Java 并发面试二
Java 并发面试二
Java 锁
【中等】Java 中,根据不同维度划分,锁有哪些分类?
在 Java 中,锁可以按照 多个维度 进行分类,不同维度的锁适用于不同的并发场景。以下是详细的分类:
按锁的公平性划分
| 锁类型 | 特点 | 实现类/关键字 |
|---|---|---|
| 公平锁 | 严格按照线程请求顺序(FIFO)分配锁,避免线程饥饿,但性能较低。 | ReentrantLock(true) |
| 非公平锁 | 允许插队,新请求的线程可能直接抢到锁,吞吐量高,但可能导致线程饥饿(默认方式)。 | ReentrantLock(false)、synchronized |
按锁的获取方式划分
| 锁类型 | 特点 | 实现类/关键字 |
|---|---|---|
| 悲观锁 | 认为并发冲突必然发生,先加锁再操作(阻塞其他线程)。 | synchronized、ReentrantLock |
| 乐观锁 | 认为并发冲突较少,不加锁,更新时检查(CAS 或版本号机制)。 | AtomicInteger、StampedLock |
按锁的可重入性划分
| 锁类型 | 特点 | 实现类/关键字 |
|---|---|---|
| 可重入锁 | 同一线程可多次获取同一把锁(避免死锁)。 | ReentrantLock、synchronized |
| 不可重入锁 | 同一线程重复获取同一把锁会导致死锁(Java 无原生实现,需自定义)。 | 无(需自行实现) |
按锁的共享性划分
| 锁类型 | 特点 | 实现类/关键字 |
|---|---|---|
| 独占锁(排他锁) | 同一时间只有一个线程能持有锁(如 synchronized、ReentrantLock)。 | synchronized、ReentrantLock |
| 共享锁 | 允许多个线程同时读取,但写入时独占(如 ReadWriteLock)。 | ReentrantReadWriteLock |
按锁的阻塞方式划分
| 锁类型 | 特点 | 实现类/关键字 |
|---|---|---|
| 阻塞锁 | 获取不到锁时,线程进入阻塞状态(如 synchronized)。 | synchronized、ReentrantLock |
| 自旋锁 | 获取不到锁时,线程循环尝试(避免线程切换,但消耗 CPU)。 | AtomicInteger(CAS 自旋) |
| 适应性自旋锁 | JVM 自动优化自旋次数(如 synchronized 在 JDK 6+ 的优化)。 | JVM 内部优化 |
按锁的优化策略划分
| 锁类型 | 特点 | 实现类/关键字 |
|---|---|---|
| 偏向锁 | 单线程访问时无同步开销(JDK 6+ 对 synchronized 的优化)。 | JVM 自动优化(synchronized) |
| 轻量级锁 | 多线程无竞争时,使用 CAS 代替阻塞(JDK 6+ 优化)。 | JVM 自动优化(synchronized) |
| 重量级锁 | 真正的互斥锁,涉及 OS 线程阻塞(如 synchronized 竞争激烈时)。 | JVM 自动升级(synchronized) |
按锁的实现方式划分
| 锁类型 | 特点 | 实现类/关键字 |
|---|---|---|
| 内置锁(JVM 锁) | 由 JVM 实现(如 synchronized)。 | synchronized |
| 显式锁 | 由 Java API 提供(如 ReentrantLock)。 | ReentrantLock、ReadWriteLock |
| 分布式锁 | 跨 JVM 的锁(如 Redis、ZooKeeper 实现)。 | Redisson、Curator |
总结
| 分类维度 | 锁类型 |
|---|---|
| 公平性 | 公平锁、非公平锁 |
| 获取方式 | 悲观锁、乐观锁 |
| 可重入性 | 可重入锁、不可重入锁 |
| 共享性 | 独占锁、共享锁 |
| 阻塞方式 | 阻塞锁、自旋锁、适应性自旋锁 |
| 优化策略 | 偏向锁、轻量级锁、重量级锁 |
| 实现方式 | 内置锁(synchronized)、显式锁(ReentrantLock)、分布式锁(Redisson) |
选择合适的锁取决于:
- 并发竞争程度(高竞争→悲观锁,低竞争→乐观锁)
- 任务执行时间(长任务→公平锁,短任务→非公平锁)
- 读写比例(读多→共享锁,写多→独占锁)
- 是否需要跨 JVM(是→分布式锁)
这些分类帮助开发者根据业务场景选择最优的锁策略,平衡 性能、公平性、一致性。
【中等】悲观锁和乐观锁有什么区别?
悲观锁假定会冲突,提前加锁阻塞;乐观锁假定不冲突,提交时检测版本,冲突则重试。
- 悲观锁:先加锁再操作,适合写多读少的高并发场景,保证安全但性能较低,如金融交易。
- 乐观锁:通过版本号或 CAS 机制实现,提交时检查数据是否被修改,适合读多写少的场景,如电商库存。
以下是悲观锁与乐观锁的详细对比:
| 对比维度 | 悲观锁 | 乐观锁 |
|---|---|---|
| 核心思想 | 假定并发冲突必然发生,先加锁再访问数据 | 假定并发冲突较少,先操作再检测冲突 |
| 锁机制 | 显式加锁(阻塞其他线程) | 无锁机制(依赖 CAS 或版本号控制) |
| 实现方式 | synchronized、ReentrantLock、数据库SELECT FOR UPDATE | Atomic类(CAS)、版本号机制、数据库乐观锁(如 MVCC) |
| 线程阻塞 | 会阻塞竞争线程(线程挂起) | 不阻塞线程,但可能自旋重试或失败 |
| 数据一致性 | 强一致性(独占访问) | 最终一致性(可能需重试) |
| 适用场景 | - 写操作频繁 - 临界区代码执行时间长 - 强一致性要求高 | - 读多写少 - 短平快操作 - 高吞吐量需求 |
| 性能特点 | - 高竞争时性能下降明显(线程切换开销) - 低竞争时仍有固定锁开销 | - 低竞争时性能极佳(无阻塞) - 高竞争时 CPU 自旋浪费 |
| 冲突处理 | 通过锁排队避免冲突 | 通过重试或放弃处理冲突 |
| 典型应用 | - 银行转账 - 订单支付 - 数据库行级锁 | - 库存扣减 - 计数器 - 点赞系统 |
| 优缺点 | ✔️ 强一致性 ❌ 吞吐量低、死锁风险 | ✔️ 高并发性能好 ❌ 实现复杂、可能 ABA 问题 |
【中等】公平锁和非公平锁有什么区别?
公平锁按请求顺序分配,非公平锁允许插队,可能让先到的线程等待。
- 公平锁:线程获取锁的顺序严格遵循请求的先后顺序,保证公平性但可能降低吞吐量。
- 非公平锁:允许后请求的线程“插队”抢先获取锁,虽可能造成饥饿但通常能提高系统整体性能。
公平锁和非公平锁的详细对比:
| 对比维度 | 公平锁 (Fair Lock) | 非公平锁 (Nonfair Lock) |
|---|---|---|
| 锁获取顺序 | 严格按照线程请求顺序(FIFO)分配锁 | 允许插队,新请求的线程可能直接抢到锁 |
| 性能表现 | 吞吐量较低(上下文切换频繁) | 吞吐量较高(减少线程切换,但可能线程饥饿) |
| 响应时间 | 等待时间稳定(适合长任务) | 短任务可能更快获取锁(适合高并发短任务) |
| 适用场景 | - 需要严格公平性 - 线程执行时间差异大(避免饥饿) | - 高并发短任务 - 追求吞吐量 |
| 锁实现类 | ReentrantLock(true) | ReentrantLock(false)(默认) |
| 实现 | 依赖 AQS 维护等待线程,先到先得 | 先尝试 CAS 抢锁,失败后进入 AQS 队列 |
| 线程饥饿 | 不会发生 | 可能发生(高并发时某些线程长期无法获取锁) |
| 操作系统调度影响 | 依赖系统线程调度,可能因优先级反转影响公平性 | 更依赖 JVM 的锁优化策略 |
| 锁重入性 | 支持(与公平性无关) | 支持(与公平性无关) |
| 适用并发模型 | 适合任务执行时间不均衡的场景 | 适合任务执行时间短的场景 |
如何选择?
选公平锁:
- 需要严格顺序执行(如订单处理)
- 避免低优先级线程饥饿
- 线程任务执行时间差异大
选非公平锁:
- 追求高吞吐量(如秒杀系统)
- 任务执行时间短且均匀
- 能接受偶尔的线程饥饿
注意事项:
- 默认行为:
ReentrantLock和synchronized默认都是非公平锁(因为性能更好)。 - 性能差异:非公平锁在高并发下吞吐量可提升 10%~30%,但可能增加延迟方差。
- synchronized 的公平性:Java 的
synchronized不支持公平锁,仅ReentrantLock可配置。
【困难】AQS 的实现原理是什么?⭐⭐⭐
AQS(AbstractQueuedSynchronizer)是 Java 并发包(java.util.concurrent.locks)的核心框架,用于构建锁(如 ReentrantLock)和同步器(如 CountDownLatch、Semaphore)。
AQS 用一个 volatile int 状态值 + 一个双向链表队列(CLH),通过 CAS 自旋实现线程的排队与唤醒,是 Java 并发锁的“骨架引擎”。
AQS 要点
AQS 原理可归纳为:2 种模式,3 大核心,4 步操作
2 种模式
- 独占模式(Exclusive):同一时刻只有一个线程能获取资源(如
ReentrantLock)。 - 共享模式(Shared):多个线程可同时获取资源(如
Semaphore,CountDownLatch)。
3 大核心
- 状态(State):一个
volatile整型变量,用于表示同步状态。state在不同的同步组件中意义不同。- 锁的意义:0 代表无锁,>0 代表有锁(可重入时累加)。例如在
ReentrantLock里,state为 0 表示锁未被持有,大于 0 表示锁已被持有,且重入次数就是state的值。 - 信号量/CountDownLatch 等意义:state 表示可用资源数或倒数计数。
- 锁的意义:0 代表无锁,>0 代表有锁(可重入时累加)。例如在
- 同步队列(CLH 变体):一个双链表,存放等待获取资源的线程。
Node包含以下重要属性:thread:指向等待获取同步状态的线程。prev和next:分别指向前一个节点和后一个节点,从而形成双向链表。waitStatus:表示节点的等待状态,常见的状态有:CANCELLED(1):表示该节点对应的线程已取消等待。SIGNAL(-1):表示该节点的后继节点需要被唤醒。CONDITION(-2):表示该节点处于条件队列中。PROPAGATE(-3):用于共享模式下,表明状态需要向后传播。
- 每个线程被封装为一个 Node 节点。
- 队列头节点(head)是当前持有资源的线程(独占模式)或已唤醒的节点。
- CAS 操作:所有对
state和队列头的修改,都通过Unsafe.compareAndSwap原子完成,保证线程安全。
4 步关键操作
可以把一个线程获取锁到释放锁的过程,想象成**“尝试加锁 → 排队等候 → 被唤醒 → 解锁”**的流程。
线程请求资源
│
▼
state=0? ──Y──> CAS 获取资源(成功)
│ │
N ▼
│ 执行、占有资源
▼ │
加入 CLH 队列尾部 ◄─── 失败 │
│ ▼
自旋/检查/挂起 释放资源 (state=0)
(等待被前驱唤醒) │
│ ▼
└──────────► 唤醒后继节点AQS 独占模式工作流程
独占模式:同一时刻仅允许一个线程获取同步状态,例如 ReentrantLock。
- tryAcquire:线程尝试直接获取锁(CAS 修改 state)。
- 成功:拿到锁,设置自己为独占线程。
- 失败:进入第 2 步。
- addWaiter:将当前线程包装成 Node 节点,用 CAS 快速插入到同步队列尾部。
- acquireQueued:在队列中进入“自旋-检测-挂起”循环。
- 检查自己是不是第二个节点(即 head 的下一个),如果是则再次尝试获取锁(tryAcquire)。
- 如果获取失败,则根据前驱节点的状态,决定是否将自己挂起(
LockSupport.park)。
- release & unparkSuccessor:持有锁的线程释放锁时。
tryRelease:修改 state。- 唤醒(
LockSupport.unpark)队列中下一个等待的节点(后继节点),让它重新尝试获取锁。
AQS 共享模式工作流程
共享模式:同一时刻允许多个线程获取同步状态,例如 CountDownLatch 和 Semaphore。
- 获取锁:
- 线程调用
acquireShared(int)→tryAcquireShared(int)(子类实现)。 - 如果成功(返回
≥0),获取锁;否则进入队列等待。
- 线程调用
- 释放锁:
- 线程调用
releaseShared(int)→tryReleaseShared(int)(子类实现)。 - 如果成功,唤醒后续等待的线程(可能多个)。
- 线程调用
AQS 关键方法
AQS 的关键方法采用模板方法设计模式串联起来:
- 独占模式
tryAcquire(int arg):尝试以独占模式获取同步状态,此方法需由子类实现。acquire(int arg):以独占模式获取同步状态,若获取失败则将线程加入队列并阻塞。tryRelease(int arg):尝试以独占模式释放同步状态,需子类实现。release(int arg):以独占模式释放同步状态,若释放成功则唤醒队列中的后继节点。
- 共享模式
tryAcquireShared(int arg):尝试以共享模式获取同步状态,需子类实现。acquireShared(int arg):以共享模式获取同步状态,若获取失败则将线程加入队列并阻塞。tryReleaseShared(int arg):尝试以共享模式释放同步状态,需子类实现。releaseShared(int arg):以共享模式释放同步状态,若释放成功则唤醒队列中的后继节点。
【中等】synchronized 和 ReentrantLock 有什么区别?⭐⭐⭐
ReentrantLock更强大:支持公平锁、可中断、超时、多条件变量。ReentrantLock必须手动释放锁,否则会导致死锁!synchronized更简单:自动管理锁,适合基础同步需求。- 性能差异:JDK 6 后,synchronized 经过一系列优化,两者性能接近,但
ReentrantLock在高竞争场景仍略有优势。
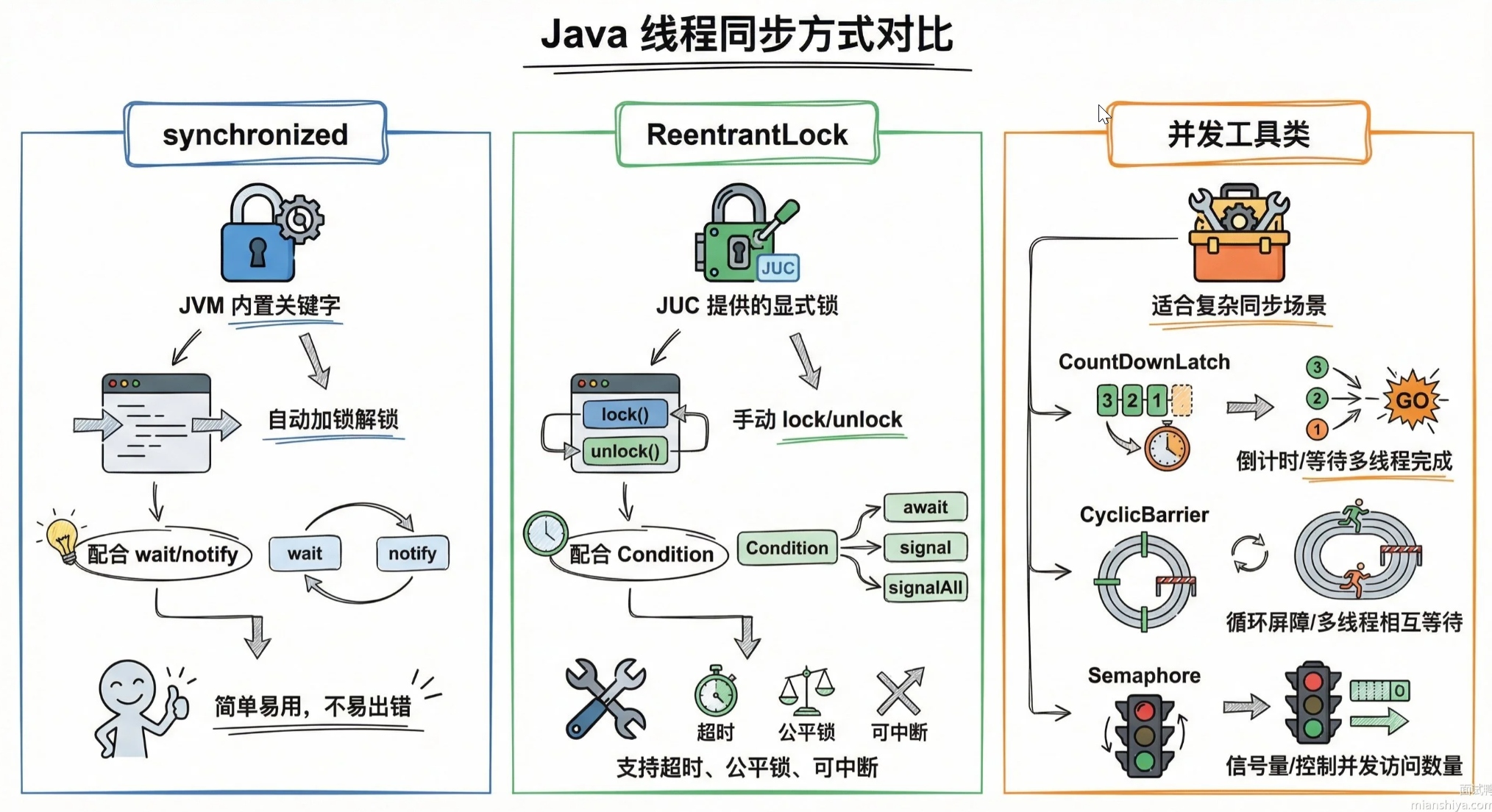
synchronized 和 ReentrantLock 详细对比
以下是 synchronized 和 ReentrantLock 的详细对比表格,涵盖 锁机制、功能、性能、使用场景 等核心维度:
| 对比维度 | synchronized | ReentrantLock |
|---|---|---|
| 锁类型 | JVM 内置关键字(隐式锁) | JDK 提供的类(显式锁) |
| 加锁解锁方式 | 自动加锁/释放锁(进入同步代码块加锁,退出时释放) | 需手动调用 lock() 和 unlock()(必须配合 try-finally 使用) |
| 是否可重入 | 支持(同一线程可重复获取) | 支持(同一线程可重复获取) |
| 是否支持公平 | 仅支持非公平锁 | 可配置公平锁或非公平锁(构造函数传参 true/false) |
| 是否可中断 | 不支持中断 | 支持 lockInterruptibly(),可响应中断 |
| 是否支持超时 | 不支持超时 | 支持 tryLock(timeout, unit),可设置超时时间 |
| 是否支持多条件 | 通过 wait()/notify() 实现,单一等待队列 | 支持多个 Condition,可精确控制线程唤醒(如 await()/signal()) |
| 性能 | JDK 6+ 优化后(偏向锁→轻量级锁→重量级锁)性能接近 ReentrantLock | 在高竞争场景下性能略优(减少上下文切换) |
| 死锁检测 | 无内置死锁检测 | 可通过 tryLock 避免死锁 |
| 适用场景 | 简单同步场景(如单方法同步) | 复杂同步需求(如公平锁、可中断锁、超时锁) |
| 底层实现 | JVM 通过 monitorenter/monitorexit 字节码实现 | 基于 AbstractQueuedSynchronizer (AQS) 实现 |
synchronized 和 ReentrantLock 的使用差异
// 1. 用于代码块
synchronized (this) {}
// 2. 用于对象
synchronized (object) {}
// 3. 用于方法
public synchronized void test () {}
// 4. 可重入
for (int i = 0; i < 100; i++) {
synchronized (this) {}
}public void test () throw Exception {
// 1. 初始化选择公平锁、非公平锁
ReentrantLock lock = new ReentrantLock(true);
// 2. 可用于代码块
lock.lock();
try {
try {
// 3. 支持多种加锁方式,比较灵活;具有可重入特性
if(lock.tryLock(100, TimeUnit.MILLISECONDS)){ }
} finally {
// 4. 手动释放锁
lock.unlock()
}
} finally {
lock.unlock();
}
}synchronized 和 ReentrantLock 的适用场景
synchronized适用场景:单例模式的双重检查锁、简单的线程安全计数器。ReentrantLock适用场景:- 需要公平性的任务队列(如订单处理)。
- 需要超时控制的资源争用(如避免死锁)。
- 复杂的多条件线程协调(如生产者-消费者模型)。
使用选择建议
- 选择
synchronized:- 需要简单的代码块同步。
- 不需要高级功能(如超时、公平锁)。
- 选择
ReentrantLock:- 需要精细控制(如公平性、可中断)。
- 需要避免死锁(
tryLock)。
【困难】ReentrantLock 的实现原理是什么?⭐⭐⭐
本质上,ReentrantLock 是 AQS 在独占模式下的一个经典实现。
ReentrantLock 以 AQS 的 state 和同步队列为基础,通过 NonfairSync / FairSync 实现(非)公平策略,并内置可重入计数和条件队列机制的互斥锁实现。
- 核心依赖:
ReentrantLock通过内部类Sync(继承AQS)实现锁机制。 - AQS 作用:提供线程阻塞/唤醒的队列管理(CLH 变体)和状态(
state)的原子操作。
两种模式
ReentrantLock 内部有两个主要的静态内部类,决定了其抢占行为:
NonfairSync(非公平锁,默认):允许插队- 新线程来了直接尝试 CAS 抢锁(插队),抢不到才排队。
- 优点:吞吐量高。
- 缺点:可能导致饥饿问题。
FairSync(公平锁):先到先得- 新线程来了先检查同步队列是否为空,有排队者则直接去队尾排队。
- 优点:公平,无饥饿问题。
- 缺点:上下文切换多,吞吐量相对低。
二者核心区别就在 lock() 方法中,尝试获取锁前是否检查同步队列中有等待者(hasQueuedPredecessors())。
三大核心
ReentrantLock
│
├── Sync (extends AQS)
│ ├── state (锁计数器)
│ ├── exclusiveOwnerThread (当前持有线程)
│ └── CLH Queue (等待锁的线程队列)
│
├── NonfairSync (默认,插队抢锁)
├── FairSync (先来后到)
│
└── ConditionObject
└── Condition Queue (等待特定条件的线程队列)- AQS 同步器(Sync):继承自 AQS。
- 状态 (
state):volatile int,表示锁被持有的次数。0=空闲,N=被同一个线程重入了N次。 - 同步队列:存储等待线程的 CLH 变体队列。
- 独占线程:记录当前持有锁的线程 (
exclusiveOwnerThread)。
- 状态 (
- 可重入机制:
- 加锁:若当前线程是持有者,则
state加 1(无需 CAS)。 - 解锁:
state减 1,减到 0 时才完全释放,唤醒后继节点。
- 加锁:若当前线程是持有者,则
- 条件变量 (
ConditionObject):- 每个
Condition对象内部维护一个 独立的等待队列。 await()将当前线程从锁的同步队列移到条件等待队列,并释放锁。signal()将条件等待队列的头节点移到锁的同步队列中,重新等待获取锁。
- 每个
关键步骤
🔒 加锁四步曲
- 快速抢票:新线程直接 CAS 尝试将
state从 0 改为 1(插队)。 - 抢到则坐:成功则设置自己为独占线程,进入临界区。
- 没抢则排:失败则调用 AQS 的
acquire(1),进入同步队列队尾。 - 队列中等:在队列中进入“自旋-检查-挂起”循环,等待被前驱节点唤醒。
🔓 解锁两步曲(unlock() 本质是两个关键操作)
- 尝试释放:调用
tryRelease(1),将state减 1。如果state减到 0,则清空独占线程标记。 - 唤醒后继:如果锁完全释放(
state == 0),则唤醒同步队列中下一个符合条件的等待线程。
【困难】ReentrantReadWriteLock 的实现原理是什么?⭐⭐
ReentrantReadWriteLock 的特性
ReentrantReadWriteLock 是为【读多写少】的并发场景设计的锁实现。
ReentrantReadWriteLock 允许多个线程同时持有读锁,但同一时刻只允许一个线程持有写锁。此外,存在读锁时无法获取写锁,存在写锁时无法获取读锁。
ReentrantReadWriteLock 有以下特性:
- 可重入:读写锁都支持可重入。
- 支持公平锁,默认为非公平锁。
- 支持锁降级:持有写锁可以获取读锁;反之不允许。
ReentrantReadWriteLock 的核心设计
ReentrantReadWriteLock 基于 AQS 实现的读写锁。
ReentrantReadWriteLock 的核心设计思想是将一个 32 位的 int 状态变量拆分为两部分:state = (readCount << 16) | writeCount
虽然提供了两个锁对象(readLock, writeLock),但底层共享同一个 AQS 同步器。
| 视角 | 读锁 (ReadLock) | 写锁 (WriteLock) |
|---|---|---|
| 行为 | 共享锁 | 独占锁 |
| 占用 state | 高 16 位 | 低 16 位 |
| 互斥规则 | 与写锁互斥 | 与所有锁(读、写)互斥 |
| 重入计数 | 所有读线程的总重入次数 | 单个写线程的重入次数 |
| 条件变量 | 不支持 Condition | 支持 Condition |
ReentrantReadWriteLock 写锁实现(WriteLock)
ReentrantReadWriteLock 写锁基于 AQS 的独占模式实现。
写锁获取步骤:
- 线程申请写锁(
writeLock.lock()) - 检查有没有读锁或写锁(
state != 0) - 没有,CAS 设置 state 的低 16 为 1(获得写锁)
- 有,当前线程是否已持有写锁(可重入)
- 是:CAS 将 state 的低 16 加 1(获得写锁)
- 否:排队等待(进入 AQS 同步队列挂起)
实现方法:
protected final boolean tryAcquire(int acquires) {
// 检查是否有读锁或其他线程持有写锁
if (c != 0 && w == 0) return false;
// 检查重入或 CAS 设置状态
// ...
}ReentrantReadWriteLock 读锁实现(ReadLock)
ReentrantReadWriteLock 读锁基于 AQS 的共享模式实现。
- 线程申请读锁(
readLock.lock()) - 检查有没有写锁(
(state & 0xFFFF) != 0) - 没有,CAS 将 state 的高 16 加 1(获得读锁)
- 有,排队等待(进入 AQS 同步队列挂起)
ReentrantReadWriteLock 锁降级实现
- 线程持有写锁
- 直接申请读锁:因为线程有写锁,因此一定成功(高 16 位加 1)
- 释放写锁
- 锁状态从 “独占写” 降级为 “共享读”。
// 锁降级示例代码
writeLock.lock(); // 获取写锁
try {
// 修改数据。..
readLock.lock(); // 在保持写锁的情况下获取读锁(锁降级关键步骤)
} finally {
writeLock.unlock(); // 释放写锁,降级为读锁
}
// 此时仍持有读锁,其他线程可以获取读锁但不能获取写锁性能优化技巧
- firstReader 优化:记录第一个获取读锁的线程,避免 ThreadLocal 查找
- cachedHoldCounter:缓存最近一个获取读锁的线程计数器
- 读锁计数存储:使用 ThreadLocal 保存每个线程的重入次数,避免竞争
【困难】StampedLock 的实现原理是什么?⭐
StampedLock是 JDK8 引入的高性能锁,适合读多写少且追求极致吞吐的场景,但需谨慎处理乐观读失败和死锁风险。
StampedLock 是 通过一个 64 位 long 值同时编码版本号、读计数和写标记,并利用戳记(Stamp)实现乐观读、锁升级等高级并发控制,在牺牲部分易用性和重入性的前提下,提供极高读性能的同步器。
StampedLock 三种模式
StampedLock 的状态存储在一个 long 型(64 位)变量中,分为三个逻辑部分:
| 模式 | 占用位 | 作用 |
|---|---|---|
| 读锁 | 低 7 位 | 读线程计数(实际是readerCount+1) |
| 写锁 | 第 8 位 | 独占标记,0 未占用,1 已占用 |
| 版本号 | 未使用的高位 | 加锁返回有效戳,解锁需验证戳; 戳无效 = 状态变更(有写操作),戳有效 = 数据一致 |
状态流转:
初始状态:state = (version: 0, readCount: 0, write: 0)
[操作与状态变化示例]
1. 写锁获取 (`writeLock()`)
-> state 低 8 位置 1,同时整个 long 值改变 (version++)
-> 返回 stamp W1
2. 乐观读 (`tryOptimisticRead()`)
-> 不修改 state!仅记录当前 state 值作为 stamp O1
-> 校验时:比较当前 state 是否等于 O1
3. 读锁获取 (`readLock()`)
-> 高 56 位读计数+1 (如果写锁未被占用)d
-> 返回 stamp R1
4. 锁升级 (`tryConvertToWriteLock(R1)`)
-> 原子操作:读计数-1,同时写标记置 1
-> 成功返回新 stamp W2,失败返回 0StampedLock 乐观锁
StampedLock 乐观锁是一种 “读时复制+版本校验” 的乐观并发控制。
乐观锁在读远多于写且写操作不频繁的场景下,性能极高(完全无锁)。
StampedLock 乐观锁流程
- 调用
tryOptimisticRead()获取一个戳记(Stamp),此时完全不阻塞。 - 读取共享数据到局部变量。
- 调用
validate(stamp)校验:自获取戳记以来,是否有写锁被获取过?- 无变化:数据有效,直接使用。
- 有变化:升级为悲观读锁,重新读取数据。
StampedLock 锁升级
读锁 → 写锁升级:tryConvertToWriteLock(stamp)
- 前提:当前线程已持有读锁(
stamp是有效的读锁戳记)。 - 过程:原子地尝试释放读计数,获取写锁标记。
- 结果:成功返回新写戳记,失败返回 0。
- 注意:可能死锁!如果当前还有其他读锁持有者,升级会失败(因为读写互斥)。
乐观读 → 写锁升级:
- 乐观读戳记本身不代表持有锁,升级失败是常态。
- 通常先获取悲观读锁,再进行升级尝试。
StampedLock vs. ReentrantReadWriteLock
| 特性 | StampedLock | ReentrantReadWriteLock |
|---|---|---|
| 读并发度 | 最高(乐观读无阻塞) | 高(悲观读阻塞写) |
| 写饥饿 | 可能发生 | 非公平模式下可能发生 |
| 锁重入 | 不支持 | 支持 |
| 公平性 | 仅非公平 | 支持公平/非公平 |
| 条件变量 | 不支持 | 支持 |
StampedLock 使用示例
StampedLock lock = new StampedLock();
// 乐观读示例
long stamp = lock.tryOptimisticRead();
// 读取共享数据。..
if (!lock.validate(stamp)) {
// 版本失效,转悲观读
stamp = lock.readLock();
try {
// 重新读取数据。..
} finally {
lock.unlockRead(stamp);
}
}
// 写锁示例
long stamp = lock.writeLock();
try {
// 修改数据。..
} finally {
lock.unlockWrite(stamp);
}Java 无锁
【中等】什么是 CAS?CAS 的实现原理是什么?⭐⭐⭐
什么是 CAS?
CAS 是 Compare-And-Swap(比较并交换) 的缩写,是实现并发编程的无锁原子操作核心。
CAS 核心规则是:先比较内存中某个值是否等于预期值,若相等则将其更新为新值;若不等则不操作,整个过程原子性完成。
CAS 操作伪代码
boolean CAS(Variable var, int expected, int newValue) {
if (var.value == expected) { // 比较当前值是否等于预期值
var.value = newValue; // 如果相等,更新为新值
return true;
}
return false; // 否则失败
}说明:
- 读取内存值
V。 - 比较
V和预期值A:- 如果
V == A,说明没有其他线程修改过,更新为B。 - 如果
V != A,说明值已被修改,放弃更新。
- 如果
- 返回操作是否成功。
CAS 特性
- 无锁:无需加 synchronized/Lock,减少线程阻塞 / 唤醒开销,性能更高;
- 原子性:CPU 指令级保证,比手动加锁更可靠;
- ABA 问题:V 先从 A 变 B 再变回 A,CAS 会误判为未修改(解决:加版本号,如
AtomicStampedReference)。
CAS 的实现原理是什么?
Java 层面,通过 Unsafe 类调用 native 方法(如 compareAndSwapInt())实现 CAS。
public final native boolean compareAndSwapInt(Object o, long offset, int expected, int newValue);更底层(CPU 层面),CAS 实现依赖于 CPU 提供的原子指令(如 x86 的 cmpxchg 指令)。
CAS 典型应用
(1)原子类
AtomicInteger atomicInt = new AtomicInteger(0);
atomicInt.incrementAndGet(); // CAS 实现原子自增底层实现:
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}(2)自旋锁
while (!CAS(lock, 0, 1)) { // 尝试获取锁
// 自旋等待
}(3)无锁数据结构
ConcurrentHashMap(JDK 8 使用 CAS +synchronized替代分段锁)。CopyOnWriteArrayList(CAS 保证写入原子性)。
【中等】CAS 算法存在哪些问题?⭐⭐⭐
CAS(Compare-And-Swap)是一种无锁并发编程技术,广泛用于 Java 的 Atomic 类、AQS、ConcurrentHashMap 等并发工具中。但它也存在一些问题和限制:
ABA 问题
问题描述:变量值从
A→B→A,CAS 检查时认为没有变化,但实际上已经被修改过。影响:可能导致数据不一致(如链表操作时节点被替换但指针仍有效)。
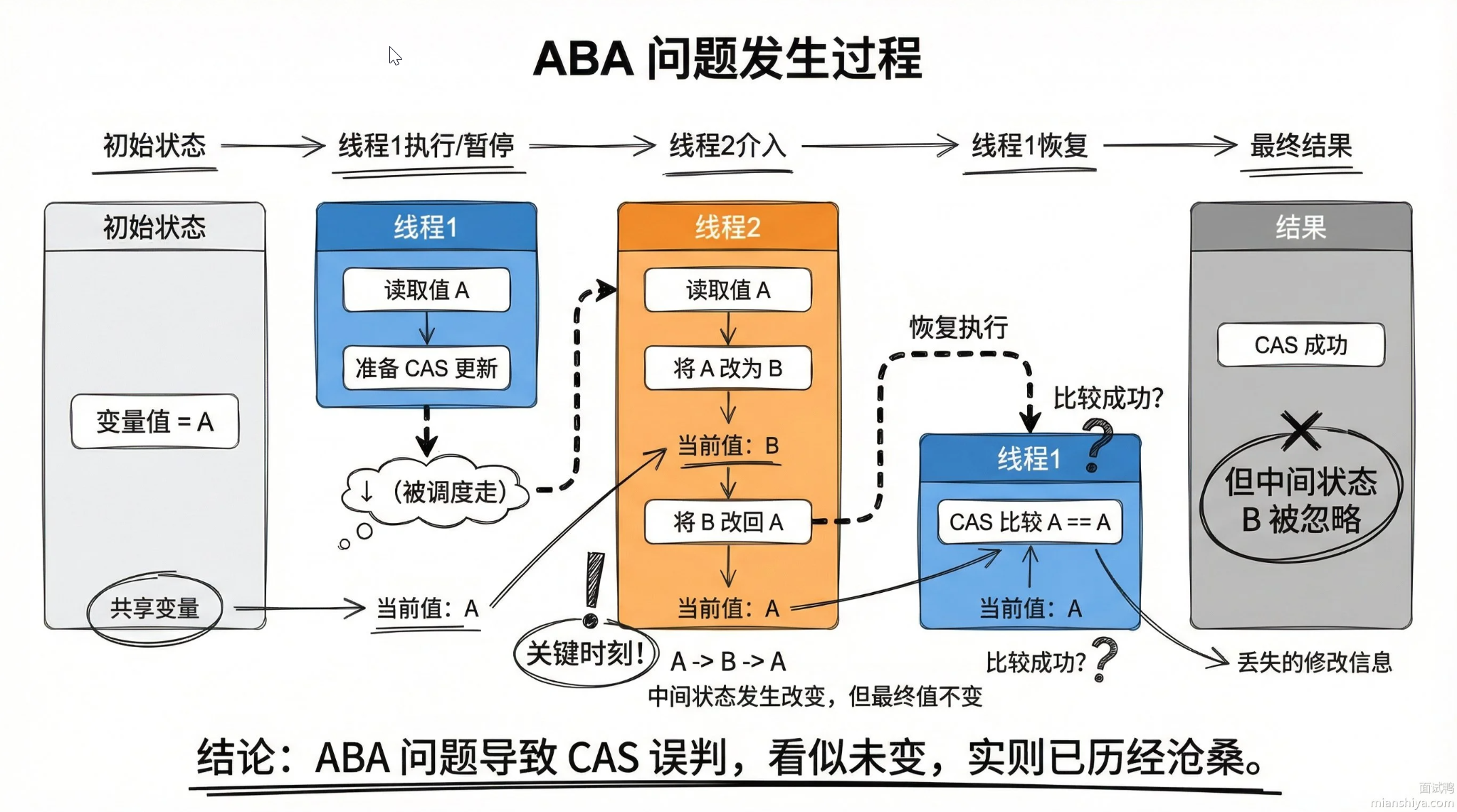
解决方案:
- 使用 版本号/时间戳(如
AtomicStampedReference)。 - 使用
boolean标记(如AtomicMarkableReference)。
- 使用 版本号/时间戳(如
自旋产生的 CPU 空转
- 问题描述:如果 CAS 长时间失败,线程会持续自旋(
while循环),占用 CPU 资源。 - 影响:高并发竞争时,可能导致 CPU 使用率飙升。
- 解决方案:
- 限制自旋次数(如
LongAdder改用分段 CAS)。 - 结合
yield()或Thread.sleep()减少竞争。
- 限制自旋次数(如
只能保证单个变量的原子性
- 问题描述:CAS 只能对一个变量进行原子操作,无法保证多个变量的复合操作(如
i++和j--)。 - 影响:需要额外同步机制(如锁)来保证多变量一致性。
- 解决方案:
- 使用
synchronized或ReentrantLock。 - 设计不可变对象(如
String、BigInteger)。
- 使用
公平性问题
- 问题描述:CAS 是非公平的,新线程可能比等待队列中的线程更快获取锁。
- 影响:可能导致线程饥饿(某些线程长期得不到执行)。
- 解决方案:
- 使用公平锁(如
ReentrantLock(true))。 - 结合队列调度(如 AQS 的 CLH 队列)。
- 使用公平锁(如
不适用于复杂操作
- 问题描述:CAS 适合简单操作(如
count++),但不适合复杂逻辑(如数据库事务)。 - 影响:需要拆分为多个 CAS 步骤,可能引入中间状态不一致。
- 解决方案:
- 使用锁(如
synchronized)。 - 改用事务内存(如 Clojure STM)。
- 使用锁(如
平台依赖性
- 问题描述:CAS 依赖底层 CPU 指令(如
CMPXCHG),不同架构性能可能差异较大。 - 影响:在 ARM 等弱内存模型平台可能出现意外行为。
- 解决方案:使用 JVM 内置原子类(如
AtomicInteger),而非手动实现。
总结
| 问题 | 影响 | 解决方案 |
|---|---|---|
| ABA 问题 | 数据不一致 | AtomicStampedReference |
| 自旋开销 | CPU 占用高 | 限制自旋次数 / 退让策略 |
| 单变量限制 | 复合操作不安全 | 锁 / 不可变对象 |
| 公平性 | 线程饥饿 | 公平锁 / 队列调度 |
| 复杂操作 | 难以实现 | 锁 / 事务内存 |
| 平台依赖 | 跨平台兼容性差 | 使用标准库 |
CAS 在无锁编程中非常高效,但需结合场景权衡利弊。在高竞争环境下,可能需要改用锁或其他并发策略。
【中等】Java 中支持哪些原子类?⭐
Java 原子类底层基于 CAS 指令(CPU 级原子操作)+ 自旋重试 实现无锁原子操作。部分高性能原子类(如 LongAdder)采用分段累加优化高并发性能。
原子类相当于一种泛化的 volatile 变量,能够支持原子的、有条件的读/改/写操作。
原子类分类
| 分类 | 核心类 | 作用 |
|---|---|---|
| 基本类型原子类 | AtomicInteger、AtomicLong、AtomicBoolean | 对 int / long / boolean 做原子增删改查,替代加锁 |
| 引用类型原子类 | AtomicReference、AtomicStampedReference、AtomicMarkableReference | 对引用类型做原子操作,解决 CAS 的 ABA 问题 |
| 数组类型原子类 | AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray | 对数组元素做原子操作(数组本身不原子,元素原子) |
| 字段更新器 | AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater | 对字段做原子更新,无需改字段类型 |
| 累加器 | LongAdder、DoubleAdder、LongAccumulator、DoubleAccumulator | 高并发下替代 AtomicLong/Double,分段累加提性能 适合统计,但不保证实时精确值 |
核心原子类
(1)基础类
| 类 | 核心特性 | 典型场景 |
|---|---|---|
| AtomicInteger | 支持 getAndIncrement(i++)、compareAndSet 等 | 计数器、序列号生成 |
| AtomicBoolean | 原子更新布尔值,底层用 int 存储(0/1) | 状态标记(如开关) |
| AtomicReference | 原子更新对象引用 | 原子替换对象实例 |
(2)解决 ABA 问题
| 类 | 核心特性 | 记忆点 |
|---|---|---|
| AtomicStampedReference | 加版本号(戳),CAS 时校验值 + 版本 | 彻底解决 ABA(版本唯一) |
| AtomicMarkableReference | 加标记位(boolean),CAS 校验值 + 标记 | 简化版 ABA 解决(仅标记是否修改) |
(3)高性能累加器
| 类 | 核心特性 | 记忆点 |
|---|---|---|
| LongAdder | 分段累加(base+cells 数组),低竞争用 base,高竞争分 cell | 高并发计数性能≈10 倍 AtomicLong |
| LongAccumulator | 自定义累加规则(如乘法、最大值),比 LongAdder 更灵活 | 支持非加减的原子计算 |
(4)灵活类
| 类 | 核心特性 | 记忆点 |
|---|---|---|
| AtomicIntegerFieldUpdater | 需通过静态方法创建,字段必须 volatile | 不改原有类结构,原子更新字段 |
| AtomicReferenceArray | 索引操作原子,数组长度不可变 | 原子更新数组元素 |
原子类选型
- 低并发计数(如普通计数器)→ 基本类型原子类(AtomicInteger 等)
- 高并发计数(如接口 QPS 统计)→ 累加器(LongAdder 等)
- 操作引用对象 + 防 ABA → 引用类型原子类(AtomicStampedReference 等)
- 操作对象的普通字段 → 字段更新器(AtomicIntegerFieldUpdater 等)
- 操作数组元素 → 数组类型原子类(AtomicIntegerArray 等)
【中等】什么是 ThreadLocal?
什么是 ThreadLocal?
在多线程环境下,共享变量存在并发安全问题。换个思路,如果变量非共享,而是各个线程独享,就不会有并发安全问题。这种思想有个术语叫线程封闭,其本质上就是避免共享。没有共享,自然也就没有并发安全问题。在 Java 中,ThreadLocal 正是根据这个思路而设计的。
ThreadLocal 为每个线程都创建了一个本地副本,这个副本只能被当前线程访问,其他线程无法访问,那么自然是线程安全的。
ThreadLocal 有哪些应用场景?
(1)存储线程私有数据
用户会话(Session)管理:每个请求线程存储当前用户的
Session。private static final ThreadLocal<User> currentUser = ThreadLocal.withInitial(() -> null); // 设置当前用户 currentUser.set(user); // 获取当前用户 User user = currentUser.get();数据库连接(Connection)管理:避免传递
Connection参数。private static final ThreadLocal<Connection> connectionHolder = ThreadLocal.withInitial(() -> dataSource.getConnection());
(2)避免参数透传
问题:多层方法调用需要透传某个上下文参数(如 traceId)。
解决:使用 ThreadLocal 存储,避免方法参数传递。
private static final ThreadLocal<String> traceIdHolder = new ThreadLocal<>();
// 在入口处设置 traceId
traceIdHolder.set("req-123");
// 在任意深层方法获取
String traceId = traceIdHolder.get(); // 无需透传参数(3)线程安全的工具类
例如:SimpleDateFormat 是线程不安全的,但可以用 ThreadLocal 包装:
private static final ThreadLocal<SimpleDateFormat> dateFormatHolder =
ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd"));
// 线程安全地使用
String formattedDate = dateFormatHolder.get().format(new Date());最佳实践
(1)尽量用 static final
private static final ThreadLocal<User> userHolder = new ThreadLocal<>();避免重复创建 ThreadLocal 实例。
(2)必须调用 remove()
尤其在线程池场景,否则会导致内存泄漏。
(3)推荐初始化默认值
ThreadLocal<User> userHolder = ThreadLocal.withInitial(() -> new User());(4)避免在父子线程间传递
ThreadLocal 不能自动继承,需手动处理(可用 InheritableThreadLocal)。
【中等】ThreadLocal 的原理是什么?⭐⭐⭐
ThreadLocal 是线程本地变量,核心作用是为每个线程创建独立的变量副本,实现线程间数据隔离。
核心结构
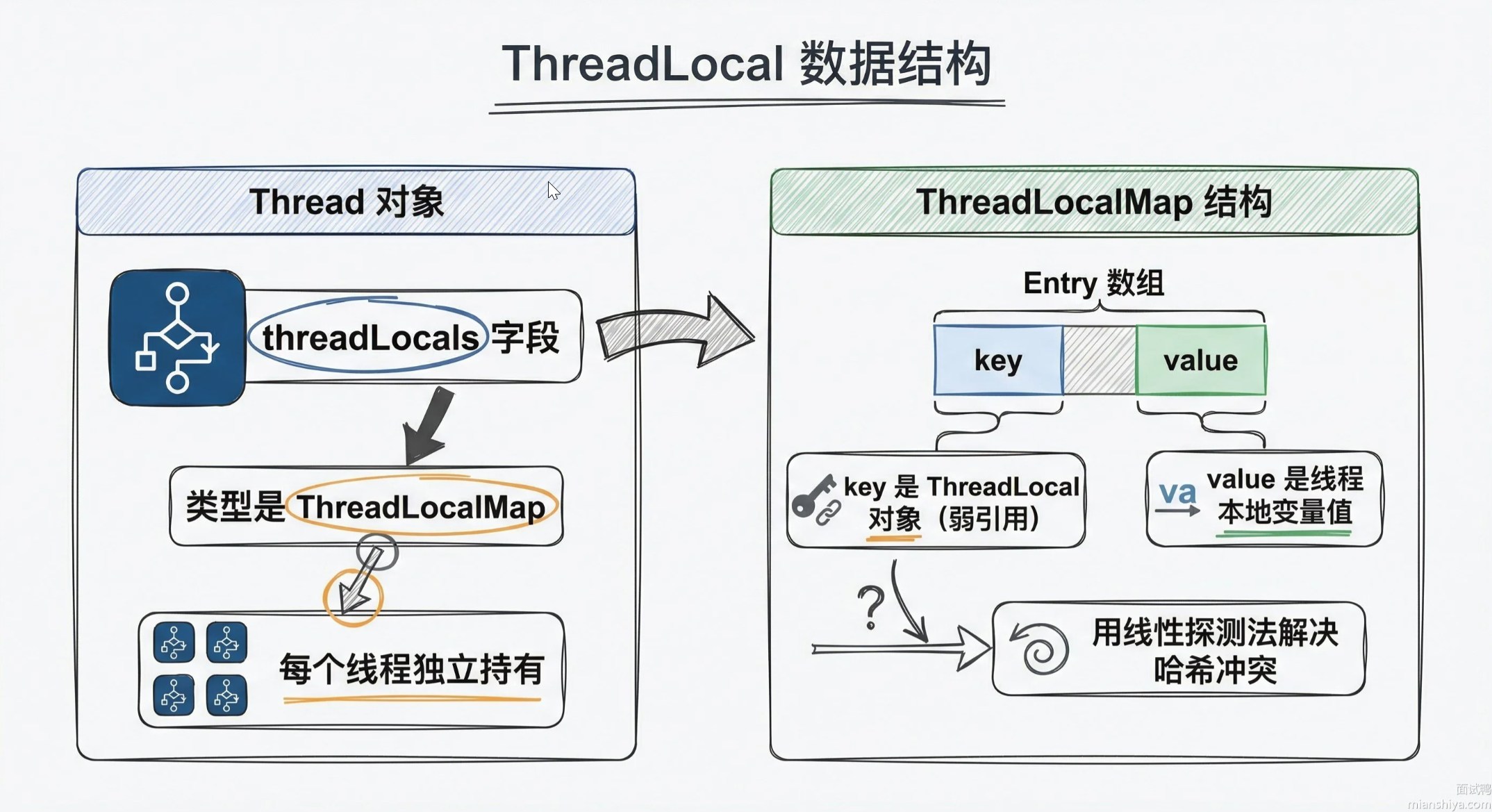
| 角色 | 作用(记忆点) | 核心关系 |
|---|---|---|
| ThreadLocal | 对外暴露的操作入口(get/set/remove) | 作为 Key,关联线程的变量副本 |
| Thread | 线程对象,内置 ThreadLocalMap 成员变量 | 每个线程有专属的 ThreadLocalMap |
| ThreadLocalMap | 线程内部的哈希表(类似 HashMap) | Key=ThreadLocal(弱引用),Value = 变量副本 |
核心机制
- 弱引用解决内存泄漏(关键)
- ThreadLocalMap 的 Key 是 ThreadLocal 的弱引用。
- 当 ThreadLocal 无强引用时,GC 会回收 Key。
- 仅回收 Key 仍会残留 Value(强引用),需手动调用
remove()清空,避免内存泄漏;
- 线程隔离本质:变量副本存在 Thread 自身的 Map 中,而非 ThreadLocal 里,ThreadLocal 仅作为 “索引”;
- 初始化机制:重写
initialValue()可指定初始值,也可通过setInitialValue()手动初始化。
应用场景
| 场景 | 核心用法 |
|---|---|
| 资源隔离 | 数据库连接、Session、用户上下文(如登录态),避免线程共享冲突 |
| 性能优化 | 替代方法传参,减少多线程下锁的使用(如 SimpleDateFormat 隔离) |
| 链路追踪 | 存储线程专属的追踪 ID(TraceID),全链路日志关联 |
【中等】如何解决 ThreadLocal 内存泄漏问题?⭐⭐
ThreadLocal 的内存泄漏问题源于其特殊的 "弱引用 Key + 强引用 Value" 存储结构。
| 泄漏原因 | 核心逻辑 |
|---|---|
| 核心矛盾 | ThreadLocalMap 的 Key 是弱引用(GC 回收),Value 是强引用(绑定线程),导致 Key 回收后 Value 成 “僵尸值”,随线程长期存活 |
| 高危场景 | 线程池(线程复用)+ 未手动清理 → 僵尸值累积,内存持续泄漏 |
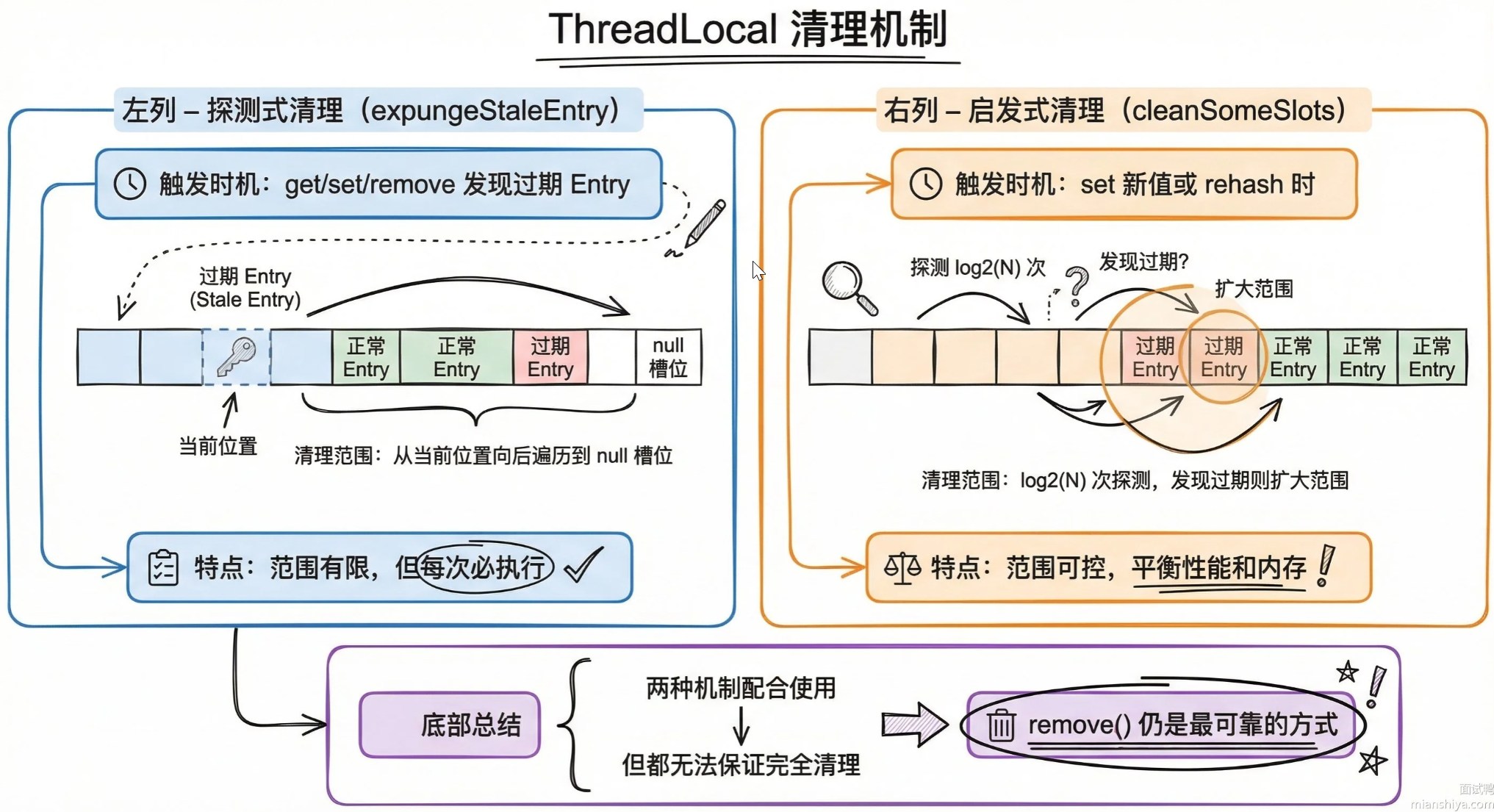
ThreadLocal 内存泄露场景
ExecutorService pool = Executors.newFixedThreadPool(5);
ThreadLocal<BigObject> tl = new ThreadLocal<>();
pool.execute(() -> {
tl.set(new BigObject()); // 存储大对象
// 业务逻辑。..
// 缺少 tl.remove()!线程复用后旧 Value 仍然存在
});remove() 未放 finally 块ThreadLocal<String> tl = new ThreadLocal<>();
tl.set("数据");
if (业务异常) {
throw new Exception(); // 跳过 remove()
}
tl.remove();ThreadLocal 内存泄露解决方案
(1)最核心:用完必在 finally 调用 remove()(治标治本)
在业务代码结束处(finally 块)调用 threadLocal.remove(),清空当前线程的 Value;
ThreadLocal<String> tl = new ThreadLocal<>();
try {
tl.set("业务数据");
// 业务逻辑执行
} finally {
tl.remove(); // 无论是否异常,必清理
}(2)兜底:依赖 Key 的弱引用特性(被动防护)
ThreadLocalMap 会在 set()/get()/remove() 时,自动清理 “Key 为 null” 的 Entry(僵尸值)。
弱引用是 JDK 层面的兜底,但若长期不操作 Map(如线程池空闲),仍会泄漏,需配合主动 remove。
(3)高危场景:线程池使用必规范(重点避坑)
线程池线程复用,若前一个任务未清理 ThreadLocal,后一个任务会读取到脏数据 + 内存泄漏;
线程池任务中,ThreadLocal 必须在 finally 中 remove,或使用线程池的任务包装器统一清理。
(4)辅助:规范初始化(减少泄漏风险)
规范初始化可减少无效 set 操作,降低僵尸值产生概率。
- 方式 1:重写
initialValue()初始化,避免多次 set 导致旧值残留; - 方式 2:使用
ThreadLocal.withInitial()(Java 8+),初始化逻辑更清晰,减少空值操作;
ThreadLocal 使用避坑
| 常见误区 | 正确做法 |
|---|---|
| 依赖 GC 自动回收 | GC 仅回收 Key,无法回收 Value,必须手动 remove |
| 线程池只初始化一次 ThreadLocal | 每次任务执行完都要 remove,而非仅初始化 |
| 认为 ThreadLocal 静态化会泄漏 | 静态化本身不泄漏,泄漏根源是未 remove + 线程复用 |
【中等】InheritableThreadLocal 的实现原理是什么?
核心设计目标
- 线程间值继承:子线程自动继承父线程的 ThreadLocal 值
- 与 ThreadLocal 兼容:继承自
ThreadLocal,保持相同 API
数据存储位置
继承自ThreadLocal,但使用线程对象的独立字段;Thread.inheritableThreadLocals(专门存储可继承的变量)
线程创建时的值拷贝
触发时机:当父线程创建子线程(
Thread.init()方法)拷贝逻辑:
if (parent.inheritableThreadLocals != null) { this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals); }深拷贝保证隔离:子线程获得父线程值的独立副本(修改互不影响)
值传递规则
- 仅初始化时拷贝:子线程创建后父线程对值的修改不再影响子线程
- 浅拷贝问题:若存储引用对象,父子线程仍共享同一对象(需开发者自行处理线程安全)
与 ThreadLocal 的对比
| 特性 | InheritableThreadLocal | ThreadLocal |
|---|---|---|
| 继承性 | 子线程自动继承父线程值 | 完全隔离 |
| 存储字段 | Thread.inheritableThreadLocals | Thread.threadLocals |
| 性能开销 | 略高(需初始化时拷贝数据) | 更低 |
| 使用场景 | 需要跨线程传递上下文(如 TraceID) | 线程私有数据 |
使用注意事项
- 对象共享风险:若值是可变的引用对象,需自行保证线程安全
- 线程池陷阱:线程池复用线程时会导致旧值残留(需手动清理)
- 性能影响:大量线程创建时,值拷贝可能成为瓶颈
典型应用场景
// 父线程设置值
InheritableThreadLocal<String> itl = new InheritableThreadLocal<>();
itl.set("parent_value");
new Thread(() -> {
// 子线程自动读取到父线程设置的值
System.out.println(itl.get()); // 输出:parent_value
}).start();实现局限
- 不支持动态更新:子线程启动后父线程的修改不可见
- 无回调机制:无法像
ThreadLocal的initialValue()那样自定义子线程初始值