分布式治理面试
分布式治理面试
链路追踪
【中等】如何实现链路追踪?⭐⭐
链路追踪是一种分布式系统的可观测性技术,用于记录一次请求在多个服务间的完整调用路径、调用耗时以及执行状态,帮助开发者理解系统行为、定位性能瓶颈和排查故障。
核心概念
- Trace:一次完整的请求链路,由全局唯一的 TraceID 标识。
- Span:链路中的单个工作单元,记录一次远程调用或本地操作,包含 SpanID、ParentSpanID、开始/结束时间、标签等。
- 上下文传播:通过 HTTP 头、RPC 元数据等方式将 TraceID 和 SpanID 透传给下游服务,实现调用链串联。
实现原理
- 埋点:在服务框架或业务代码中植入追踪 SDK,自动拦截 RPC 调用、HTTP 请求、数据库访问等关键操作,创建 Span。
- 采样:为避免性能开销,通常采用采样策略(如固定概率采样、动态采样),只记录部分请求的链路数据。
- 传输:追踪数据异步上报至 Collector(收集器),常用协议有 gRPC、Thrift、HTTP。
- 存储:Collector 将数据存入后端存储(如 Elasticsearch、Cassandra、HBase)。
- 展示:UI 服务提供查询界面,展示调用拓扑图和 Span 详情。
关键难点与对策
- 低侵入性:利用 Java Agent 字节码增强(如 SkyWalking)或框架拦截器(如 Spring Cloud Sleuth)实现无代码侵入。
- 低延迟:采样、异步上报、本地缓冲区,避免阻塞业务线程。
- 采样策略:固定概率采样简单但可能漏掉重要请求;动态采样根据流量自适应;头部采样可保证完整链路。
- 上下文传播:需支持多种协议(HTTP/gRPC/消息队列)的透传,处理异步线程传递(如 ThreadLocal 与线程池的兼容)。
- 存储压力:链路数据量大,需设计合理索引、TTL、降采样。
主流方案对比
- SkyWalking:Java Agent 探针,无代码侵入,支持多种语言,UI 功能强大,社区活跃。
- Zipkin:Twitter 开源,基于 Brave 库埋点,支持多种存储,轻量级。
- Jaeger:Uber 开源,受 Dapper 和 OpenZipkin 启发,原生支持 OpenTracing,适合云原生环境。
- Pinpoint:基于字节码注入,功能全面,但部署较重,依赖 HBase。
实践要点
- 采样率配置:生产环境一般 1%-10%,根据流量调整。
- 存储选型:ES 适合快速检索,但成本较高;Cassandra 适合高写入。
- 与日志、指标联动:在日志中打印 TraceID,实现链路与日志的关联;聚合 Span 数据生成服务拓扑和性能指标。
- 告警:基于链路错误率、延迟分位数设置告警。
配置中心
【简单】什么是配置中心?
配置中心核心作用
| 作用 | 说明 |
|---|---|
| 集中管理 | 所有服务配置统一存放,告别配置文件散落 |
| 动态更新 | 修改配置无需重启,实时生效 |
| 环境隔离 | 开发/测试/生产环境配置分离 |
| 版本追溯 | 配置变更可回滚、可审计 |
| 权限控制 | 配置修改需审批,防误操作 |
配置中心应用场景
- 开关控制:功能灰度、降级开关
- 参数调优:线程池大小、超时时间
- 业务规则:黑名单、费率配置
- 数据库连接:动态切换数据源
【困难】如何实现一个配置中心?⭐
配置存储方式
- 数据库:如 MySQL,存储结构化配置(表:namespace、key、value、版本、环境等)
- Git:配置文件版本化管理(Spring Cloud Config)
- 分布式 KV 存储:etcd/ZooKeeper,利用其强一致性和 watch 机制
- 本地文件:测试环境或简单场景
动态更新与通知
- 长轮询:客户端发起请求,服务端有变更立即返回,否则 hold 住请求一段时间
- 长连接:WebSocket 或 gRPC 流,服务端主动推送变更
- 对比版本号:客户端定期拉取对比本地版本,有变化则更新
- 消息广播:配置变更后,通过消息队列通知所有客户端
环境隔离
- Namespace/Group:逻辑隔离,如 dev、test、prod(Apollo 的 namespace)
- 独立数据库/表:不同环境使用不同数据库或表前缀
- Git 分支:不同环境对应不同分支(Spring Cloud Config)
- 配置文件命名:
application-dev.yml,application-prod.yml
灰度发布
- 按 IP/机器:指定某些实例优先应用新配置
- 按标签/用户:根据请求头或用户 ID 灰度
- 百分比灰度:逐步放量,监控稳定后全量
- 配置中心支持:如 Apollo 的灰度发布,先推送到灰度实例,验证后再全量
版本管理与回滚
- 版本号:每次修改生成新版本号,记录历史
- 历史记录表:存储每次变更的旧值、新值、操作人、时间
- 回滚操作:选择历史版本,将当前配置重置为指定版本
- 发布审批:重要配置修改需审批,避免误操作
减少客户端访问频率
- 本地缓存:客户端拉取配置后缓存到内存,减少网络请求
- 定期刷新:设置缓存过期时间(如 30 秒),到期后异步拉取
- 长轮询/长连接:变更时服务端主动通知,避免频繁轮询
DevOps
【简单】什么是灰度发布、金丝雀部署以及蓝绿部署?
- 金丝雀部署是实例维度的灰度,关注部署过程的安全
- 灰度发布是流量维度的控制,关注用户感知的平滑
- 蓝绿部署是环境维度的切换,关注切换速度与回滚能力
三者可组合使用,如先蓝绿部署,再通过金丝雀逐步切流。
灰度发布
灰度发布是一种平滑过渡的发布方式,指让部分用户继续使用旧版本,部分用户开始使用新版本,如果新版本运行稳定,则逐步扩大新版本范围,直至全部切换为新版本。
核心机制:
- 按流量比例或特定条件(如地域、用户标签)逐步放量
- 实时监控新版本运行状态,发现问题可随时回切
- 新旧版本同时在线,用户无感知
适用场景:功能迭代、AB测试、降低发布风险
金丝雀发布
金丝雀部署是灰度发布的一种具体实现方式,得名于“煤矿中的金丝雀”用于预警危险。
核心机制:
- 先部署少量新版本实例(金丝雀),仅引入一小部分流量
- 验证金丝雀实例的稳定性、性能、业务逻辑
- 确认无误后,逐步替换剩余旧版本实例
关键特征:先小范围验证,再滚动替换。与灰度发布的区别在于,金丝雀通常指实例级别的分批替换,而灰度更强调流量控制。
蓝绿发布
蓝绿部署是一种零停机发布策略,通过维护两套独立的环境(蓝环境、绿环境)来实现快速切换。
核心机制:
- 蓝环境:当前生产环境,运行旧版本
- 绿环境:新版本部署环境,完全独立
- 绿环境验证通过后,通过路由切换(如负载均衡器)将所有流量从蓝瞬间切换到绿
- 蓝环境作为备份,若发现问题可立即切回
关键特征:瞬间切换、快速回滚、环境完全隔离。
核心区别
| 维度 | 灰度发布 | 金丝雀部署 | 蓝绿部署 |
|---|---|---|---|
| 核心思想 | 逐步放量 | 先验证再替换 | 环境切换 |
| 流量切换 | 逐步调整比例 | 随实例替换自然迁移 | 瞬间全量切换 |
| 回滚方式 | 逐步减少新版本流量 | 重新部署旧版本 | 切回原环境 |
| 资源消耗 | 适中 | 适中 | 高(需双倍资源) |
| 适用场景 | 功能发布、AB测试 | 滚动升级、风险验证 | 核心系统、版本大升级 |
网关
【简单】什么是网关?⭐⭐
网关是连接不同网络或协议的入口节点,提供了流量入口统一管理的能力。
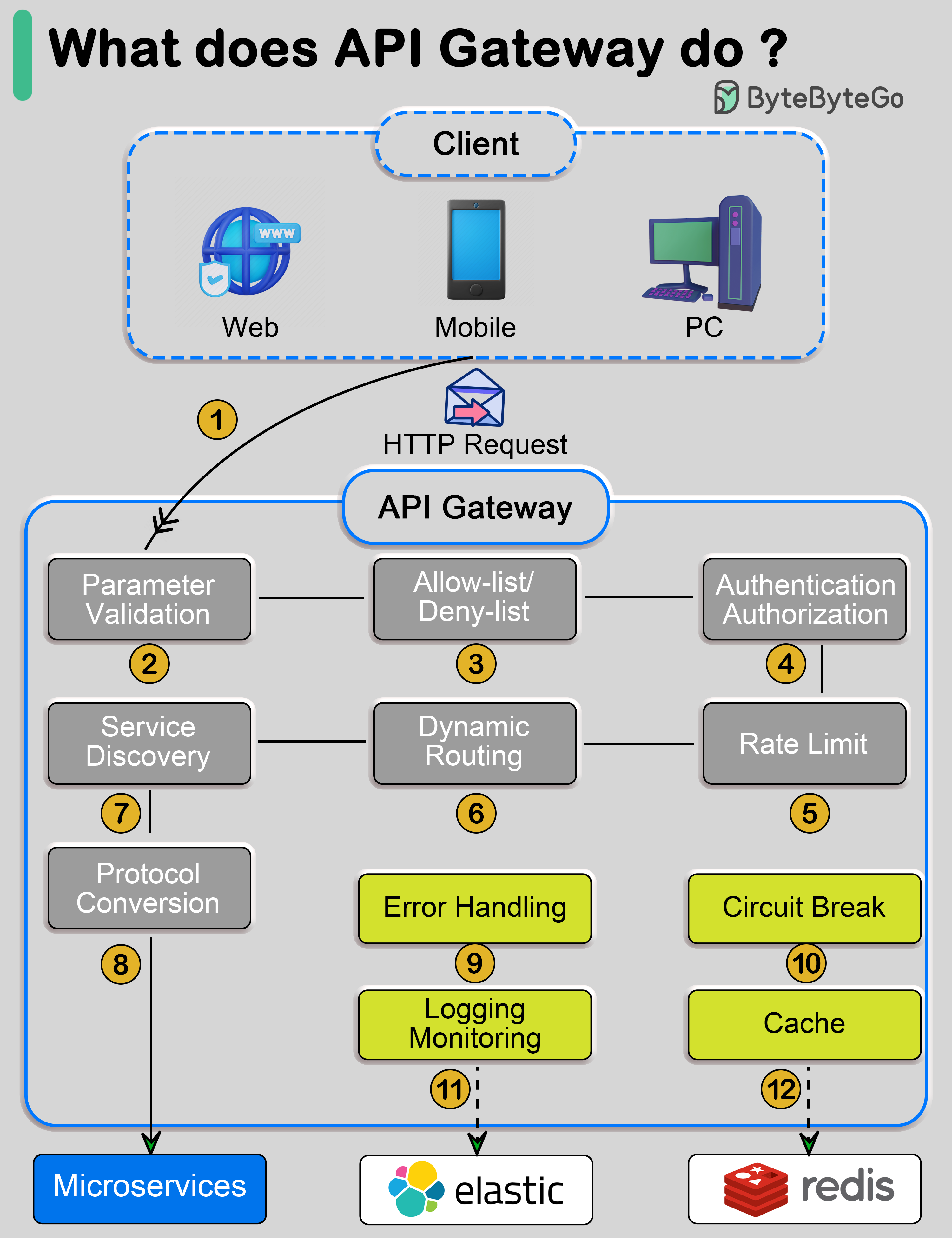
网关的核心功能大致如下:
- 请求代理/反向代理:客户端向 API 网关发送 HTTP 请求。
- 安全防护:跨域(cors)、防 XSS 攻击、IP 黑白名单、WAF 规则、请求体大小限制、风控等。
- 认证授权:支持 JWT、OAuth2、API 等认证方式,统一进行身份认证和权限控制。
- 流量控制:对请求应用速率限制规则。如果超过限制,请求将被拒绝。
- 动态路由:根据请求路径、Host、Header、JWT claim 等信息灵活匹配到上游服务,不重启即可更新路由规则。
- 负载均衡: 将请求均匀分布到多个服务器。
- 缓存:暂时存储响应,减少重复处理的需求。
- 协议转换:API 网关将请求转换为相应协议,并发送到后端微服务。
- 可观测:对请求进行埋点,采集日志、指标、链路监控数据,以便于全方位监控。
【中等】网关如何技术选型?
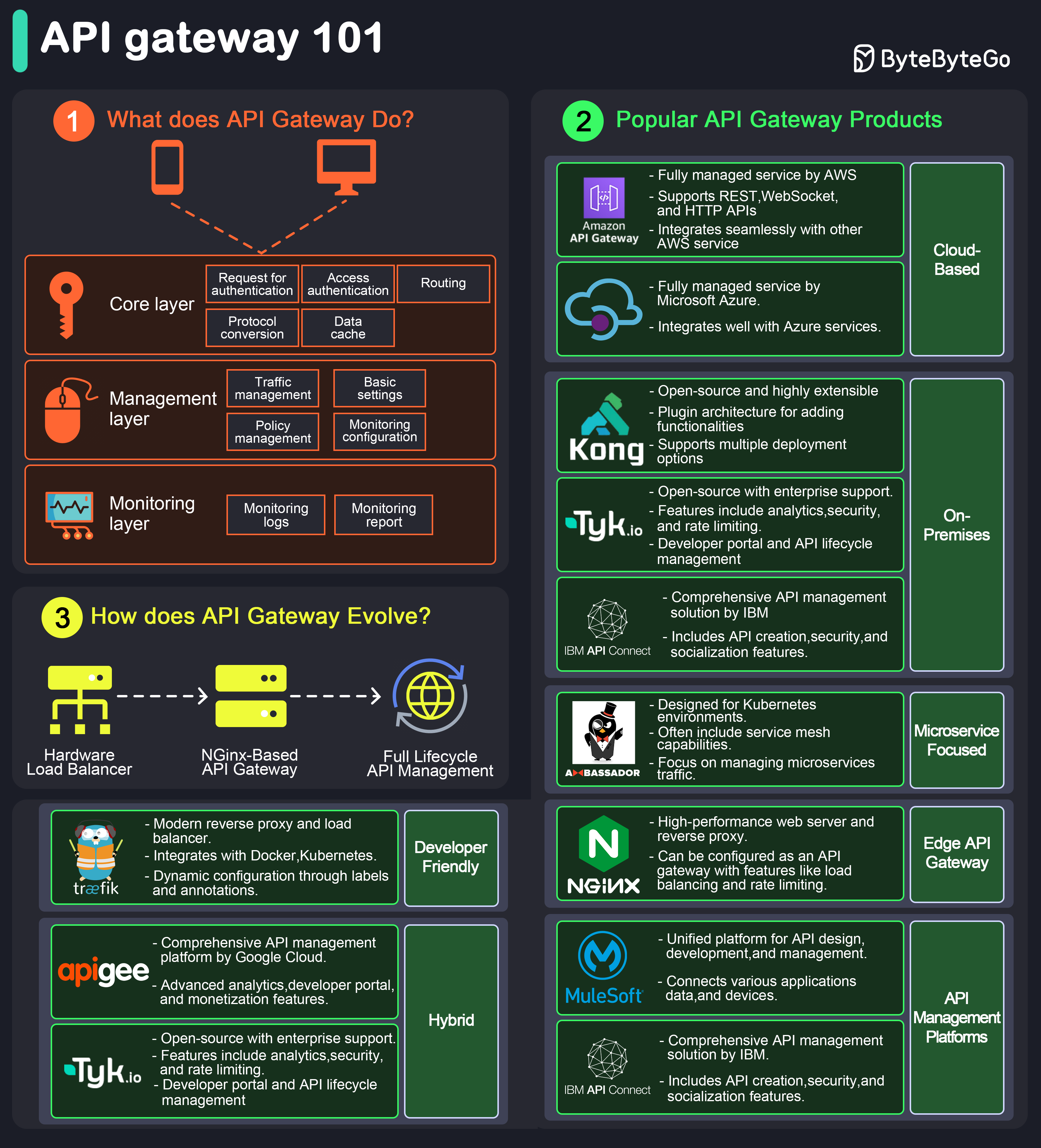
主流网关方案对比:
| 网关 | 核心特点 | 优势 | 适用场景 |
|---|---|---|---|
| Kong | 基于 Nginx + Lua,插件丰富 | 300+社区插件,生态好 | 云原生、需要灵活扩展 |
| APISIX | 国产高性能,支持 WASM 插件 | 动态路由,性能优异 | 高并发、国产化 |
| Spring Cloud Gateway | Java 生态,Reactive 编程 | 与 Spring Boot 无缝集成 | Java 技术栈微服务 |
| Nginx | 成熟稳定,高吞吐 | 10 万+RPS,内存占用低 | 传统架构、静态内容 |
| Envoy | 云原生,xDS 动态配置 | 低延迟,服务网格集成 | K8s 环境、Istio 配合 |
| Traefik | 自动服务发现 | 配置简单,原生支持 K8s | K8s 原生环境 |
| 云厂商网关 | 全托管免运维 | 99.99%SLA,安全集成 | 上云首选、Serverless |
选型建议:
- Java 技术栈 → Spring Cloud Gateway
- K8s 原生 → Traefik 或 Envoy+Istio
- 高并发插件生态 → Kong 或 APISIX
- 不想运维 → 云厂商 API 网关
- 简单可靠 → Nginx
【中等】网关如何实现 API 版本管理?
版本管理方式
| 方式 | 原理 | 示例 | 特点 | 适用场景 |
|---|---|---|---|---|
| URI 路径 | 版本号在 URL 路径中 | /v1/orders /v2/orders | 最直观、缓存友好 | 最常用,清晰直观 |
| 请求参数 | 版本号在 Query 参数 | /orders?version=1 | 优点是 URL 路径干净 缺点是缓存命中率低 | 简单临时场景 |
| Header 头 | 版本号在自定义 Header | Accept-Version: v1 | 版本参数容易和业务参数混在一起 CDN 缓存也容易污染 | 保持 URI 整洁 |
| 域名 | 不同版本用不同域名 | v1.api.com v2.api.com | 隔离性强,运维复杂 | 大规模版本隔离 |
版本兼容性原则
| ✅ 兼容(无需新版本) | ❌ 不兼容(必须新版本) |
|---|---|
| 新增可选字段 | 删除字段/接口 |
| 扩展现有枚举 | 修改字段类型/名称 |
| 放宽输入约束 | 修改必填字段 |
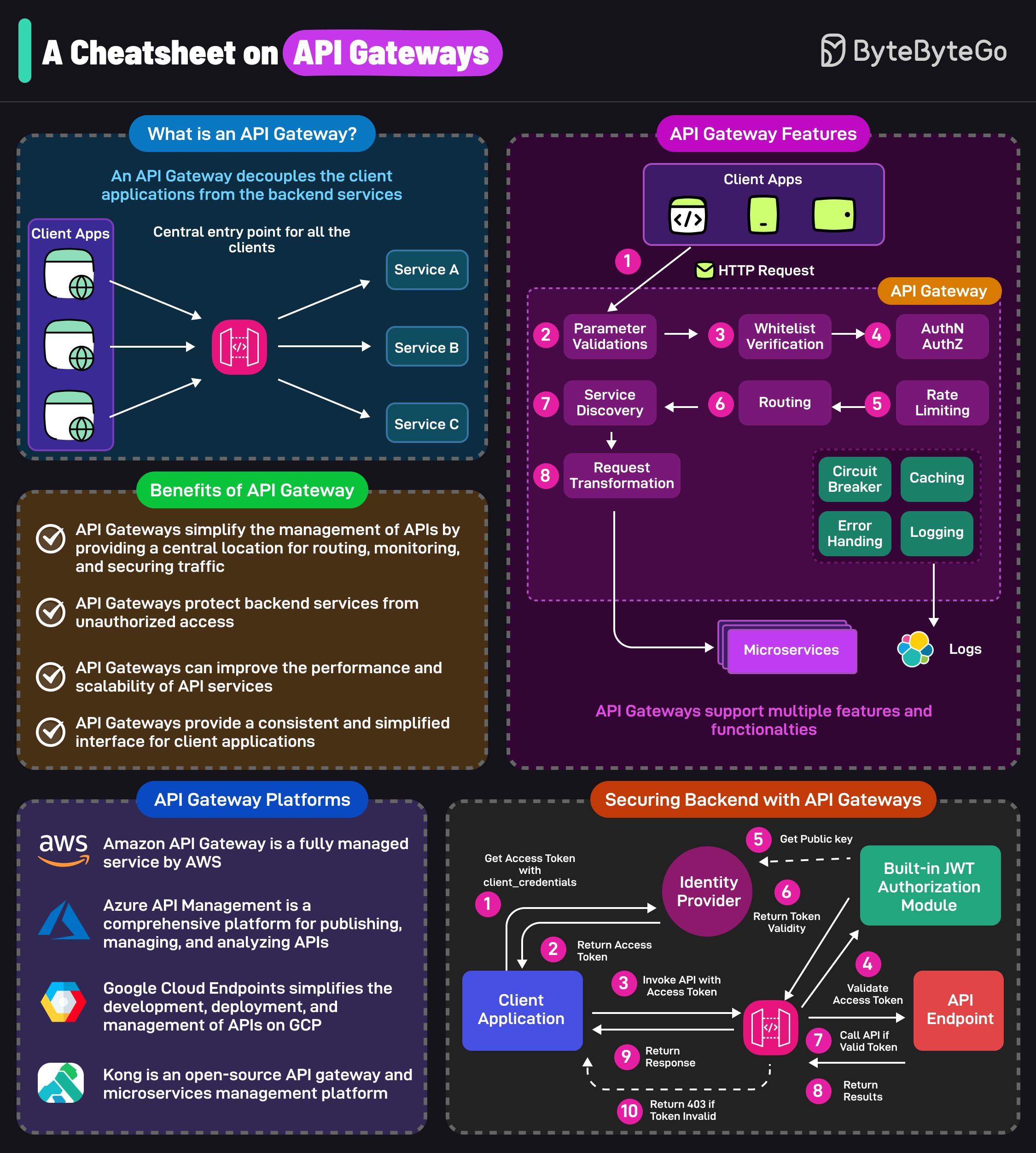
服务网格
【简单】什么是服务网格?
服务网格是基础设施层的一个专用层,用于处理服务间通信,其核心特点是将服务治理能力(如服务发现、负载均衡、熔断、可观测性)从业务代码中下沉到由轻量级网络代理组成的中间层。
服务网格通常由数据平面和控制平面构成。
- 数据平面
- 由一组与业务容器并行运行的网络代理组成,通常采用Sidecar模式部署。
- 每个代理拦截对应服务的所有进出流量,执行路由、负载均衡、认证、监控等功能,而对业务容器本身无侵入。
- 控制平面
- 管理并配置数据平面的代理,下发统一的策略和规则。
- 提供服务发现、配置管理、证书签发、访问控制等能力,并聚合来自代理的遥测数据。
核心优势
- 治理下沉,业务无感:服务治理能力从代码中剥离,开发者只需关注业务逻辑,升级治理能力无需修改代码。
- 多语言支持:Sidecar代理独立于业务应用,任何语言开发的服务都可获得统一的治理能力。
- 精细化流量管控:支持根据权重、Header、路径等条件进行灰度发布、A/B测试和金丝雀发布。
- 可观测性增强:自动收集服务拓扑、指标、日志和链路追踪数据。
- 安全加固:提供服务间的双向TLS加密、细粒度的访问控制策略。
与现有技术的关系
- 对比传统微服务框架:Spring Cloud等框架将治理能力集成在SDK中,对业务有侵入,且多语言支持困难。服务网格将能力剥离到独立代理层。
- 与Kubernetes的关系:服务网格通常运行在Kubernetes之上,利用其调度能力部署Sidecar。K8s解决了容器编排问题,服务网格解决了Pod间的通信治理问题。
主流产品
- Istio:目前最流行的服务网格,功能丰富,生态强大,但复杂度较高。
- Linkerd:专注于轻量、简单和高性能,对Kubernetes原生支持好。
- Consul Connect:由HashiCorp推出,与Consul服务发现生态深度集成。
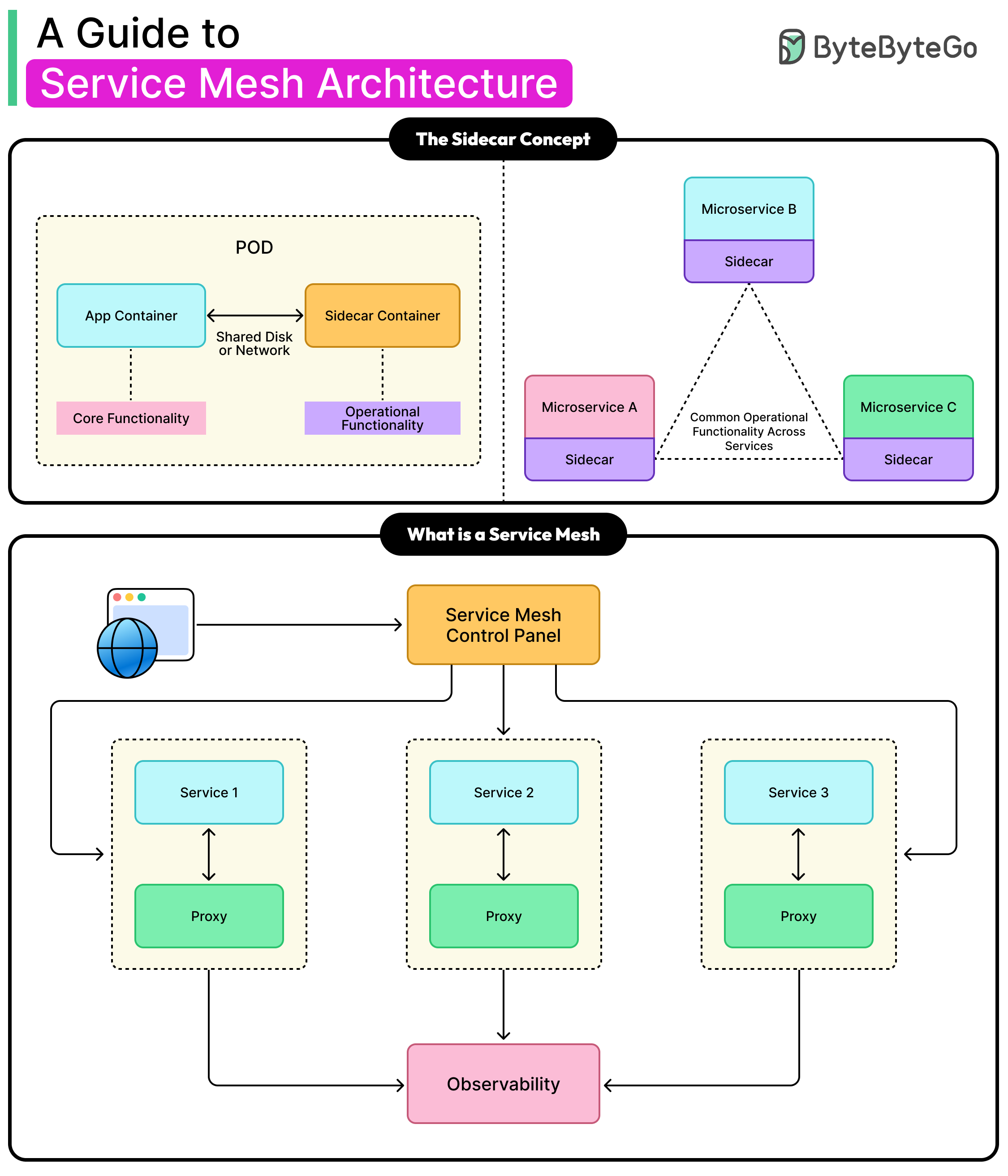
【简单】什么是 Sidecar?
Sidecar 是一种部署设计模式,指在应用程序容器旁边启动一个辅助进程,两者共享相同的生命周期和网络命名空间。
核心工作原理
- 辅助进程作为本地代理,拦截进出主应用的所有网络流量。
- 主应用对 Sidecar 无感知,所有服务治理逻辑(如服务发现、负载均衡、熔断、监控)都在 Sidecar 中执行。
- 应用只需关注业务代码,Sidecar 负责处理分布式系统通信的复杂问题。
在服务网格中的角色
- Sidecar 构成了服务网格的数据平面,每个服务实例伴生一个 Sidecar 代理。
- 所有服务间调用都通过双方的 Sidecar 完成,形成去中心化的网状通信架构。
- 控制平面统一配置所有 Sidecar,实现全局一致的治理策略。
核心价值
- 业务无侵入:治理能力从代码中剥离,开发者无需关注底层通信细节。
- 多语言友好:Sidecar 独立于应用,任何语言开发的服务都能获得相同的治理能力。
- 统一管控:所有服务的行为可通过控制平面集中配置,无需逐个修改业务代码。
- 可观测性增强:Sidecar 自动采集流量指标、日志和链路数据。
【中等】服务网格 vs. 网关?
网关和服务网格虽然都用于管理服务通信,但它们解决的问题和所处的架构层级有本质区别。
网关是系统的门户,负责与外部的交互;服务网格是系统的血管,负责内部通信的治理。

核心区别
| 维度 | 网关 | 服务网格 |
|---|---|---|
| 流量方向 | 处理南北向流量(外部请求进入内部系统) | 处理东西向流量(内部服务之间的相互调用) |
| 部署位置 | 部署在系统边界,作为整个集群或业务域的单一入口 | 以 Sidecar 模式伴随每个服务实例部署,形成网状结构 |
| 治理粒度 | 粗粒度,关注外部请求的路由、认证、限流 | 细粒度,关注每个服务间调用的重试、超时、熔断、加密 |
| 功能范围 | 协议转换、请求聚合、IP黑白名单、防爬虫等 | 服务发现、负载均衡、可观测性、mTLS、访问控制 |
| 变更影响 | 变更可能影响所有流入的流量,需谨慎操作 | 变更由控制平面下发,影响范围可控,对业务无感 |
逻辑关系
在典型微服务架构中,两者通常协同工作,并非替代关系:
- 入口处:所有外部请求先到达网关,由网关完成全局的认证、流控后,再路由到具体的后端服务。
- 内部调用:当服务A需要调用服务B时,流量被其伴生的Sidecar代理拦截,服务网格根据控制平面下发的策略处理这次调用(如选择实例、记录指标、自动重试)。
设计理念差异
- 网关是集中的:它是一个节点或一组节点,所有流量汇聚于此。
- 服务网格是分布的:治理能力被分散到每个服务旁边,形成无处不在的智能代理。
参考资料
- 数据密集型应用系统设计 - 这可能是目前最好的分布式存储书籍,强力推荐【进阶】