Elasticsearch 简介
概述
Elasticsearch 是一个基于 Lucene 的搜索和数据分析工具,它提供了一个分布式服务。Elasticsearch 是遵从 Apache 开源条款的一款开源产品,是当前主流的企业级搜索引擎。
本文简单介绍了 Elasticsearch 的功能、特性、简史、概念,可以让读者在短时间内对于 Elasticsearch 有一个初步的认识。
什么是 Elasticsearch?
Elasticsearch 是一个开源的分布式搜索和分析引擎。
Elasticsearch 基于搜索库 Lucene 开发。Elasticsearch 隐藏了 Lucene 的复杂性,提供了简单易用的 REST API / Java API 接口(另外还有其他语言的 API 接口)。
Elasticsearch 是面向文档的,它将复杂数据结构序列化为 JSON 形式存储。
Elasticsearch 提供近实时(Near Realtime,缩写 NRT)的全文搜索。近实时是指:
- 从写入数据到数据可以被搜索,存在较小的延迟(大概是 1s)。
- 基于 Elasticsearch 执行搜索和分析可以达到秒级。
为什么使用 Elasticsearch?
Elasticsearch 是基于 Lucene 的,那么为什么不是直接使用 Lucene 呢?
Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库。
但是,Lucene 仅仅只是一个库。为了充分发挥其功能,需要使用 Java 并将 Lucene 直接集成到应用程序中。 Lucene 非常复杂,了解其工作原理并不容易。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单,通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档数据库,每个字段可以被索引与搜索。
- 一个分布式实时分析搜索引擎。
- 支持扩展为上百个服务节点的集群,并支持 PB 级别的半结构化数据。
Elasticsearch 有哪些应用场景?
Elasticsearch 的主要功能如下:
- 海量数据的分布式存储及集群管理
- 提供丰富的近实时搜索能力
- 海量数据的近实时分析(聚合)
Elasticsearch 被广泛应用于以下场景:
- 搜索
- 全文检索 - Elasticsearch 通过快速搜索大型数据集,使复杂的搜索查询变得更加容易。它对于需要即时和相关搜索结果的网站、应用程序或企业特别有用。
- 自动补全和拼写纠正 - 可以在用户输入内容时,实时提供自动补全和拼写纠正,以增加用户体验并提高搜索效率。
- 地理空间搜索 - 使用地理空间查询搜索位置并计算空间关系。
- 可观测性
- 日志、指标和链路追踪 - 收集、存储和分析来自应用程序、系统和服务的日志、指标和追踪。
- 性能监控 - 监控和分析业务关键性能指标。
- OpenTelemetry - 使用 OpenTelemetry 标准,将遥测数据采集到 Elastic Stack。
Elasticsearch 简史
Elasticsearch 里程碑版本:
- 1.0(2014 年)
- 5.0(2016 年)
- Lucene 6.x
- 默认打分机制从 TD-IDF 改为 BM25
- 增加 Keyword 类型
- 6.0(2017 年)
- Lucene 7.x
- 跨集群复制
- 索引生命周期管理
- SQL 的支持
- 7.0(2019 年)
- Lucene 8.0
- 移除 Type
- ECK (用于支持 K8S)
- 集群协调
- High Level Rest Client
- Script Score 查询
- 8.0(2022 年)
- Lucene 9.0
- 向量搜索
- 支持 OpenTelemetry
Elasticsearch 概念
index -> type -> mapping -> document -> field
Elasticsearch 集群的核心概念如下:
- Cluster(集群) - 由多个协同工作的 ES 实例组合成的集合称为集群。集群架构使得 ES 具备了高可用性和可扩展性。
- Node(节点) - 单个 ES 服务实例称为 Node,本质上就是一个 Java 进程。每个节点都有各自的名字,默认是随机分配的,也可以通过
node.name指定。 - Shard(分片) - 当单台机器不足以存储大量数据时,Elasticsearch 可以将一个索引中的数据切分为多个
分片(shard)。分片(shard)分布在多台服务器上存储。有了 shard 就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个 shard 都是一个 lucene index。 - Replica(副本) - 任何一个服务器随时可能故障或宕机,此时 shard 可能就会丢失,因此可以为每个 shard 创建多个
副本(replica)。replica 可以在 shard 故障时提供备用服务,保证数据不丢失,多个 replica 还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认 5 个),replica shard(随时修改数量,默认 1 个),默认每个索引 10 个 shard,5 个 primary shard,5 个 replica shard,最小的高可用配置,是 2 台服务器。
Elasticsearch 数据的核心概念如下:
- Index(索引) - 在 ES 中,可以将索引视为文档(document)的集合。
- ES 会为所有字段建立索引,经过处理后写入一个倒排索引(Inverted Index)。查找数据的时候,直接查找该索引。
- 所以,ES 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
- Type(类型) - 每个索引里可以有一个或者多个类型(type)。
类型(type)是 Index 的一个逻辑分类。- 不同的 Type 应该有相似的结构(schema),举例来说,
id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的 一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。 - 注意:ES 7.x 版已彻底移除 Type。
- 不同的 Type 应该有相似的结构(schema),举例来说,
- Document(文档) - Index 里面单条的记录称为 Document。文档是一组字段。每个文档都有一个唯一的 ID。
- Field(字段) - 包含数据的键值对。默认情况下,Elasticsearch 对每个字段中的所有数据建立索引,并且每个索引字段都具有专用的优化数据结构。
- Metadata Field(元数据字段) - 存储有关文档的信息的系统字段。元数据字段都以
_开头。常见元数据字段:
ES 核心概念 vs. DB 核心概念:
| ES | DB |
|---|---|
| 索引(index) | 数据库(database) |
| 类型(type,6.0 废弃,7.0 移除) | 数据表(table) |
| 文档(docuemnt) | 行(row) |
| 字符(field) | 列(column) |
| 映射(mapping) | 表结构(schema) |
Elastic Stack
Elastic Stack 通常被用来作为日志采集、检索、可视化的解决方案。
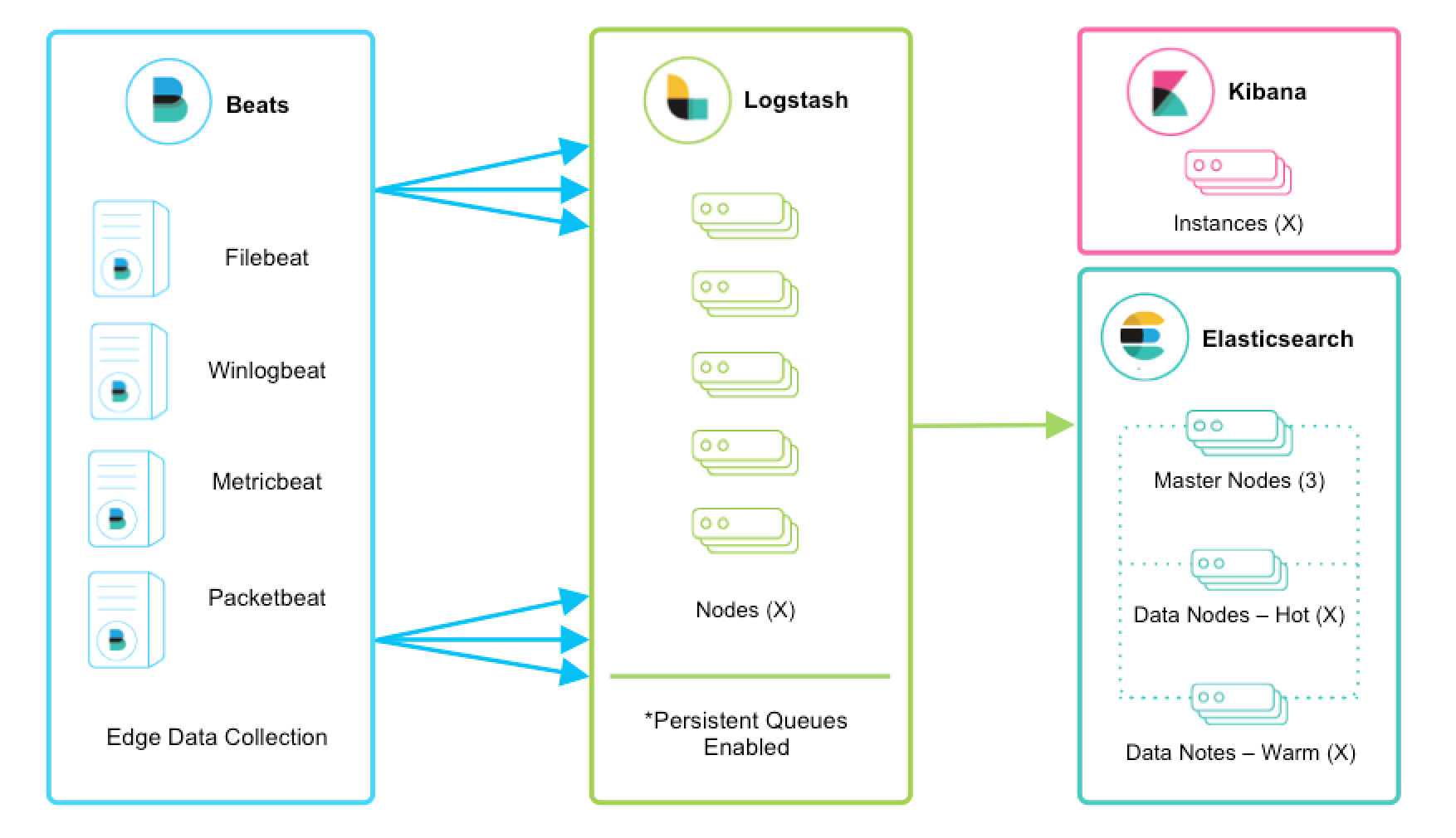
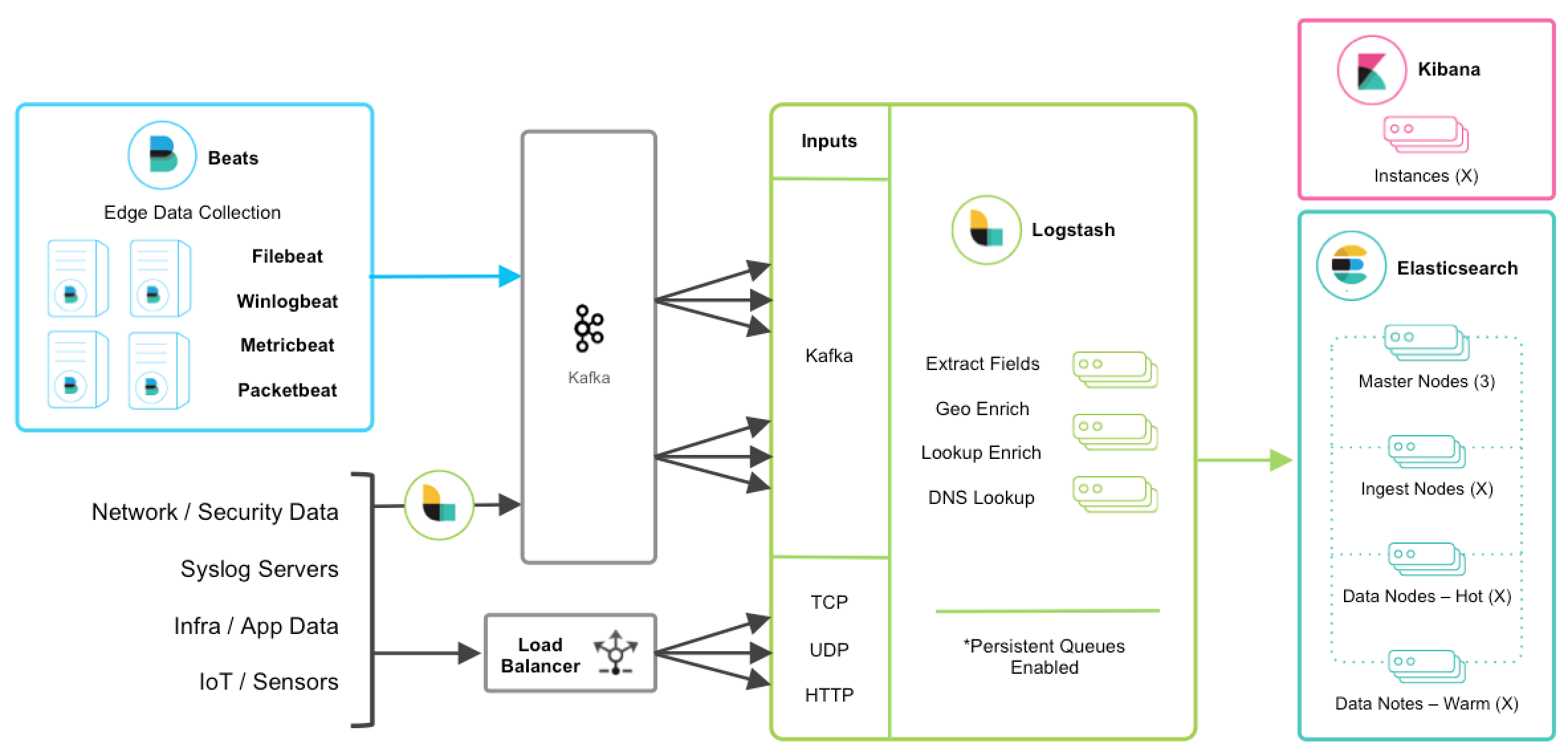
Elastic Stack 也常被称为 ELK,这是 Elastic 公司旗下三款产品 Elasticsearch 、Logstash 、Kibana 的首字母组合。
- Elasticsearch 负责存储数据,并提供对数据的检索和分析。
- Logstash 传输和处理你的日志、事务或其他数据。
- Kibana 将 Elasticsearch 的数据分析并渲染为可视化的报表。
Elastic Stack,在 ELK 的基础上扩展了一些新的产品。如:Beats,这是针对不同类型数据的轻量级采集器套件。
此外,基于 Elastic Stack,其技术生态还可以和一些主流的分布式中间件进行集成,以应对各种不同的场景。