
Redis 面试之数据类型篇
Redis 数据类型
【简单】Redis 支持哪些数据类型?
- Redis 支持五种基本数据类型:String(字符串)、Hash(哈希)、List(列表)、Set(集合)、Zset(有序集合)。
- 随着 Redis 版本升级,又陆续支持以下数据类型: BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。

【简单】Redis 基础数据类型的常见命令有哪些?
String 命令
| 命令 | 说明 |
|---|---|
SET | 存储一个字符串值 |
SETNX | 仅当键不存在时,才存储字符串值 |
GET | 获取指定 key 的值 |
MGET | 获取一个或多个指定 key 的值 |
INCRBY | 将 key 中储存的数字加上指定的增量值 |
DECRBY | 将 key 中储存的数字减去指定的减量值 |
Hash 命令
| 命令 | 行为 |
|---|---|
HSET | 将指定字段的值设为 value |
HGET | 获取指定字段的值 |
HGETALL | 获取所有键值对 |
HMSET | 设置多个键值对 |
HMGET | 获取所有指定字段的值 |
HDEL | 删除指定字段 |
HINCRBY | 为指定字段的整数值加上增量 |
HKEYS | 获取所有字段 |
List 命令
| 命令 | 行为 |
|---|---|
LPUSH | 将给定值推入列表的右端。 |
RPUSH | 将给定值推入列表的右端。 |
LPOP | 从列表的左端弹出一个值,并返回被弹出的值。 |
RPOP | 从列表的右端弹出一个值,并返回被弹出的值。 |
LRANGE | 获取列表在给定范围上的所有值。 |
LINDEX | 获取列表在给定位置上的单个元素。 |
LREM | 从列表的左端弹出一个值,并返回被弹出的值。 |
LTRIM | 只保留指定区间内的元素,删除其他元素。 |
Set 命令
| 命令 | 行为 |
|---|---|
SADD | 将给定元素添加到集合。 |
SMEMBERS | 返回集合包含的所有元素。 |
SISMEMBER | 检查给定元素是否存在于集合中。 |
SREM | 如果给定的元素存在于集合中,那么移除这个元素。 |
Zset 命令
| 命令 | 行为 |
|---|---|
ZADD | 将一个带有给定分值的成员添加到有序集合里面 |
ZRANGE | 顺序排序,并返回指定排名区间的成员 |
ZREVRANGE | 反序排序,并返回指定排名区间的成员 |
ZRANGEBYSCORE | 顺序排序,并返回指定排名区间的成员及其分值 |
ZREVRANGEBYSCORE | 反序排序,并返回指定排名区间的成员及其分值 |
ZREM | 移除指定的成员 |
ZSCORE | 返回指定成员的分值 |
ZCARD | 返回所有成员数 |
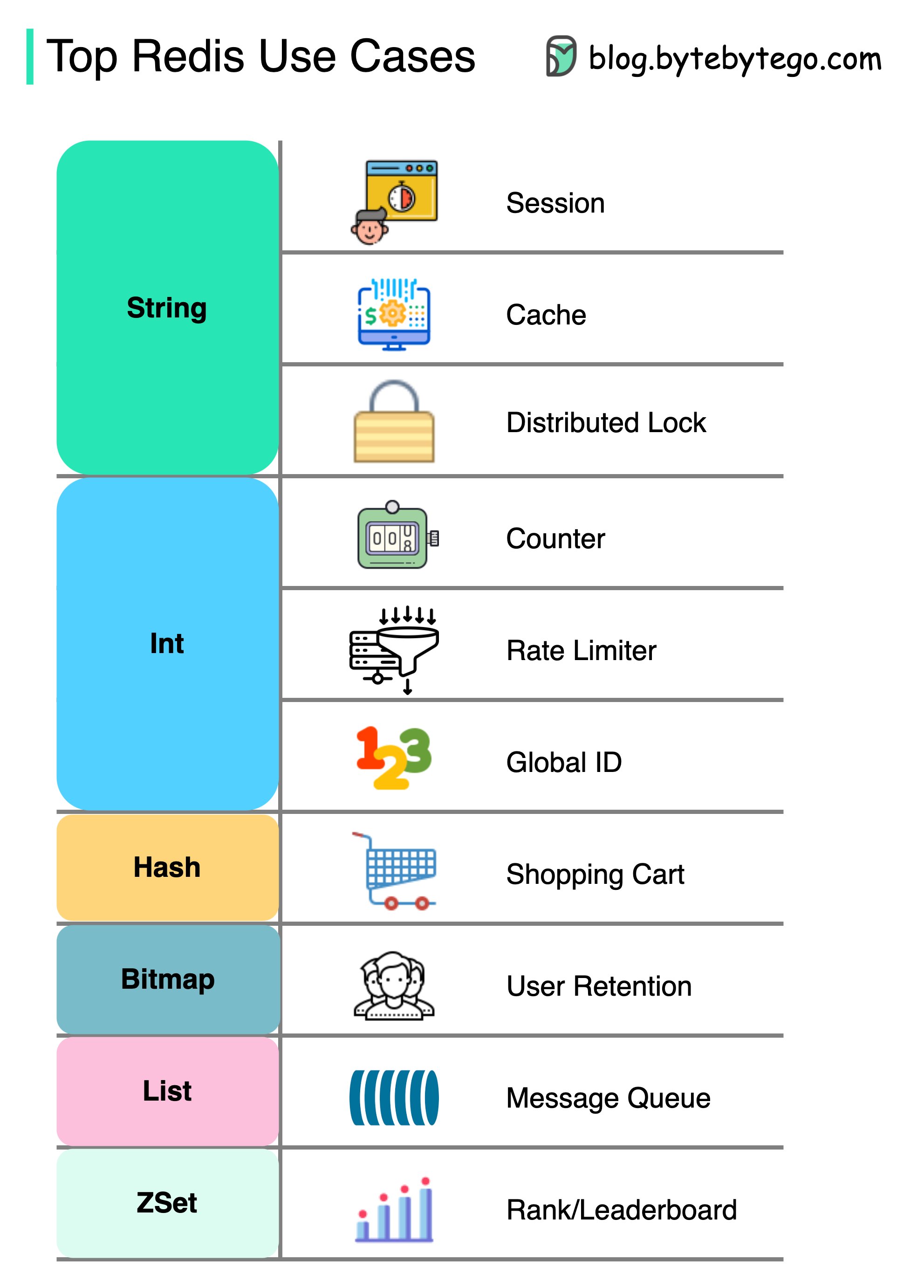
【中等】Redis 各数据类型的应用场景?
- String(字符串) - 缓存对象、分布式 Session、分布式锁、计数器、限流器、分布式 ID 等。
- Hash(哈希) - 缓存对象、购物车等。
- List(列表) - 消息队列
- Set(集合) - 聚合计算(并集、交集、差集),如点赞、共同关注、抽奖活动等。
- Zset(有序集合) - 排序场景,如排行榜、电话和姓名排序等。
- BitMap(2.2 版新增) - 二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增) - 海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增) - 存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增) - 消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息 ID,支持以消费组形式消费数据。
【困难】Redis 基础数据类型的底层实现是怎样的?

- String 类型 - String 类型的底层数据结构是 SDS。SDS 是 Redis 针对字符串类型的优化,具有以下特性:
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 减少修改字符串长度时所需的内存重分配次数
- List 类型 - 列表对象的编码可以是
ziplist或者linkedlist。当列表对象可以同时满足以下两个条件时,列表对象使用ziplist编码;否则,使用linkedlist编码。- 列表对象保存的所有字符串元素的长度都小于
64字节; - 列表对象保存的元素数量小于
512个;
- 列表对象保存的所有字符串元素的长度都小于
- Hash 类型 - 哈希对象的编码可以是
ziplist或者hashtable。当哈希对象同时满足以下两个条件时,使用ziplist编码;否则,使用hashtable编码。- 哈希对象保存的所有键值对的键和值的字符串长度都小于
64字节; - 哈希对象保存的键值对数量小于
512个;
- 哈希对象保存的所有键值对的键和值的字符串长度都小于
- Set 类型 - 集合对象的编码可以是
intset或者hashtable。当集合对象可以同时满足以下两个条件时,集合对象使用intset编码;否则,使用hashtable编码。- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过
512个;
- Zset 类型 - 有序集合的编码可以是
ziplist或者skiplist。当有序集合对象可以同时满足以下两个条件时,有序集合对象使用ziplist编码;否则,使用skiplist编码。- 有序集合保存的元素数量小于
128个; - 有序集合保存的所有元素成员的长度都小于
64字节;
- 有序集合保存的元素数量小于
【困难】Redis 为什么用 listpack 替代 ziplist?
listpack 是 Redis 5.0 引入的优化结构,用来替代 ziplist,作为 hash、list、zset 数据类型的实现编码之一。
二者对比如下:
| 特性 | ziplist | listpack |
|---|---|---|
| 级联更新 | 可能发生(最坏 O(n)) | 完全避免(稳定 O(1)) |
| 内存占用 | 预留空间可能浪费 | 按需分配,更紧凑 |
| 安全性 | 需手动校验边界 | 内置长度校验,防溢出 |
| 版本 | Redis 旧版本 | Redis 5.0+ 的 Hash、ZSet 等 |
ziplist 的缺陷
- 级联更新问题 - 当修改或删除中间某个元素时,可能引发后续所有节点的内存重分配(因为
ziplist用 前驱节点长度 定位数据)。最坏情况下时间复杂度从O(1)退化到O(n),影响性能。 - 内存浪费 -
ziplist为每个节点预留 1~5 字节 存储前驱节点长度(即使实际不需要这么多空间)。对于短小的数据(如小整数),存储开销比例过高。 - 安全性风险 -
ziplist对内存布局的强依赖可能导致 缓冲区溢出(需严格校验边界)。
listpack 的改进
- 消除级联更新 - 每个节点 独立存储自身长度(不再依赖前驱节点)。修改任意节点仅影响当前节点,时间复杂度稳定为
O(1)。 - 更紧凑的内存布局 - 节点长度字段采用 变长编码(类似 Protobuf 的 Varint),根据实际需求分配 1~5 字节。存储小整数时,长度字段仅需 1 字节。
- 更强的安全性 - 每个节点记录 总长度 和 校验字段,避免解析越界。
- 兼容性与平滑替换 -
listpack的 API 设计兼容ziplist,Redis 内部可无缝迁移(如 Hash、ZSet 的底层实现)。
【困难】为什么 Zset 用跳表实现而不是红黑树、B+树?
- 实现简单性
- 跳表的实现比红黑树简单得多,代码更易于维护和调试。
- 红黑树需要处理复杂的旋转和重新平衡操作,而跳表的平衡是通过概率实现的。
- 范围查询效率
- 跳表在范围查询(如
zrange)上表现优异,因为它是基于链表的结构,可以线性遍历。 - 红黑树进行范围查询需要中序遍历,相对复杂。
- B+树虽然也擅长范围查询,但实现复杂度更高。
- 跳表在范围查询(如
- 并发性能
- 跳表更容易实现无锁并发操作 (Redis 虽然是单线程,但考虑未来扩展)
- 红黑树的平衡操作涉及大量指针修改,难以实现高效的并发控制
- 内存效率
- 跳表不需要像 B+ 树那样维护严格的树形结构,内存使用更灵活
- B+树的节点通常设计为填满一定比例,可能造成内存浪费
- 性能平衡
- 跳表的查询、插入、删除操作时间复杂度都是 O(logN),与红黑树相当
- 跳表的实际性能在实践中表现良好,特别是对于内存数据结构
- Redis 的特殊需求
- Redis 的 Zset 需要同时支持按 score 和按 member 查询,跳表+哈希表的组合完美满足这一需求
- Redis 是内存数据库,不需要考虑 B+树针对磁盘 I/O 优化的特性
【困难】跳表的实现原理是什么?
跳表是一种可以实现二分查找的有序链表,通过多级索引提升查找效率。跳表的查找、插入、删除操作的时间复杂度均为 O(log n),与平衡二叉树(如红黑树)接近。
对于一个有序数组,可以使用高效的二分查找法,其时间复杂度为 O(log n)。
但是,即使是有序的链表,也只能使用低效的顺序查找,其时间复杂度为 O(n)。

如何提高链表的查找效率呢?
我们可以对链表加一层索引。具体来说,可以每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引或索引层。索引节点中通过一个 down 指针,指向下一级结点。通过这样的改造,就可以支持类似二分查找的算法。我们把改造之后的数据结构叫作跳表(Skip list)。
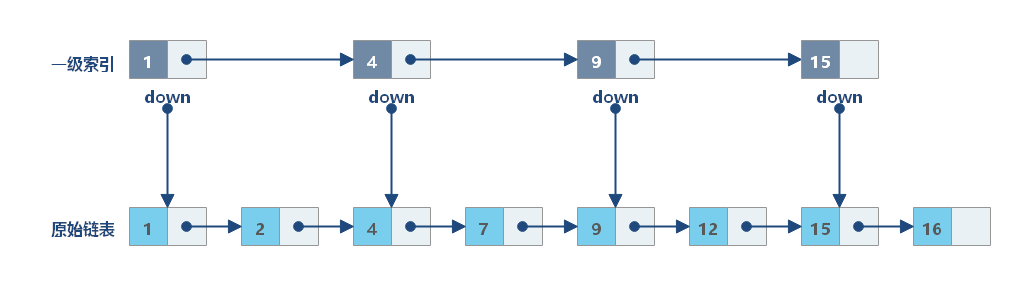
随着数据的不断增长,一级索引层也变得越来越长。此时,我们可以为一级索引再增加一层索引层:二级索引层。
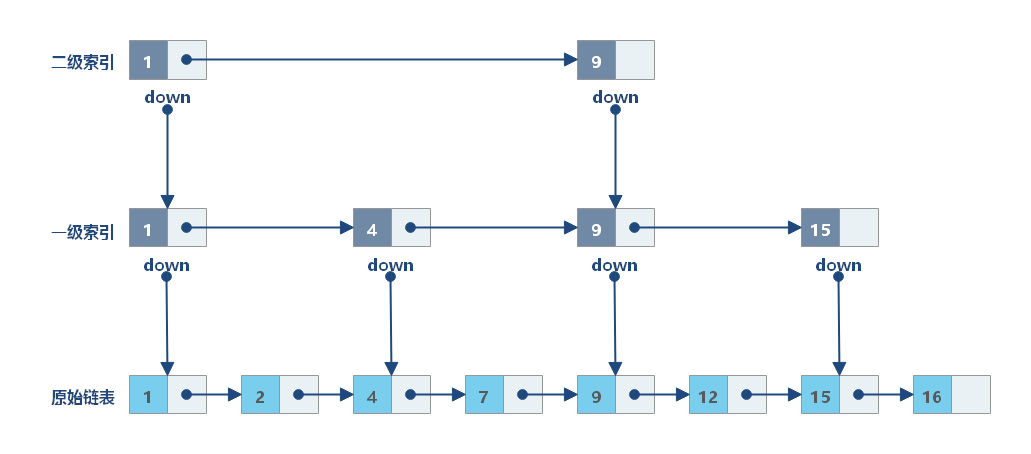
随着数据的膨胀,当二级索引层也变得很长时,我们可以继续为其添加新的索引层。这种链表加多级索引的结构,就是跳表。
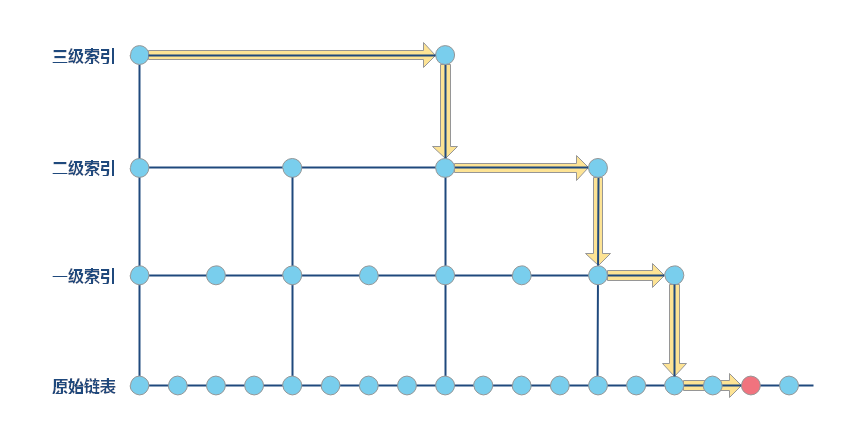
跳表的时间复杂度
- 查找:从最高级索引开始逐层下沉,每层最多遍历 3 个节点,时间复杂度为
O(log n)。 - 插入:先查找插入位置(
O(log n)),再随机生成索引层级(O(log n)),总时间复杂度为O(log n)。 - 删除:类似查找过程,删除节点及其索引(
O(log n))。
跳表的空间复杂度
- 索引节点总数为
n/2 + n/4 + n/8 + … ≈ n,空间复杂度为 O(n)。 - 可通过调整索引密度(如每 3 个节点抽 1 个)减少空间占用,但会牺牲部分查找效率。
【困难】Redis 利用什么机制来实现各种数据结构?
Redis 并没有直接使用这些数据结构来实现键值对数据库, 而是基于这些数据结构创建了一个对象系统, 这个系统包含字符串对象、列表对象、哈希对象、集合对象和有序集合对象这五种类型的对象。
Redis 数据库中的每个键值对的键和值都是一个对象。Redis 共有字符串、列表、哈希、集合、有序集合五种类型的对象, 每种类型的对象至少都有两种或以上的编码方式, 不同的编码可以在不同的使用场景上优化对象的使用效率。
服务器在执行某些命令之前, 会先检查给定键的类型能否执行指定的命令, 而检查一个键的类型就是检查键的值对象的类型。
对象的类型
Redis 使用对象来表示数据库中的键和值。每次当我们在 Redis 的数据库中新创建一个键值对时, 我们至少会创建两个对象, 一个对象用作键值对的键(键对象), 另一个对象用作键值对的值(值对象)。
Redis 中的每个对象都由一个 redisObject 结构表示, 该结构中和保存数据有关的三个属性分别是 type 属性、 encoding 属性和 ptr 属性:
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
对象的 type 属性记录了对象的类型,有以下类型:
| 对象 | 对象 type 属性的值 | TYPE 命令的输出 |
|---|---|---|
| 字符串对象 | REDIS_STRING | "string" |
| 列表对象 | REDIS_LIST | "list" |
| 哈希对象 | REDIS_HASH | "hash" |
| 集合对象 | REDIS_SET | "set" |
| 有序集合对象 | REDIS_ZSET | "zset" |
Redis 数据库保存的键值对来说, 键总是一个字符串对象, 而值则可以是字符串对象、列表对象、哈希对象、集合对象或者有序集合对象的其中一种。
对象的编码
对象的 ptr 指针指向对象的底层实现数据结构, 而这些数据结构由对象的 encoding 属性决定。
encoding 属性记录了对象所使用的编码, 也即是说这个对象使用了什么数据结构作为对象的底层实现。
Redis 中每种类型的对象都至少使用了两种不同的编码,不同的编码可以在不同的使用场景上优化对象的使用效率。
Redis 支持的编码如下所示:
| 类型 | 编码 | 对象 | OBJECT ENCODING 命令输出 |
|---|---|---|---|
REDIS_STRING | REDIS_ENCODING_INT | 使用整数值实现的字符串对象。 | "int" |
REDIS_STRING | REDIS_ENCODING_EMBSTR | 使用 embstr 编码的简单动态字符串实现的字符串对象。 | "embstr" |
REDIS_STRING | REDIS_ENCODING_RAW | 使用简单动态字符串实现的字符串对象。 | "raw" |
REDIS_LIST | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的列表对象。 | "ziplist" |
REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 使用双端链表实现的列表对象。 | "linkedlist" |
REDIS_HASH | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的哈希对象。 | "ziplist" |
REDIS_HASH | REDIS_ENCODING_HT | 使用字典实现的哈希对象。 | "hashtable" |
REDIS_SET | REDIS_ENCODING_INTSET | 使用整数集合实现的集合对象。 | "intset" |
REDIS_SET | REDIS_ENCODING_HT | 使用字典实现的集合对象。 | "hashtable" |
REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 使用压缩列表实现的有序集合对象。 | "ziplist" |
REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 使用跳表和字典实现的有序集合对象。 | "skiplist" |
内存回收
由于 C 语言不支持内存回收,Redis 内部实现了一套基于引用计数的内存回收机制。
每个对象的引用计数信息由 redisObject 结构的 refcount 属性记录。当对象的引用计数值变为 0 时, 对象所占用的内存会被释放。
对象共享
在 Redis 中, 让多个键共享同一个值对象需要执行以下两个步骤:
- 将数据库键的值指针指向一个现有的值对象;
- 将被共享的值对象的引用计数增一。
共享对象机制对于节约内存非常有帮助, 数据库中保存的相同值对象越多, 对象共享机制就能节约越多的内存。
Redis 会在初始化服务器时, 共享值为 0 到 9999
对象的空转时长
redisObject 的 lru 属性记录了对象最后一次被命令程序访问的时间。
如果服务器打开了 maxmemory 选项, 并且服务器用于回收内存的算法为 volatile-lru 或者 allkeys-lru , 那么当服务器占用的内存数超过了 maxmemory 选项所设置的上限值时, 空转时长较高的那部分键会优先被服务器释放, 从而回收内存。
【中等】如何使用 Redis 实现排行榜?
各种排行榜,如:内容平台(视频、歌曲、文章)的播放量/收藏量/评分排行榜;电商网站的销售排行榜等等,都可以基于 Redis zset 类型来实现。
我们以博文点赞排名为例,dunwu 发表了五篇博文,分别获得赞为 200、40、100、50、150。
# article:1 文章获得了 200 个赞
> ZADD user:dunwu:ranking 200 article:1
(integer) 1
# article:2 文章获得了 40 个赞
> ZADD user:dunwu:ranking 40 article:2
(integer) 1
# article:3 文章获得了 100 个赞
> ZADD user:dunwu:ranking 100 article:3
(integer) 1
# article:4 文章获得了 50 个赞
> ZADD user:dunwu:ranking 50 article:4
(integer) 1
# article:5 文章获得了 150 个赞
> ZADD user:dunwu:ranking 150 article:5
(integer) 1
文章 article:4 新增一个赞,可以使用 ZINCRBY 命令(为有序集合 key 中元素 member 的分值加上 increment):
> ZINCRBY user:dunwu:ranking 1 article:4
"51"
查看某篇文章的赞数,可以使用 ZSCORE 命令(返回有序集合 key 中元素个数):
> ZSCORE user:dunwu:ranking article:4
"50"
获取 dunwu 文章赞数最多的 3 篇文章,可以使用 ZREVRANGE 命令(倒序获取有序集合 key 从 start 下标到 stop 下标的元素):
# WITHSCORES 表示把 score 也显示出来
> ZREVRANGE user:dunwu:ranking 0 2 WITHSCORES
1) "article:1"
2) "200"
3) "article:5"
4) "150"
5) "article:3"
6) "100"
获取 dunwu 100 赞到 200 赞的文章,可以使用 ZRANGEBYSCORE 命令(返回有序集合中指定分数区间内的成员,分数由低到高排序):
> ZRANGEBYSCORE user:dunwu:ranking 100 200 WITHSCORES
1) "article:3"
2) "100"
3) "article:5"
4) "150"
5) "article:1"
6) "200"
【中等】如何使用 Redis 实现百万级网页 UV 计数?
Redis HyperLogLog 是 Redis 2.8.9 版本新增的数据类型,是一种用于“统计基数”的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%(统计结果为 100 万时,实际可能在 99.19 万~100.81 万之间)。
核心优势
- 极低内存占用:仅需 12 KB 内存,即可统计接近 2^64 个元素的基数(如 UV 统计)。
- 适合海量数据:相比
Set/Hash(元素越多内存消耗越大),HyperLogLog 在百万级以上数据场景中优势显著。
适用场景
- 网页 UV 统计:统计独立访客数(如
page1:uv),尤其适合高并发、大数据量场景。 - 容忍误差的基数统计:如热门活动页面访问量、广告点击去重等。
如果需要精确统计,则需要转用 Set / Hash,并且不得不消耗
基本命令
添加元素:
PFADD key element [element...]PFADD page1:uv user1 user2 user3 # 将用户添加到 UV 统计获取统计值:
PFCOUNT keyPFCOUNT page1:uv # 返回近似 UV 数(如 100 万)
【中等】如何使用 Redis 实现布隆过滤器?
布隆过滤器是一种高效的概率数据结构,常用于检测一个元素是否在一个集合中,可以有效减少数据库的查询次数,解决缓存穿透等问题。
可以通过以下两种方式实现布隆过滤器:
使用位图(Bitmap)实现布隆过滤器:
- 使用 Redis 的位图结构
SETBIT和GETBIT操作来实现布隆过滤器。位图本质上是一个比特数组,用于标识元素是否存在。 - 对于给定的数据,通过多个哈希函数计算位置索引,将位图中的相应位置设置为 1,表示该元素可能存在。
使用 RedisBloom 模块:
- Redis 提供了一个官方模块 RedisBloom,封装了哈希函数、位图大小等操作,可以直接用于创建和管理布隆过滤器。
- 使用
BF.ADD来向布隆过滤器添加元素,使用BF.EXISTS来检查某个元素是否可能存在。
BitMap
Bitmap,即位图,是一串连续的二进制数组(0 和 1),可以通过偏移量(offset)定位元素。由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。例如在一个系统中,不同的用户使用单调递增的用户 ID 表示。40 亿($$2^{32}$$ = $$410241024*1024$$ ≈ 40 亿)用户只需要 512M 内存就能记住某种状态,例如用户是否已登录。
实际上,BitMap 不是真实的数据结构,而是针对 String 实现的一组位操作。
由于 STRING 是二进制安全的,并且其最大长度是 512 MB,所以 BitMap 能最大设置 $$2^{32}$$ 个不同的 bit。
【示例】判断用户是否登录
Bitmap 提供了 GETBIT、SETBIT 操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。
只需要一个 key = login_status 表示存储用户登陆状态集合数据,将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过 GETBIT判断对应的用户是否在线。50000 万 用户只需要 6 MB 的空间。
假如我们要判断 ID = 10086 的用户的登陆情况:
第一步,执行以下指令,表示用户已登录。
SETBIT login_status 10086 1
第二步,检查该用户是否登陆,返回值 1 表示已登录。
GETBIT login_status 10086
第三步,登出,将 offset 对应的 value 设置成 0。
SETBIT login_status 10086 0
RedisBloom
RedisBloom 是 Redis 官方提供的模块,是一种简化的布隆过滤器实现。它提供了更高性能和更低误判率控制。
RedisBloom 常用命令
BF.RESERVE key error_rate capacity:创建布隆过滤器(指定误判率、容量)BF.ADD key item:添加元素BF.EXISTS key item:检查元素是否存在(可能误判)- 自动扩容:可动态调整数据结构以适应数据增长
RedisBloom 操作示例
创建:
BF.RESERVE myBloomFilter 0.01 1000000 # 误判率 1%,容量 100 万
添加元素:
BF.ADD myBloomFilter "item1"
检查元素:
BF.EXISTS myBloomFilter "item1" # 返回 1(可能存在)
BF.EXISTS myBloomFilter "item2" # 返回 0(一定不存在)
适用场景
RedisBloom 适合海量数据判断,且允许误判的场景:
- 爬虫:URL 去重
- 黑名单:反垃圾邮件(可能误杀)
- 分布式系统:优化数据查找(如 Hadoop、Cassandra)
- 推荐系统:避免重复推荐
核心特点
- 空间高效:节省存储空间
- 快速查询:O(1) 时间复杂度
- 误判率可控:通过参数调整