 [index] 访问对应的值 | ARRAY('a', 'b', 'c', 'd') |
【基础】Hive 支持哪些存储格式?
要点
Hive 会在 HDFS 为每个数据库上创建一个目录,数据库中的表是该目录的子目录,表中的数据会以文件的形式存储在对应的表目录下。Hive 支持以下几种文件存储格式:
| 格式 | 说明 |
|---|---|
| TextFile | 存储为纯文本文件。 这是 Hive 默认的文件存储格式。这种存储方式数据不做压缩,磁盘开销大,数据解析开销大。 |
| SequenceFile | SequenceFile 是 Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用 Hadoop 的标准的 Writable 接口实现序列化和反序列化。它与 Hadoop API 中的 MapFile 是互相兼容的。Hive 中的 SequenceFile 继承自 Hadoop API 的 SequenceFile,不过它的 key 为空,使用 value 存放实际的值,这样是为了避免 MR 在运行 map 阶段进行额外的排序操作。 |
| RCFile | RCFile 文件格式是 FaceBook 开源的一种 Hive 的文件存储格式,首先将表分为几个行组,对每个行组内的数据按列存储,每一列的数据都是分开存储。 |
| ORC Files | ORC 是在一定程度上扩展了 RCFile,是对 RCFile 的优化。 |
| Avro Files | Avro 是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro 提供的机制使动态语言可以方便地处理 Avro 数据。 |
| Parquet | Parquet 是基于 Dremel 的数据模型和算法实现的,面向分析型业务的列式存储格式。它通过按列进行高效压缩和特殊的编码技术,从而在降低存储空间的同时提高了 IO 效率。 |
以上压缩格式中 ORC 和 Parquet 的综合性能突出,使用较为广泛,推荐使用这两种格式。
通常在创建表的时候使用 STORED AS 参数指定:
CREATE TABLE page_view(viewTime INT, userid BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
各个存储文件类型指定方式如下:
- STORED AS TEXTFILE
- STORED AS SEQUENCEFILE
- STORED AS ORC
- STORED AS PARQUET
- STORED AS AVRO
- STORED AS RCFILE
【基础】Hive 中的内部表和外部表有什么区别?
要点
内部表又叫做管理表 (Managed/Internal Table),创建表时不做任何指定,默认创建的就是内部表。想要创建外部表 (External Table),则需要使用 External 进行修饰。 内部表和外部表主要区别如下:
| 内部表 | 外部表 | |
|---|---|---|
| 数据存储位置 | 内部表数据存储的位置由 hive.metastore.warehouse.dir 参数指定,默认情况下表的数据存储在 HDFS 的 /user/hive/warehouse/数据库名。db/表名/ 目录下 | 外部表数据的存储位置创建表时由 Location 参数指定; |
| 导入数据 | 在导入数据到内部表,内部表将数据移动到自己的数据仓库目录下,数据的生命周期由 Hive 来进行管理 | 外部表不会将数据移动到自己的数据仓库目录下,只是在元数据中存储了数据的位置 |
| 删除表 | 删除元数据(metadata)和文件 | 只删除元数据(metadata) |
【基础】什么是分区表?
要点
Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。
分区为 HDFS 上表目录的子目录,数据按照分区存储在子目录中。如果查询的 where 子句中包含分区条件,则直接从该分区去查找,而不是扫描整个表目录,合理的分区设计可以极大提高查询速度和性能。
分区表并非 Hive 独有的概念,实际上这个概念非常常见。通常,在管理大规模数据集的时候都需要进行分区,比如将日志文件按天进行分区,从而保证数据细粒度的划分,使得查询性能得到提升。比如,在我们常用的 Oracle 数据库中,当表中的数据量不断增大,查询数据的速度就会下降,这时也可以对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据存放到多个表空间(物理文件上),这样查询数据时,就不必要每次都扫描整张表,从而提升查询性能。
在 Hive 中可以使用 PARTITIONED BY 子句创建分区表。表可以包含一个或多个分区列,程序会为分区列中的每个不同值组合创建单独的数据目录。下面的我们创建一张雇员表作为测试:
CREATE EXTERNAL TABLE emp_partition(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_partition';
加载数据到分区表时候必须要指定数据所处的分区:
# 加载部门编号为 20 的数据到表中
LOAD DATA LOCAL INPATH "/usr/file/emp20.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=20)
# 加载部门编号为 30 的数据到表中
LOAD DATA LOCAL INPATH "/usr/file/emp30.txt" OVERWRITE INTO TABLE emp_partition PARTITION (deptno=30)
这时候我们直接查看表目录,可以看到表目录下存在两个子目录,分别是 deptno=20 和 deptno=30, 这就是分区目录,分区目录下才是我们加载的数据文件。
# hadoop fs -ls hdfs://hadoop001:8020/hive/emp_partition/
这时候当你的查询语句的 where 包含 deptno=20,则就去对应的分区目录下进行查找,而不用扫描全表。
【基础】什么是分桶表?
要点
分区提供了一个隔离数据和优化查询的可行方案,但是并非所有的数据集都可以形成合理的分区,分区的数量也不是越多越好,过多的分区条件可能会导致很多分区上没有数据。同时 Hive 会限制动态分区可以创建的最大分区数,用来避免过多分区文件对文件系统产生负担。鉴于以上原因,Hive 还提供了一种更加细粒度的数据拆分方案:分桶表 (bucket Table)。
分桶表会将指定列的值进行哈希散列,并对 bucket(桶数量)取余,然后存储到对应的 bucket(桶)中。
单从概念上理解分桶表可能会比较晦涩,其实和分区一样,分桶这个概念同样不是 Hive 独有的,对于 Java 开发人员而言,这可能是一个每天都会用到的概念,因为 Hive 中的分桶概念和 Java 数据结构中的 HashMap 的分桶概念是一致的。
当调用 HashMap 的 put() 方法存储数据时,程序会先对 key 值调用 hashCode() 方法计算出 hashcode,然后对数组长度取模计算出 index,最后将数据存储在数组 index 位置的链表上,链表达到一定阈值后会转换为红黑树 (JDK1.8+)。下图为 HashMap 的数据结构图:
图片引用自:HashMap vs. Hashtable
在 Hive 中,我们可以通过 CLUSTERED BY 指定分桶列,并通过 SORTED BY 指定桶中数据的排序参考列。下面为分桶表建表语句示例:
CREATE EXTERNAL TABLE emp_bucket(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS --按照员工编号散列到四个 bucket 中
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_bucket';
这里直接使用 Load 语句向分桶表加载数据,数据时可以加载成功的,但是数据并不会分桶。
这是由于分桶的实质是对指定字段做了 hash 散列然后存放到对应文件中,这意味着向分桶表中插入数据是必然要通过 MapReduce,且 Reducer 的数量必须等于分桶的数量。由于以上原因,分桶表的数据通常只能使用 CTAS(CREATE TABLE AS SELECT) 方式插入,因为 CTAS 操作会触发 MapReduce。加载数据步骤如下:
(1)设置强制分桶
set hive.enforce.bucketing = true; --Hive 2.x 不需要这一步
在 Hive 0.x and 1.x 版本,必须使用设置 hive.enforce.bucketing = true,表示强制分桶,允许程序根据表结构自动选择正确数量的 Reducer 和 cluster by column 来进行分桶。
(2)CTAS 导入数据
INSERT INTO TABLE emp_bucket SELECT * FROM emp; --这里的 emp 表就是一张普通的雇员表
可以从执行日志看到 CTAS 触发 MapReduce 操作,且 Reducer 数量和建表时候指定 bucket 数量一致:
查看分桶文件
bucket(桶) 本质上就是表目录下的具体文件:
【基础】分区和分桶可以一起使用吗?
要点
分区表和分桶表的本质都是将数据按照不同粒度进行拆分,从而使得在查询时候不必扫描全表,只需要扫描对应的分区或分桶,从而提升查询效率。两者可以结合起来使用,从而保证表数据在不同粒度上都能得到合理的拆分。下面是 Hive 官方给出的示例:
CREATE TABLE page_view_bucketed(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING )
PARTITIONED BY(dt STRING)
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
此时导入数据时需要指定分区:
INSERT OVERWRITE page_view_bucketed
PARTITION (dt='2009-02-25')
SELECT * FROM page_view WHERE dt='2009-02-25';
Hive 索引
【中级】Hive 的索引是如何工作的?
要点
Hive 在 0.7.0 引入了索引的功能,索引的设计目标是提高表某些列的查询速度。如果没有索引,带有谓词的查询(如'WHERE table1.column = 10')会加载整个表或分区并处理所有行。但是如果 column 存在索引,则只需要加载和处理文件的一部分。
在指定列上建立索引,会产生一张索引表(表结构如下),里面的字段包括:索引列的值、该值对应的 HDFS 文件路径、该值在文件中的偏移量。在查询涉及到索引字段时,首先到索引表查找索引列值对应的 HDFS 文件路径及偏移量,这样就避免了全表扫描。
+--------------+----------------+----------+--+
| col_name | data_type | comment |
+--------------+----------------+----------+--+
| empno | int | 建立索引的列 |
| _bucketname | string | HDFS 文件路径 |
| _offsets | array<bigint> | 偏移量 |
+--------------+----------------+----------+--+
创建索引:
CREATE INDEX index_name --索引名称
ON TABLE base_table_name (col_name, ...) --建立索引的列
AS index_type --索引类型
[WITH DEFERRED REBUILD] --重建索引
[IDXPROPERTIES (property_name=property_value, ...)] --索引额外属性
[IN TABLE index_table_name] --索引表的名字
[
[ ROW FORMAT ...] STORED AS ...
| STORED BY ...
] --索引表行分隔符 、 存储格式
[LOCATION hdfs_path] --索引表存储位置
[TBLPROPERTIES (...)] --索引表表属性
[COMMENT "index comment"]; --索引注释
查看索引:
--显示表上所有列的索引
SHOW FORMATTED INDEX ON table_name;
删除索引:
删除索引会删除对应的索引表。
DROP INDEX [IF EXISTS] index_name ON table_name;
如果存在索引的表被删除了,其对应的索引和索引表都会被删除。如果被索引表的某个分区被删除了,那么分区对应的分区索引也会被删除。
重建索引:
ALTER INDEX index_name ON table_name [PARTITION partition_spec] REBUILD;
重建索引。如果指定了 PARTITION,则仅重建该分区的索引。
【中级】Hive 索引有什么缺陷?
要点
索引表最主要的一个缺陷在于:索引表无法自动 rebuild,这也就意味着如果表中有数据新增或删除,则必须手动 rebuild,重新执行 MapReduce 作业,生成索引表数据。
同时按照 官方文档 的说明,Hive 会从 3.0 开始移除索引功能,主要基于以下两个原因:
- 具有自动重写的物化视图 (Materialized View) 可以产生与索引相似的效果(Hive 2.3.0 增加了对物化视图的支持,在 3.0 之后正式引入)。
- 使用列式存储文件格式(Parquet,ORC)进行存储时,这些格式支持选择性扫描,可以跳过不需要的文件或块。
ORC 内置的索引功能可以参阅这篇文章:Hive 性能优化之 ORC 索引–Row Group Index vs Bloom Filter Index
Hive 架构
【高级】Hive SQL 如何执行的?
要点
Hive 在执行一条 HQL 的时候,会经过以下步骤:
- 语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象 语法树 AST Tree;
- 语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
- 生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
- 优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle 数据量;
- 生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
- 优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
关于 Hive SQL 的详细执行流程可以参考美团技术团队的文章:Hive SQL 的编译过程
参考资料
- [Hive 简介及核心概念](https://github.com/heibaiying/BigData-Notes/blob/master/notes/Hive 简介及核心概念。md)