《极客时间教程 - 高并发系统设计 40 问》笔记
《极客时间教程 - 高并发系统设计 40 问》笔记
基础篇
高并发系统:它的通用设计方法是什么?
并发、异步、缓存
架构分层:我们为什么一定要这么做?
分层架构典型代表:
- MVC(Model-View-Controller)
- 表现层、逻辑层和数据访问层
- OSI 七层网络模型
分层的好处
- 分层的设计可以简化系统设计,让不同的人专注做某一层次的事情。
- 再有,分层之后可以做到很高的复用。
- 分层架构可以让我们更容易做横向扩展。
分层架构的不足
- 增加了代码的复杂度
系统设计目标(一):如何提升系统性能?
讲述了性能指标和性能量化方式。
系统设计目标(二):系统怎样做到高可用?
故障转移
- 健康检查:心跳检测
- 选举:Paxos、Raft
- 负载均衡
流量控制:
- 超时与重试
- 限流
- 降级
系统运维
- 灰度发布
- 故障演练
- CI/CD
多活架构
系统设计目标(三):如何让系统易于扩展?
拆分首先考虑的维度是业务维度
其次,当吞吐量达到单机瓶颈,针对存储做水平差费
数据库篇
池化技术:如何减少频繁创建数据库连接的性能损耗?
池化技术解决频繁创建连接、创建对象的成本
数据库优化方案(一):查询请求增加时,如何做主从分离?
读写分离:写入时只写主库,在读数据时只读从库。通常采用一主多从架构。
读写分离的问题:主从同步的延迟
读写分离的关键:
- 主从复制
- 读写流量分发
- 代理:Cobar、Mycat
- 客户端:sharding-jdbc、TDDL
数据库优化方案(二):写入数据量增加时,如何实现分库分表?
垂直拆分:从业务维度,将表分为不同的库
水平拆分:分区 key 是关键。应使用合理策略,分库分表。如:hash 取 mod 法、范围划分
发号器:如何保证分库分表后 ID 的全局唯一性?
分布式 ID:UUID、Snowflake 算法
NoSQL:在高并发场景下,数据库和 NoSQL 如何做到互补?
LSM 树:牺牲了一定的读性能来换取写入数据的高性能,Hbase、Cassandra、LevelDB 都是用这种算法作为存储的引擎。
数据首先会写入到一个叫做 MemTable 的内存结构中,在 MemTable 中数据是按照写入的 Key 来排序的。为了防止 MemTable 里面的数据因为机器掉电或者重启而丢失,一般会通过写 Write Ahead Log 的方式将数据备份在磁盘上。
MemTable 在累积到一定规模时,它会被刷新生成一个新的文件,我们把这个文件叫做 SSTable(Sorted String Table)。当 SSTable 达到一定数量时,我们会将这些 SSTable 合并,减少文件的数量,因为 SSTable 都是有序的,所以合并的速度也很快。
当从 LSM 树里面读数据时,我们首先从 MemTable 中查找数据,如果数据没有找到,再从 SSTable 中查找数据。因为存储的数据都是有序的,所以查找的效率是很高的,只是因为数据被拆分成多个 SSTable,所以读取的效率会低于 B+ 树索引。
缓存篇
缓存:数据库成为瓶颈后,动态数据的查询要如何加速?
缓存分类:静态缓存、进程内缓存、分布式缓存
缓存的使用姿势(一):如何选择缓存的读写策略?
Cache Aside(旁路缓存)策略
先写表,再写缓存,可能会导致缓存和数据库数据不一致
更新表,删除缓存 key;读数据时,从表中读取。
读策略的步骤
- 从缓存中读取数据;
- 如果缓存命中,则直接返回数据;
- 如果缓存不命中,则从数据库中查询数据;
- 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤
- 更新数据库中的记录;
- 删除缓存记录。
Cache Aside 理论上还是有较小概率导致数据不一致。
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。
如果你的业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快地过期,对业务的影响也是可以接受。
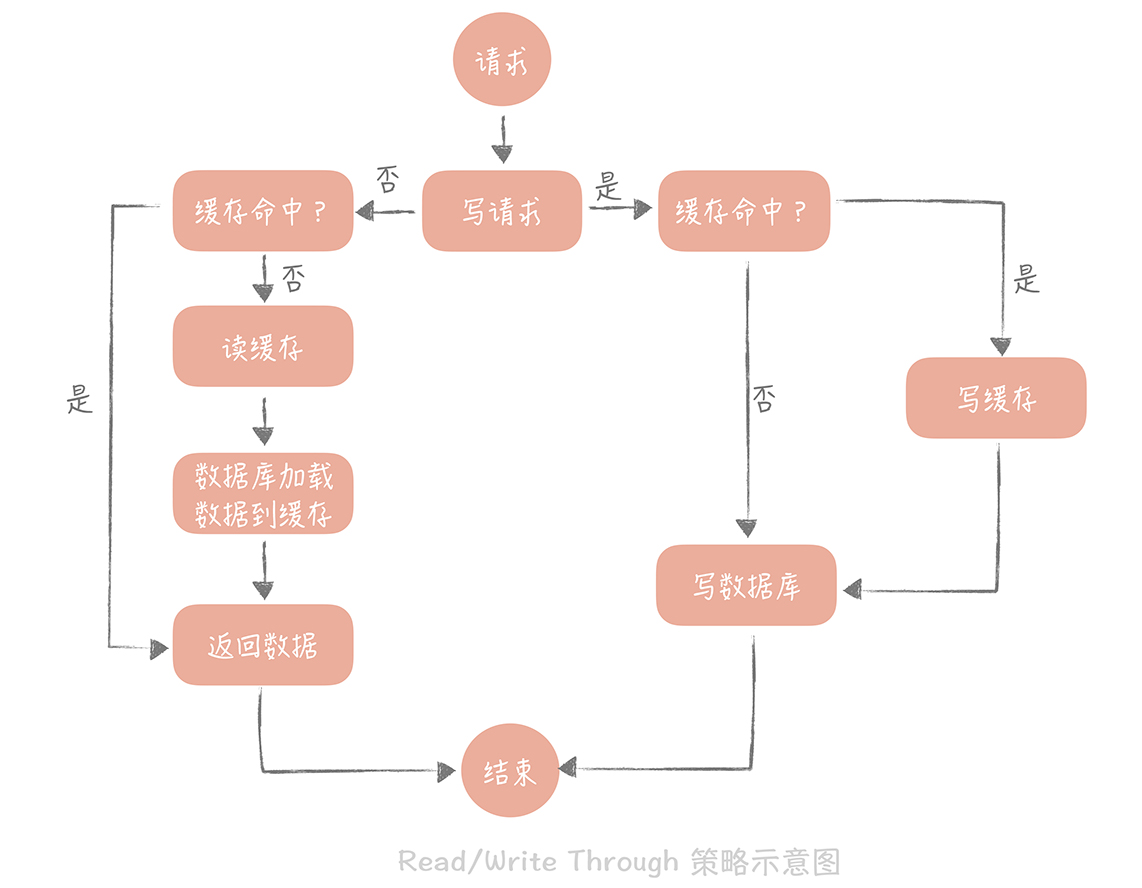
Read/Write Through(读穿 / 写穿)策略
Write Back(写回)策略
核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。
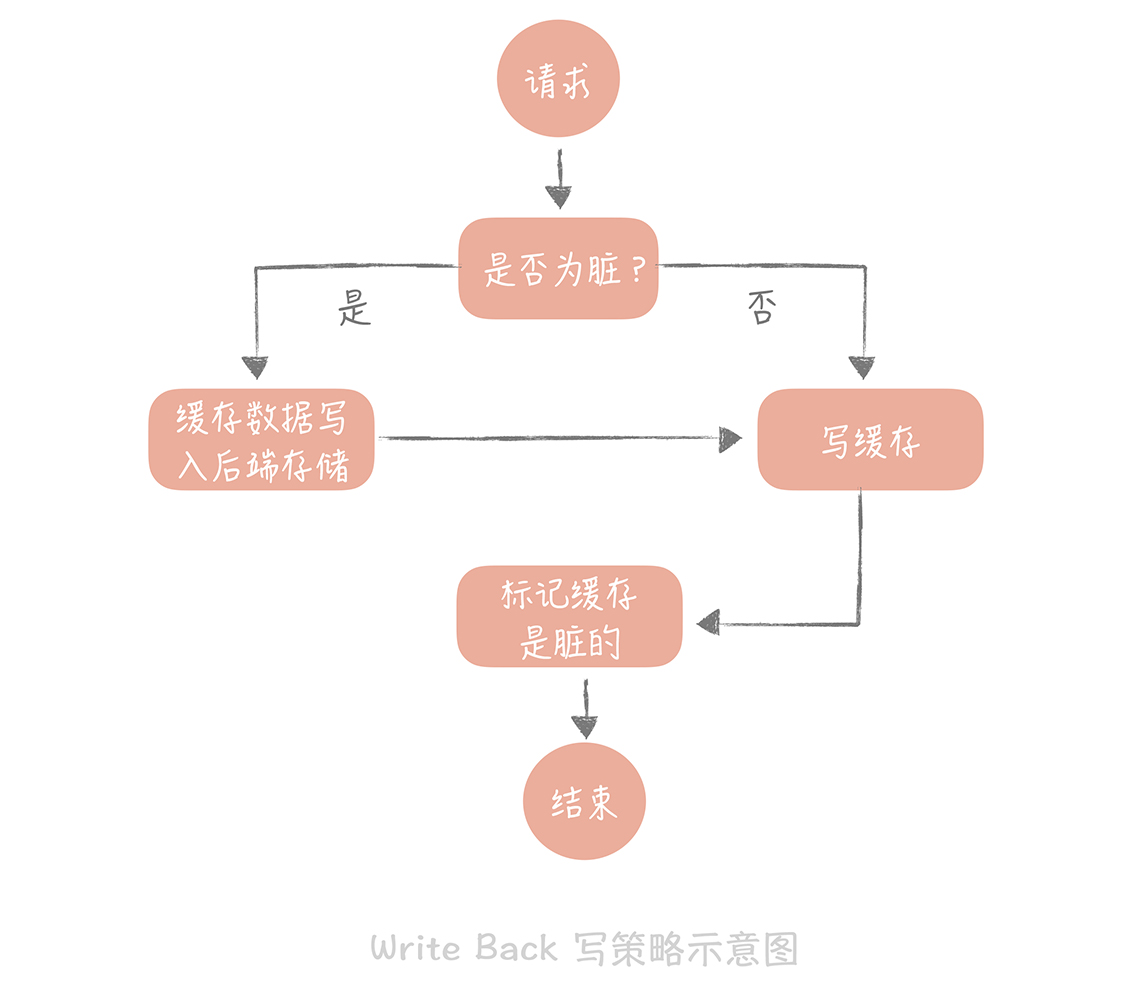
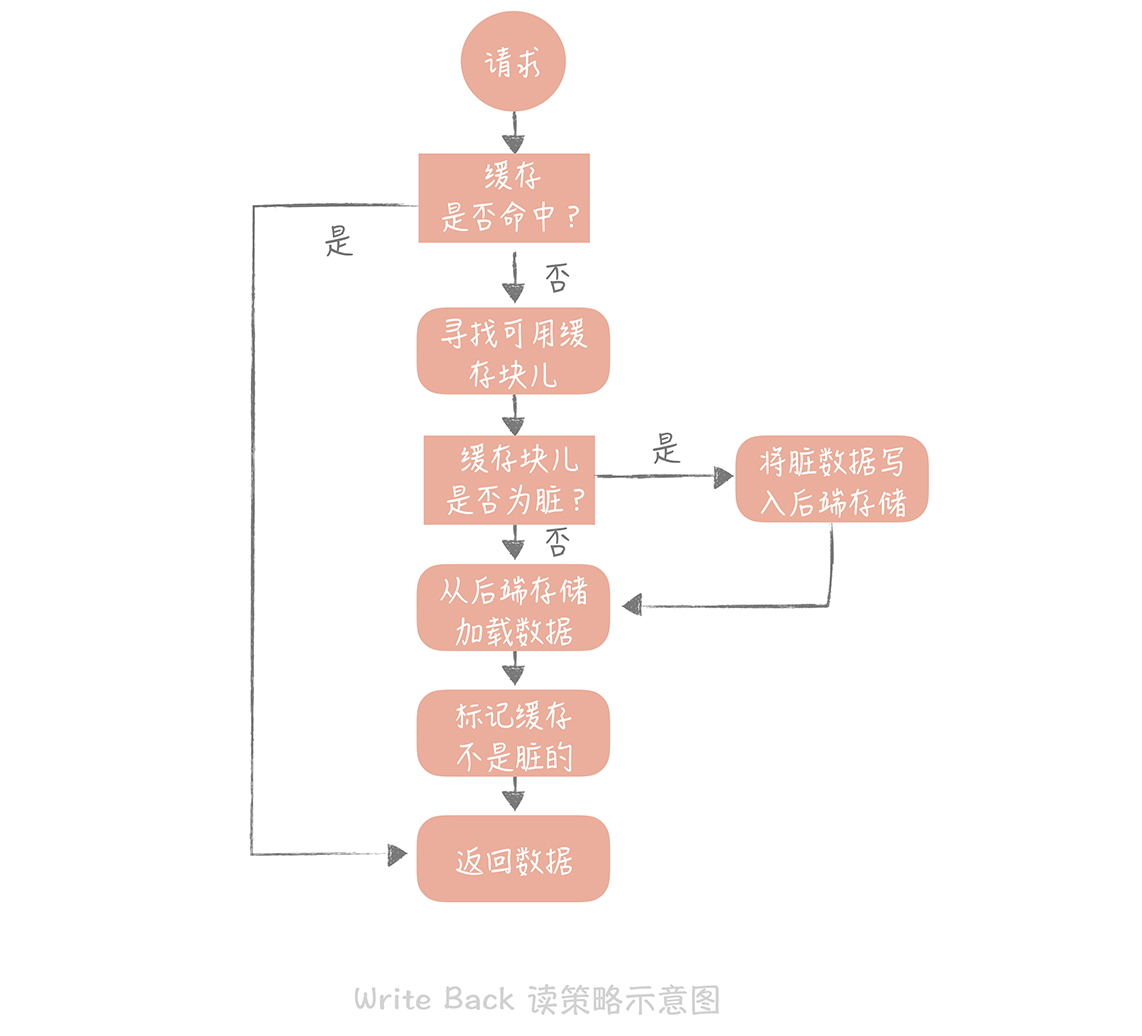
这种策略不能被应用到我们常用的数据库和缓存的场景中,它是计算机体系结构中的设计,比如我们在向磁盘中写数据时采用的就是这种策略。
但因为缓存一般使用内存,而内存是非持久化的,所以一旦缓存机器掉电,就会造成原本缓存中的脏块儿数据丢失。所以你会发现系统在掉电之后,之前写入的文件会有部分丢失,就是因为 Page Cache 还没有来得及刷盘造成的。
缓存的使用姿势(二):缓存如何做到高可用?
分布式缓存的高可用方案
- 客户端方案:在客户端配置多个缓存的节点,通过缓存写入和读取算法策略来实现分布式,从而提高缓存的可用性。
- 代理层方案:客户端所有的写入和读取的请求都通过代理层,而代理层中会内置高可用策略,帮助提升缓存系统的高可用。
- 服务度方案:Redis Sentinel 方案
缓存的使用姿势(三):缓存穿透了怎么办?
缓存穿透解決方案:
- 保存 null 值
- 布隆过滤器
消息队列篇
消息队列:秒杀时如何处理每秒上万次的下单请求?
削峰、异步处理、系统解耦
消息投递:如何保证消息仅仅被消费一次?
系统架构:每秒 1 万次请求的系统要做服务化拆分吗?
系统中,使用的资源出现扩展性问题,尤其是数据库的连接数出现瓶颈;
大团队共同维护一套代码,带来研发效率的降低,和研发成本的提升;
系统部署成本越来越高。
微服务架构:微服务化后,系统架构要如何改造?
服务拆分时要遵循哪些原则?
服务的边界如何确定?服务的粒度是怎样呢?
在服务化之后,会遇到哪些问题呢?我们又将如何来解决?
分布式服务篇
维护篇
给系统加上眼睛:服务端监控要怎么做?
CPU、内存、磁盘、网络
道路千万条,监控第一条,监控不到位,领导两行泪
监控指标
采集方式
- Agent
- 埋点
- 日志
处理和展示
应用性能管理:用户的使用体验应该如何监控?
压力测试:怎样设计全链路压力测试平台?
配置管理:成千上万的配置项要如何管理?
- 配置存储是分级的,有公共配置,有个性的配置,一般个性配置会覆盖公共配置,这样可以减少存储配置项的数量;
- 配置中心可以提供配置变更通知的功能,可以实现配置的热更新;
- 配置中心关注的性能指标中,可用性的优先级是高于性能的,一般我们会要求配置中心的可用性达到 99.999%,甚至会是 99.9999%。