分布式会话基本原理
分布式会话基本原理
由于 Http 是一种无状态的协议,服务器单单从网络连接上无从知道客户身份。
会话跟踪是 Web 程序中常用的技术,用来跟踪用户的整个会话。常用会话跟踪技术是 Cookie 与 Session。
Cookie
由于 Http 是一种无状态的协议,服务器单从网络连接上无从知道客户身份。
所以服务器与浏览器为了进行会话跟踪(知道是谁在访问我),就必须主动的去维护一个状态,这个状态用于告知服务端前后两个请求是否来自同一浏览器。而这个状态需要通过 cookie 或者 session 去实现。
什么是 Cookie
Cookie 实际上是存储在用户浏览器上的文本信息,并保留了各种跟踪的信息。
一个简单的 cookie 设置如下:
Set-Cookie: <cookie-name>=<cookie-value>
HTTP/2.0 200 OK
Content-Type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[page content]
Cookie 的工作步骤
- 浏览器请求服务器,如果服务器需要记录该用户的状态,就是用 response 向浏览器颁发一个 Cookie。
- 浏览器会把 Cookie 保存下来。
- 当浏览器再请求该网站时,浏览器把该请求的网址连同 Cookie 一同提交给服务器。服务器检查该 Cookie,以此来辨认用户状态。
Cookie 的作用
Cookie 主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
注:Cookie 功能需要浏览器的支持,如果浏览器不支持 Cookie 或者 Cookie 禁用了,Cookie 功能就会失效。
Cookie 的重要属性
| 属性 | 说明 |
|---|---|
| name=value | 键值对,设置 Cookie 的名称及相对应的值,都必须是字符串类型 - 如果值为 Unicode 字符,需要为字符编码。 - 如果值为二进制数据,则需要使用 BASE64 编码。 |
| domain | 指定 cookie 所属域名,默认是当前域名 |
| path | 指定 cookie 在哪个路径(路由)下生效,默认是 '/'。 如果设置为 /abc,则只有 /abc 下的路由可以访问到该 cookie,如:/abc/read。 |
| maxAge | cookie 失效的时间,单位秒。如果为整数,则该 cookie 在 maxAge 秒后失效。如果为负数,该 cookie 为临时 cookie ,关闭浏览器即失效,浏览器也不会以任何形式保存该 cookie 。如果为 0,表示删除该 cookie 。默认为 -1。 - 比 expires 好用。 |
| expires | 过期时间,在设置的某个时间点后该 cookie 就会失效。 一般浏览器的 cookie 都是默认储存的,当关闭浏览器结束这个会话的时候,这个 cookie 也就会被删除 |
| secure | 该 cookie 是否仅被使用安全协议传输。安全协议有 HTTPS,SSL 等,在网络上传输数据之前先将数据加密。默认为 false。 当 secure 值为 true 时,cookie 在 HTTP 中是无效,在 HTTPS 中才有效。 |
| httpOnly | 如果给某个 cookie 设置了 httpOnly 属性,则无法通过 JS 脚本 读取到该 cookie 的信息,但还是能通过 Application 中手动修改 cookie,所以只是在一定程度上可以防止 XSS 攻击,不是绝对的安全 |
Session
什么是 Session
Session 代表着服务器和客户端一次会话的过程。Session 对象存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的 Web 页之间跳转时,存储在 Session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当客户端关闭会话,或者 Session 超时失效时会话结束。
- session 是另一种记录服务器和客户端会话状态的机制
- session 是基于 cookie 实现的,session 存储在服务器端,sessionId 会被存储到客户端的 cookie 中
Session 的工作步骤
- 用户第一次请求服务器的时候,服务器根据用户提交的相关信息,创建对应的 Session。
- 请求返回时将此 Session 的唯一标识信息 SessionID 返回给浏览器。
- 浏览器接收到服务器返回的 SessionID 信息后,会将此信息存入到 Cookie 中,同时 Cookie 记录此 SessionID 属于哪个域名。
- 当用户第二次访问服务器的时候,请求会自动判断此域名下是否存在 Cookie 信息,如果存在自动将 Cookie 信息也发送给服务端,服务端会从 Cookie 中获取 SessionID,再根据 SessionID 查找对应的 Session 信息,如果没有找到说明用户没有登录或者登录失效,如果找到 Session 证明用户已经登录可执行后面操作。
根据以上流程可知,SessionID 是连接 Cookie 和 Session 的一道桥梁,大部分系统也是根据此原理来验证用户登录状态。
Cookie 和 Session 的区别
Cookie 和 Session 的主要区别可以参考以下表格:
| Cookie | Session | |
|---|---|---|
| 作用范围 | 保存在客户端(浏览器) | 保存在服务器端 |
| 隐私策略 | 存储在客户端,比较容易遭到非法获取 | 存储在服务端,安全性相对 Cookie 要好一些 |
| 存储方式 | 只能保存 ASCII | 可以保存任意数据类型。 一般情况下我们可以在 Session 中保持一些常用变量信息,比如说 UserId 等。 |
| 存储大小 | 不能超过 4K | 存储大小远高于 Cookie |
| 生命周期 | 可设置为永久保存 比如我们经常使用的默认登录(记住我)功能 | 一般失效时间较短 客户端关闭或者 Session 超时都会失效。 |
如果禁用 Cookie 怎么办
既然服务端是根据 Cookie 中的信息判断用户是否登录,那么如果浏览器中禁止了 Cookie,如何保障整个机制的正常运转。
第一种方案,每次请求中都携带一个 SessionID 的参数,也可以 Post 的方式提交,也可以在请求的地址后面拼接 xxx?SessionID=123456...。
第二种方案,Token 机制。Token 机制多用于 App 客户端和服务器交互的模式,也可以用于 Web 端做用户状态管理。
Token 的意思是“令牌”,是服务端生成的一串字符串,作为客户端进行请求的一个标识。Token 机制和 Cookie 和 Session 的使用机制比较类似。
当用户第一次登录后,服务器根据提交的用户信息生成一个 Token,响应时将 Token 返回给客户端,以后客户端只需带上这个 Token 前来请求数据即可,无需再次登录验证。
分布式 Session
在分布式场景下,一个用户的 Session 如果只存储在一个服务器上,那么当负载均衡器把用户的下一个请求转发到另一个服务器上,该服务器没有用户的 Session,就可能导致用户需要重新进行登录等操作。
分布式 Session 的几种实现策略:
- 粘性 session
- 应用服务器间的 session 复制共享
- 基于缓存的 session 共享 ✅
推荐:基于缓存的 session 共享
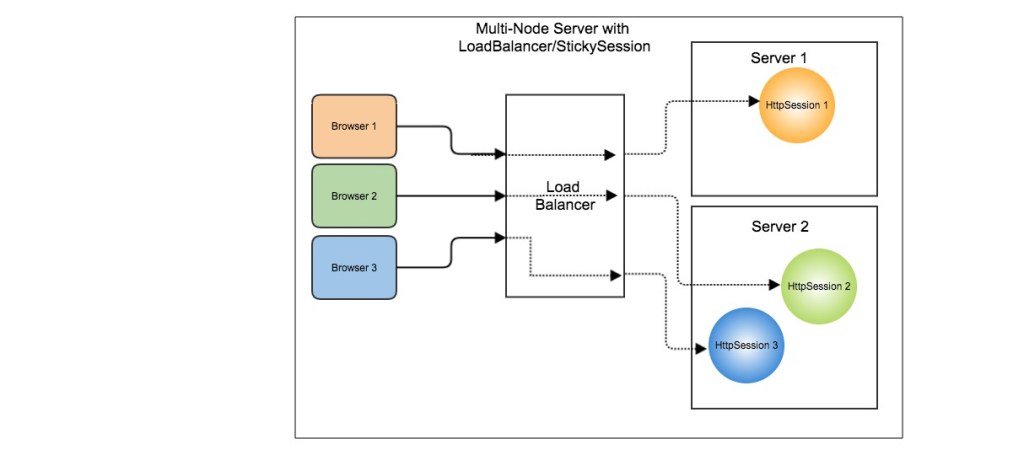
粘性 Session
粘性 Session(Sticky Sessions)需要配置负载均衡器,使得一个用户的所有请求都路由到一个服务器节点上,这样就可以把用户的 Session 存放在该服务器节点中。
缺点:当服务器节点宕机时,将丢失该服务器节点上的所有 Session。
Session 复制共享
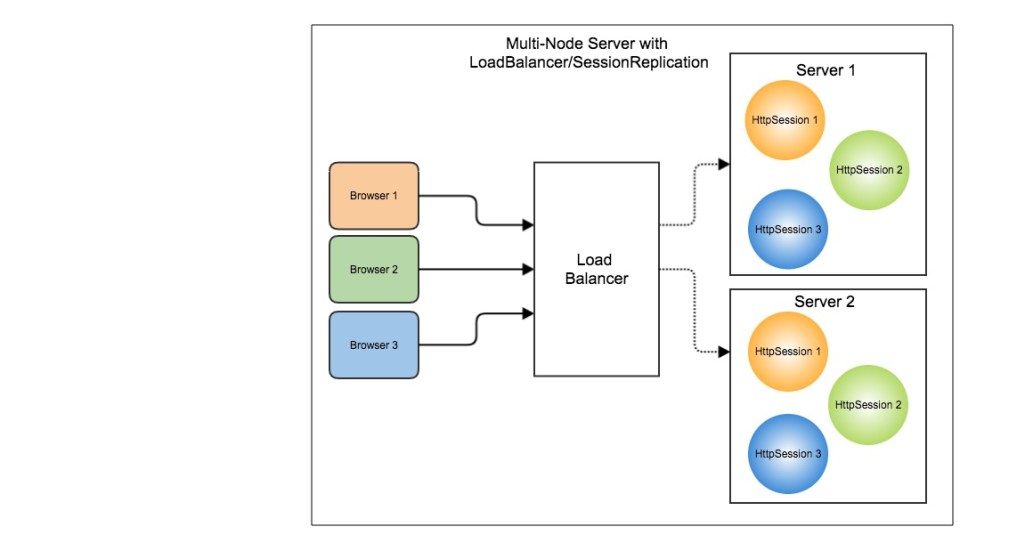
Session 复制共享(Session Replication)在服务器节点之间进行 Session 同步操作,这样的话用户可以访问任何一个服务器节点。
缺点:占用过多内存;同步过程占用网络带宽以及服务器处理器时间。
基于缓存的 session 共享
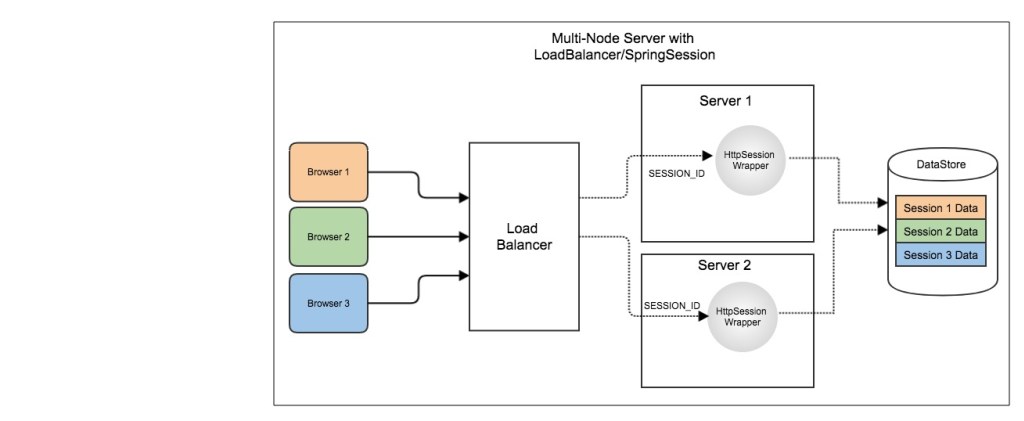
使用一个单独的存储服务器存储 Session 数据,可以存在 MySQL 数据库上,也可以存在 Redis 或者 Memcached 这种内存型数据库。
缺点:需要去实现存取 Session 的代码。
具体实现
JWT Token
使用 JWT Token 储存用户身份,然后再从数据库或者 cache 中获取其他的信息。这样无论请求分配到哪个服务器都无所谓。
tomcat + redis
这个其实还挺方便的,就是使用 session 的代码,跟以前一样,还是基于 tomcat 原生的 session 支持即可,然后就是用一个叫做 Tomcat RedisSessionManager 的东西,让所有我们部署的 tomcat 都将 session 数据存储到 redis 即可。
在 tomcat 的配置文件中配置:
<Valve className="com.orangefunction.tomcat.redissessions.RedisSessionHandlerValve" />
<Manager className="com.orangefunction.tomcat.redissessions.RedisSessionManager"
host="{redis.host}"
port="{redis.port}"
database="{redis.dbnum}"
maxInactiveInterval="60"/>
然后指定 redis 的 host 和 port 就 ok 了。
<Valve className="com.orangefunction.tomcat.redissessions.RedisSessionHandlerValve" />
<Manager className="com.orangefunction.tomcat.redissessions.RedisSessionManager"
sentinelMaster="mymaster"
sentinels="<sentinel1-ip>:26379,<sentinel2-ip>:26379,<sentinel3-ip>:26379"
maxInactiveInterval="60"/>
还可以用上面这种方式基于 redis 哨兵支持的 redis 高可用集群来保存 session 数据,都是 ok 的。
spring session + redis
上面那种 tomcat + redis 的方式好用,但是会严重依赖于 web 容器,不好将代码移植到其他 web 容器上去,尤其是你要是换了技术栈咋整?比如换成了 spring cloud 或者是 spring boot 之类的呢?
所以现在比较好的还是基于 Java 一站式解决方案,也就是 spring。人家 spring 基本上承包了大部分我们需要使用的框架,spirng cloud 做微服务,spring boot 做脚手架,所以用 sping session 是一个很好的选择。
在 pom.xml 中配置:
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
<version>1.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.1</version>
</dependency>
在 spring 配置文件中配置:
<bean id="redisHttpSessionConfiguration"
class="org.springframework.session.data.redis.config.annotation.web.http.RedisHttpSessionConfiguration">
<property name="maxInactiveIntervalInSeconds" value="600"/>
</bean>
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<property name="maxTotal" value="100" />
<property name="maxIdle" value="10" />
</bean>
<bean id="jedisConnectionFactory"
class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory" destroy-method="destroy">
<property name="hostName" value="${redis_hostname}"/>
<property name="port" value="${redis_port}"/>
<property name="password" value="${redis_pwd}" />
<property name="timeout" value="3000"/>
<property name="usePool" value="true"/>
<property name="poolConfig" ref="jedisPoolConfig"/>
</bean>
在 web.xml 中配置:
<filter>
<filter-name>springSessionRepositoryFilter</filter-name>
<filter-class>org.springframework.web.filter.DelegatingFilterProxy</filter-class>
</filter>
<filter-mapping>
<filter-name>springSessionRepositoryFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
示例代码:
@RestController
@RequestMapping("/test")
public class TestController {
@RequestMapping("/putIntoSession")
public String putIntoSession(HttpServletRequest request, String username) {
request.getSession().setAttribute("name", "leo");
return "ok";
}
@RequestMapping("/getFromSession")
public String getFromSession(HttpServletRequest request, Model model){
String name = request.getSession().getAttribute("name");
return name;
}
}
上面的代码就是 ok 的,给 spring session 配置基于 redis 来存储 session 数据,然后配置了一个 spring session 的过滤器,这样的话,session 相关操作都会交给 spring session 来管了。接着在代码中,就用原生的 session 操作,就是直接基于 spring sesion 从 redis 中获取数据了。
实现分布式的会话有很多种方式,我说的只不过是比较常见的几种方式,tomcat + redis 早期比较常用,但是会重耦合到 tomcat 中;近些年,通过 spring session 来实现。