Redis 实战
缓存
缓存是 Redis 最常见的应用场景。
Redis 有多种数据类型,以及丰富的操作命令,并且有着高性能、高可用的特性,非常适合用于分布式缓存。
缓存应用的基本原理,请参考 缓存基本原理 第四 ~ 第六节内容。
BitMap 和 BloomFilter
Redis 除了 5 种基本数据类型外,还支持 BitMap 和 BloomFilter(即布隆过滤器,可以通过 Redis Module 支持)。
BitMap 和 BloomFilter 都可以用于解决缓存穿透问题。要点在于:过滤一些不可能存在的数据。
什么是缓存穿透,可以参考:缓存基本原理
小数据量可以用 BitMap,大数据量可以用布隆过滤器。
分布式锁
使用 Redis 作为分布式锁,基本要点如下:
- 互斥性 - 使用
setnx抢占锁。 - 避免永远不释放锁 - 使用
expire加一个过期时间,避免一直不释放锁,导致阻塞。 - 原子性 - setnx 和 expire 必须合并为一个原子指令,避免 setnx 后,机器崩溃,没来得及设置 expire,从而导致锁永不释放。
更多分布式锁的实现方式及细节,请参考:分布式锁基本原理
根据 Redis 的特性,在实际应用中,存在一些应用小技巧。
keys 和 scan
使用 keys 指令可以扫出指定模式的 key 列表。
如果这个 redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?
首先,Redis 是单线程的。keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。
这个时候可以使用 scan 指令,scan 指令可以无阻塞的提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。
不过,增量式迭代命令也不是没有缺点的: 举个例子, 使用 SMEMBERS 命令可以返回集合键当前包含的所有元素, 但是对于 SCAN 这类增量式迭代命令来说, 因为在对键进行增量式迭代的过程中, 键可能会被修改, 所以增量式迭代命令只能对被返回的元素提供有限的保证 。
大 Key 如何处理
什么是 Redis Big Key?
Big Key 并不是指 key 的值很大,而是 key 对应的 value 很大。
一般而言,下面这两种情况被称为Big Key:
- String 类型的值大于 10 KB;
- Hash、List、Set、ZSet 类型的元素的个数超过 5000 个,或总大小超过 10MB
Big Key 会造成什么问题?
Big Key 会带来以下四种影响:
- 内存分布不均:集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有Big Key 的 Redis 节点占用内存多,QPS 也会比较大。
- 命令阻塞:Redis 单线程模型,操作大 Key 耗时,阻塞其他命令。
- 网络传输压力:每次获取Big Key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 客户端超时:由于 Redis 执行命令是单线程处理,然后在操作Big Key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
如何找到Big Key ?
(1)使用 redis-cli --bigkeys
命令:
redis-cli -h 127.0.0.1 -p 6379 -a "password" --bigkeys
注意事项:
- 推荐在从节点执行(主节点执行可能阻塞业务)
- 低峰期执行 或 加
-i参数控制扫描间隔(如-i 0.1表示每 100ms 扫描一次)
缺点:
- 只能返回每种数据类型最大的 1 个 Key(无法获取 Top N)
- 对集合类型只统计元素个数,而非实际内存占用
(2)使用 SCAN + 内存分析命令
遍历所有 Key(避免 KEYS * 阻塞 Redis):
redis-cli --scan --pattern "*" | while read key; do ...; done
分析 Key 大小:
- String:
STRLEN $key(字节数) - 集合类型(List/Hash/Set/ZSet):
- 方法 1:
LLEN/HLEN/SCARD/ZCARD(元素个数 × 预估元素大小) - 方法 2(Redis 4.0+):
MEMORY USAGE $key(精确内存占用)
- 方法 1:
优点:
- 可自定义筛选条件(如大小 Top 10)
- 精确计算内存占用
(3)使用 RdbTools 分析 RDB 文件
命令:
rdb dump.rdb -c memory --bytes 10240 -f redis.csv # 导出 >10KB 的 Key 到 CSV
适用场景:
- 离线分析,不影响线上 Redis
- 精准统计所有 Key 的内存分布
缺点:需要 Redis 生成 RDB 快照
如何删除Big Key?
删除操作的本质是要释放键值对占用的内存空间,不要小瞧内存的释放过程。
释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,操作系统需要把释放掉的内存块插入一个空闲内存块的链表,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会阻塞当前释放内存的应用程序。
所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞,如果主线程发生了阻塞,其他所有请求可能都会超时,超时越来越多,会造成 Redis 连接耗尽,产生各种异常。
因此,删除Big Key 这一个动作,我们要小心。具体要怎么做呢?这里给出两种方法:
- 分批次删除
- 异步删除(Redis 4.0 版本以上)
1、分批次删除
对于删除大 Hash,使用 hscan 命令,每次获取 100 个字段,再用 hdel 命令,每次删除 1 个字段。
Python 代码:
def del_large_hash():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_hash_key ="xxx" #要删除的大hash键名
cursor = '0'
while cursor != 0:
# 使用 hscan 命令,每次获取 100 个字段
cursor, data = r.hscan(large_hash_key, cursor=cursor, count=100)
for item in data.items():
# 再用 hdel 命令,每次删除1个字段
r.hdel(large_hash_key, item[0])
对于删除大 List,通过 ltrim 命令,每次删除少量元素。
Python 代码:
def del_large_list():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_list_key = 'xxx' #要删除的大list的键名
while r.llen(large_list_key)>0:
#每次只删除最右100个元素
r.ltrim(large_list_key, 0, -101)
对于删除大 Set,使用 sscan 命令,每次扫描集合中 100 个元素,再用 srem 命令每次删除一个键。
Python 代码:
def del_large_set():
r = redis.StrictRedis(host='redis-host1', port=6379)
large_set_key = 'xxx' # 要删除的大set的键名
cursor = '0'
while cursor != 0:
# 使用 sscan 命令,每次扫描集合中 100 个元素
cursor, data = r.sscan(large_set_key, cursor=cursor, count=100)
for item in data:
# 再用 srem 命令每次删除一个键
r.srem(large_size_key, item)
对于删除大 ZSet,使用 zremrangebyrank 命令,每次删除 top 100 个元素。
Python 代码:
def del_large_sortedset():
r = redis.StrictRedis(host='large_sortedset_key', port=6379)
large_sortedset_key='xxx'
while r.zcard(large_sortedset_key)>0:
# 使用 zremrangebyrank 命令,每次删除 top 100个元素
r.zremrangebyrank(large_sortedset_key,0,99)
2、异步删除
从 Redis 4.0 版本开始,可以采用异步删除法,用 unlink 命令代替 del 来删除。
这样 Redis 会将这个 key 放入到一个异步线程中进行删除,这样不会阻塞主线程。
除了主动调用 unlink 命令实现异步删除之外,我们还可以通过配置参数,达到某些条件的时候自动进行异步删除。
主要有 4 种场景,默认都是关闭的:
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del
noslave-lazy-flush no
它们代表的含义如下:
- lazyfree-lazy-eviction:表示当 Redis 运行内存超过 maxmeory 时,是否开启 lazy free 机制删除;
- lazyfree-lazy-expire:表示设置了过期时间的键值,当过期之后是否开启 lazy free 机制删除;
- lazyfree-lazy-server-del:有些指令在处理已存在的键时,会带有一个隐式的 del 键的操作,比如 rename 命令,当目标键已存在,Redis 会先删除目标键,如果这些目标键是一个 big key,就会造成阻塞删除的问题,此配置表示在这种场景中是否开启 lazy free 机制删除;
- slave-lazy-flush:针对 slave (从节点) 进行全量数据同步,slave 在加载 master 的 RDB 文件前,会运行 flushall 来清理自己的数据,它表示此时是否开启 lazy free 机制删除。
建议开启其中的 lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-server-del 等配置,这样就可以有效的提高主线程的执行效率。
最受欢迎文章
选出最受欢迎文章,需要支持对文章进行评分。
对文章进行投票
(1)使用 HASH 存储文章
使用 HASH 类型存储文章信息。其中:key 是文章 ID;field 是文章的属性 key;value 是属性对应值。

操作:
- 存储文章信息 - 使用
HSET或HMGET命令 - 查询文章信息 - 使用
HGETALL命令 - 添加投票 - 使用
HINCRBY命令
(2)使用 ZSET 针对不同维度集合排序
使用 ZSET 类型分别存储按照时间排序和按照评分排序的文章 ID 集合。
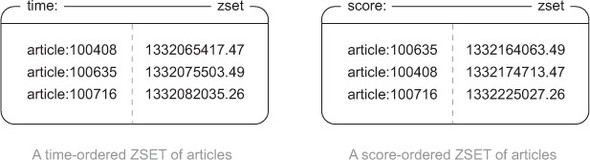
操作:
- 添加记录 - 使用
ZADD命令 - 添加分数 - 使用
ZINCRBY命令 - 取出多篇文章 - 使用
ZREVRANGE命令
(3)为了防止重复投票,使用 SET 类型记录每篇文章 ID 对应的投票集合。

操作:
- 添加投票者 - 使用
SADD命令 - 设置有效期 - 使用
EXPIRE命令
(4)假设 user:115423 给 article:100408 投票,分别需要高更新评分排序集合以及投票集合。

当需要对一篇文章投票时,程序需要用 ZSCORE 命令检查记录文章发布时间的有序集合,判断文章的发布时间是否超过投票有效期(比如:一星期)。
public void articleVote(Jedis conn, String user, String article) {
// 计算文章的投票截止时间。
long cutoff = (System.currentTimeMillis() / 1000) - ONE_WEEK_IN_SECONDS;
// 检查是否还可以对文章进行投票
// (虽然使用散列也可以获取文章的发布时间,
// 但有序集合返回的文章发布时间为浮点数,
// 可以不进行转换直接使用)。
if (conn.zscore("time:", article) < cutoff) {
return;
}
// 从article:id标识符(identifier)里面取出文章的ID。
String articleId = article.substring(article.indexOf(':') + 1);
// 如果用户是第一次为这篇文章投票,那么增加这篇文章的投票数量和评分。
if (conn.sadd("voted:" + articleId, user) == 1) {
conn.zincrby("score:", VOTE_SCORE, article);
conn.hincrBy(article, "votes", 1);
}
}
发布并获取文章
发布文章:
- 添加文章 - 使用
INCR命令计算新的文章 ID,填充文章信息,然后用HSET命令或HMSET命令写入到HASH结构中。 - 将文章作者 ID 添加到投票名单 - 使用
SADD命令添加到代表投票名单的SET结构中。 - 设置投票有效期 - 使用
EXPIRE命令设置投票有效期。
public String postArticle(Jedis conn, String user, String title, String link) {
// 生成一个新的文章ID。
String articleId = String.valueOf(conn.incr("article:"));
String voted = "voted:" + articleId;
// 将发布文章的用户添加到文章的已投票用户名单里面,
conn.sadd(voted, user);
// 然后将这个名单的过期时间设置为一周(第3章将对过期时间作更详细的介绍)。
conn.expire(voted, ONE_WEEK_IN_SECONDS);
long now = System.currentTimeMillis() / 1000;
String article = "article:" + articleId;
// 将文章信息存储到一个散列里面。
HashMap<String, String> articleData = new HashMap<String, String>();
articleData.put("title", title);
articleData.put("link", link);
articleData.put("user", user);
articleData.put("now", String.valueOf(now));
articleData.put("votes", "1");
conn.hmset(article, articleData);
// 将文章添加到根据发布时间排序的有序集合和根据评分排序的有序集合里面。
conn.zadd("score:", now + VOTE_SCORE, article);
conn.zadd("time:", now, article);
return articleId;
}
分页查询最受欢迎文章:
使用 ZINTERSTORE 命令根据页码、每页记录数、排序号,根据评分值从大到小分页查出文章 ID 列表。
public List<Map<String, String>> getArticles(Jedis conn, int page, String order) {
// 设置获取文章的起始索引和结束索引。
int start = (page - 1) * ARTICLES_PER_PAGE;
int end = start + ARTICLES_PER_PAGE - 1;
// 获取多个文章ID。
Set<String> ids = conn.zrevrange(order, start, end);
List<Map<String, String>> articles = new ArrayList<>();
// 根据文章ID获取文章的详细信息。
for (String id : ids) {
Map<String, String> articleData = conn.hgetAll(id);
articleData.put("id", id);
articles.add(articleData);
}
return articles;
}
对文章进行分组
如果文章需要分组,功能需要分为两块:
- 记录文章属于哪个群组
- 负责取出群组里的文章
将文章添加、删除群组:
public void addRemoveGroups(Jedis conn, String articleId, String[] toAdd, String[] toRemove) {
// 构建存储文章信息的键名。
String article = "article:" + articleId;
// 将文章添加到它所属的群组里面。
for (String group : toAdd) {
conn.sadd("group:" + group, article);
}
// 从群组里面移除文章。
for (String group : toRemove) {
conn.srem("group:" + group, article);
}
}
取出群组里的文章:
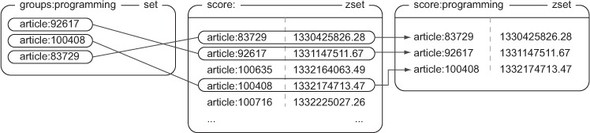
- 通过对存储群组文章的集合和存储文章评分的有序集合执行
ZINTERSTORE命令,可以得到按照文章评分排序的群组文章。 - 通过对存储群组文章的集合和存储文章发布时间的有序集合执行
ZINTERSTORE命令,可以得到按照文章发布时间排序的群组文章。
public List<Map<String, String>> getGroupArticles(Jedis conn, String group, int page, String order) {
// 为每个群组的每种排列顺序都创建一个键。
String key = order + group;
// 检查是否有已缓存的排序结果,如果没有的话就现在进行排序。
if (!conn.exists(key)) {
// 根据评分或者发布时间,对群组文章进行排序。
ZParams params = new ZParams().aggregate(ZParams.Aggregate.MAX);
conn.zinterstore(key, params, "group:" + group, order);
// 让Redis在60秒钟之后自动删除这个有序集合。
conn.expire(key, 60);
}
// 调用之前定义的getArticles函数来进行分页并获取文章数据。
return getArticles(conn, page, key);
}
管理令牌
网站一般会以 Cookie、Session、令牌这类信息存储用户身份信息。
可以将 Cookie/Session/令牌 和用户的映射关系存储在 HASH 结构。
下面以令牌来举例。
查询令牌
public String checkToken(Jedis conn, String token) {
// 尝试获取并返回令牌对应的用户。
return conn.hget("login:", token);
}
更新令牌
- 用户每次访问页面,可以记录下令牌和当前时间戳的映射关系,存入一个
ZSET结构中,以便分析用户是否活跃,继而可以周期性清理最老的令牌,统计当前在线用户数等行为。 - 用户如果正在浏览商品,可以记录到用户最近浏览过的商品有序集合中(集合可以限定数量,超过数量进行裁剪),存入到一个
ZSET结构中,以便分析用户最近可能感兴趣的商品,以便推荐商品。
public void updateToken(Jedis conn, String token, String user, String item) {
// 获取当前时间戳。
long timestamp = System.currentTimeMillis() / 1000;
// 维持令牌与已登录用户之间的映射。
conn.hset("login:", token, user);
// 记录令牌最后一次出现的时间。
conn.zadd("recent:", timestamp, token);
if (item != null) {
// 记录用户浏览过的商品。
conn.zadd("viewed:" + token, timestamp, item);
// 移除旧的记录,只保留用户最近浏览过的25个商品。
conn.zremrangeByRank("viewed:" + token, 0, -26);
conn.zincrby("viewed:", -1, item);
}
}
清理令牌
上一节提到,更新令牌时,将令牌和当前时间戳的映射关系,存入一个 ZSET 结构中。所以可以通过排序得知哪些令牌最老。如果没有清理操作,更新令牌占用的内存会不断膨胀,直到导致机器宕机。
比如:最多允许存储 1000 万条令牌信息,周期性检查,一旦发现记录数超出 1000 万条,将 ZSET 从新到老排序,将超出 1000 万条的记录清除。
public static class CleanSessionsThread extends Thread {
private Jedis conn;
private int limit;
private volatile boolean quit;
public CleanSessionsThread(int limit) {
this.conn = new Jedis("localhost");
this.conn.select(15);
this.limit = limit;
}
public void quit() {
quit = true;
}
@Override
public void run() {
while (!quit) {
// 找出目前已有令牌的数量。
long size = conn.zcard("recent:");
// 令牌数量未超过限制,休眠并在之后重新检查。
if (size <= limit) {
try {
sleep(1000);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
continue;
}
// 获取需要移除的令牌ID。
long endIndex = Math.min(size - limit, 100);
Set<String> tokenSet = conn.zrange("recent:", 0, endIndex - 1);
String[] tokens = tokenSet.toArray(new String[tokenSet.size()]);
// 为那些将要被删除的令牌构建键名。
ArrayList<String> sessionKeys = new ArrayList<String>();
for (String token : tokens) {
sessionKeys.add("viewed:" + token);
}
// 移除最旧的那些令牌。
conn.del(sessionKeys.toArray(new String[sessionKeys.size()]));
conn.hdel("login:", tokens);
conn.zrem("recent:", tokens);
}
}
}