Elasticsearch 聚合
概述
在数据库中,聚合是指将数据进行分组统计,得到一个汇总的结果。例如,计算总和、平均值、最大值或最小值等操作。
Elasticsearch 将聚合分为三类:
| 类型 | 说明 |
|---|---|
| Metric(指标聚合) | 根据字段值进行统计计算 |
| Bucket(桶聚合) | 根据字段值、范围或其他条件进行分组 |
| Pipeline(管道聚合) | 对其他聚合输出的结果进行再次聚合 |
本文将逐一介绍这几种聚合方式的用法和特性。
聚合的用法
所有的聚合,无论它们是什么类型,都遵从以下的规则。
- 通过 JSON 来定义聚合计算,使用
aggregations或aggs来标记聚合计算。需要给每个聚合起一个名字,指定它的类型以及和该类型相关的选项。 - 它们运行在查询的结果之上。和查询不匹配的文档不会计算在内,除非你使用 global 聚集将不匹配的文档囊括其中。
- 可以进一步过滤查询的结果,而不影响聚集。
以下是聚合的基本结构:
"aggregations" : { <!-- 最外层的聚合键,也可以缩写为 aggs -->
"<aggregation_name>" : { <!-- 聚合的自定义名字 -->
"<aggregation_type>" : { <!-- 聚合的类型,指标相关的,如 max、min、avg、sum,桶相关的 terms、filter 等 -->
<aggregation_body> <!-- 聚合体:对哪些字段进行聚合,可以取字段的值,也可以是脚本计算的结果 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!-- 元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!-- 在聚合里面在定义子聚合 -->
}
[,"<aggregation_name_2>" : { ... } ]* <!-- 聚合的自定义名字 2 -->
}
- 在最上层有一个 aggregations 的键,可以缩写为 aggs。
- 在下面一层,需要为聚合指定一个名字。可以在请求的返回中看到这个名字。在同一个请求中使用多个聚合时,这一点非常有用,它让你可以很容易地理解每组结果的含义。
- 最后,必须要指定聚合的类型。
关于聚合分析的值来源,可以取字段的值,也可以是脚本计算的结果。
但是用脚本计算的结果时,需要注意脚本的性能和安全性;尽管多数聚集类型允许使用脚本,但是脚本使得聚集变得缓慢,因为脚本必须在每篇文档上运行。为了避免脚本的运行,可以在索引阶段进行计算。
此外,脚本也可以被人可能利用进行恶意代码攻击,尽量使用沙盒(sandbox)内的脚本语言。
【示例】根据 my-field 字段进行 terms 聚合计算
GET /my-index-000001/_search
{
"aggs": {
"my-agg-name": {
"terms": {
"field": "my-field"
}
}
}
}
响应结果:
{
"took": 78,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 1.0,
"hits": [...]
},
"aggregations": {
"my-agg-name": { // my-agg-name 聚合计算的结果
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": []
}
}
}
用于测试的数据
为 /employees 索引添加测试数据:
DELETE /employees
PUT /employees/
{
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"gender" : {
"type" : "keyword"
},
"job" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 50
}
}
},
"name" : {
"type" : "keyword"
},
"salary" : {
"type" : "integer"
}
}
}
}
PUT /employees/_bulk
{"index":{"_id":"1"}}
{"name":"Emma","age":32,"job":"Product Manager","gender":"female","salary":35000}
{"index":{"_id":"2"}}
{"name":"Underwood","age":41,"job":"Dev Manager","gender":"male","salary":50000}
{"index":{"_id":"3"}}
{"name":"Tran","age":25,"job":"Web Designer","gender":"male","salary":18000}
{"index":{"_id":"4"}}
{"name":"Rivera","age":26,"job":"Web Designer","gender":"female","salary":22000}
{"index":{"_id":"5"}}
{"name":"Rose","age":25,"job":"QA","gender":"female","salary":18000}
{"index":{"_id":"6"}}
{"name":"Lucy","age":31,"job":"QA","gender":"female","salary":25000}
{"index":{"_id":"7"}}
{"name":"Byrd","age":27,"job":"QA","gender":"male","salary":20000}
{"index":{"_id":"8"}}
{"name":"Foster","age":27,"job":"Java Programmer","gender":"male","salary":20000}
{"index":{"_id":"9"}}
{"name":"Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000}
{"index":{"_id":"10"}}
{"name":"Bryant","age":20,"job":"Java Programmer","gender":"male","salary":9000}
{"index":{"_id":"11"}}
{"name":"Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000}
{"index":{"_id":"12"}}
{"name":"Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary":32000}
{"index":{"_id":"13"}}
{"name":"Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000}
{"index":{"_id":"14"}}
{"name":"Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary":25000}
{"index":{"_id":"15"}}
{"name":"King","age":33,"job":"Java Programmer","gender":"male","salary":28000}
{"index":{"_id":"16"}}
{"name":"Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary":16000}
{"index":{"_id":"17"}}
{"name":"Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary":16000}
{"index":{"_id":"18"}}
{"name":"Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary":20000}
{"index":{"_id":"19"}}
{"name":"Boone","age":30,"job":"DBA","gender":"male","salary":30000}
{"index":{"_id":"20"}}
{"name":"Kathy","age":29,"job":"DBA","gender":"female","salary":20000}
限定数据范围
ES 聚合分析的默认作用范围是 query 的查询结果集。
同时 ES 还支持以下方式改变聚合的作用范围:
filter- 只对当前子聚合语句生效post_filter- 对聚合分析后的文档进行再次过滤global- 无视 query,对全部文档进行统计
【示例】使用 query 限定聚合数据的范围
POST /employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 20
}
}
},
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
}
}
}
}
【示例】使用 filter 限定聚合数据的范围
POST /employees/_search
{
"size": 0,
"aggs": {
"older_person": {
"filter":{
"range":{
"age":{
"from":35
}
}
},
"aggs":{
"jobs":{
"terms": {
"field":"job.keyword"
}
}},
"all_jobs": {
"terms": {
"field":"job.keyword"
}
}
}
}
控制返回聚合结果
【示例】仅返回聚合结果
使用 field 限定聚合返回的展示字段:
POST /employees/_search
{
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
}
}
}
// 找出所有的 job 类型,还能找到聚合后符合条件的结果
POST /employees/_search
{
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
}
},
"post_filter": {
"match": {
"job.keyword": "Dev Manager"
}
}
}
默认情况下,包含聚合的搜索会同时返回搜索命中和聚合结果。要仅返回聚合结果,请将 size 设置为 0:
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword"
}
}
}
}
聚合结果排序
【示例】聚合结果排序
指定 order,按照 _count 和 _key 进行排序。
POST /employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 20
}
}
},
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"order": [
{
"_count": "asc"
},
{
"_key": "desc"
}
]
}
}
}
}
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"order": [
{
"avg_salary": "desc"
}
]
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
}
}
}
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"order": [
{
"stats_salary.min": "desc"
}
]
},
"aggs": {
"stats_salary": {
"stats": {
"field": "salary"
}
}
}
}
}
}
运行多个聚合
【示例】运行多个聚合
可以在同一请求中指定多个聚合:
POST /employees/_search
{
"size": 0,
"query": {
"range": {
"age": {
"gte": 40
}
}
},
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
}
},
"all":{
"global":{},
"aggs":{
"salary_avg":{
"avg":{
"field":"salary"
}
}
}
}
}
}
运行子聚合
【示例】运行子聚合
Bucket 聚合支持 Bucket 或 Metric 子聚合。例如,具有 avg 子聚合的 terms 聚合会计算每个桶中文档的平均值。嵌套子聚合没有级别或深度限制。
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"min_salary_by_job":{
"min_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
响应将子聚合结果嵌套在其父聚合下:
{
// ...
"aggregations": {
"jobs": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 6,
"buckets": [
{
"key": "Java Programmer",
"doc_count": 7,
"avg_salary": {
"value": 25571.428571428572
}
},
{
"key": "Javascript Programmer",
"doc_count": 4,
"avg_salary": {
"value": 19250.0
}
},
{
"key": "QA",
"doc_count": 3,
"avg_salary": {
"value": 21000.0
}
}
]
},
"min_salary_by_job": {
"value": 19250.0,
"keys": ["Javascript Programmer"]
}
}
}
Metric(指标聚合)
指标聚合主要从不同文档的分组中提取统计数据,或者,从来自其他聚合的文档桶来提取统计数据。
这些统计数据通常来自数值型字段,如最小或者平均价格。用户可以单独获取每项统计数据,或者也可以使用 stats 聚合来同时获取它们。更高级的统计数据,如平方和或者是标准差,可以通过 extended stats 聚合来获取。
ES 支持的指标聚合类型:
| 类型 | 说明 |
|---|---|
| avg | 平均值聚合 |
| boxplot | 箱线图聚合 |
| cardinality | 近似计算非重复值 |
| extended_stats | 扩展统计聚合 |
| geo_bounds | 地理边界聚合 |
| geo_centroid | 根据* geo *字段的所有坐标值计算加权质心 |
| geo_line_geo_line | 根据地理数据生成可用于线性几何图形展示的数据 |
| cartesian_bounds | 笛卡尔积边界聚合 |
| cartesian_centroid | 计算所有坐标值加权质心 |
| matrix_stats | 矩阵统计聚合 |
| max | 最大值聚合 |
| median_absolute_deviation | 中位数绝对偏差聚合 |
| min | 最小值聚合 |
| percentile_ranks | 百分位排名聚合 |
| percentiles | 百分位聚合 |
| rate | 频率聚合 |
| scripted_metric | 脚本化指标聚合 |
| stats | 统计聚合 |
| string_stats | 字符串统计聚合 |
| sum | 求和聚合 |
| t_test | 校验聚合 |
| top_hits | 热门点击统计 |
| top_metrics | 热门指标聚合 |
| value_count | 值统计聚合 |
| weighted_avg | 加权平均值聚合 |
【示例】指标聚合示例
Metric 聚合测试:
// Metric 聚合,找到最低的工资
POST /employees/_search
{
"size": 0,
"aggs": {
"min_salary": {
"min": {
"field":"salary"
}
}
}
}
// Metric 聚合,找到最高的工资
POST /employees/_search
{
"size": 0,
"aggs": {
"max_salary": {
"max": {
"field":"salary"
}
}
}
}
// 多个 Metric 聚合,找到最低最高和平均工资
POST /employees/_search
{
"size": 0,
"aggs": {
"max_salary": {
"max": {
"field": "salary"
}
},
"min_salary": {
"min": {
"field": "salary"
}
},
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
}
// 一个聚合,输出多值
POST /employees/_search
{
"size": 0,
"aggs": {
"stats_salary": {
"stats": {
"field": "salary"
}
}
}
}
Bucket(桶聚合)
桶聚合不会像指标聚合那样计算字段的指标,而是创建文档桶。每个桶都与一个标准(取决于聚合类型)相关联,该标准确定当前上下文中的文档是否“落入”其中。换句话说,桶有效地定义了文档集。除了桶本身之外,桶聚合还计算并返回“落入”每个桶的文档数。
与指标聚合相反,桶聚合可以保存子聚合。这些子聚合将针对其 “父” 桶聚合创建的桶进行聚合。
Elasticsearch 中支持的桶聚合类型:
| 类型 | 说明 |
|---|---|
| adjacency_matrix | 邻接矩阵聚合 |
| auto_interval_date_histogram | 自动间隔日期直方图聚合 |
| categorize_text | 对文本进行分类聚合 |
| children | 子文档聚合 |
| composite | 组合聚合 |
| date_histogram | 日期直方图聚合 |
| date_range | 日期范围聚合 |
| diversified_sampler | 多种采样器聚合 |
| filter | 过滤器聚合 |
| filters | 多过滤器聚合 |
| geo_distance | 地理距离聚合 |
| geohash_grid | geohash 网格 |
| geohex_grid | geohex 网格 |
| geotile_grid | geotile 网格 |
| global | 全局聚合 |
| histogram | 直方图聚合 |
| ip_prefix | IP 前缀聚合 |
| ip_range | IP 范围聚合 |
| missing | 空值聚合 |
| multi_terms | 多词项分组聚合 |
| nested | 嵌套聚合 |
| parent | 父文档聚合 |
| random_sampler | 随机采样器聚合 |
| range | 范围聚合 |
| rare_terms | 稀有多词项聚合 |
| reverse_nested | 反向嵌套聚合 |
| sampler | 采样器聚合 |
| significant_terms | 重要词项聚合 |
| significant_text | 重要文本聚合 |
| terms | 词项分组聚合 |
| time_series | 时间序列聚合 |
| variable_width_histogram | 可变宽度直方图聚合 |
【示例】terms 聚合查询
默认,ES 不允许对 Text 字段进行 terms 聚合查询
// 对 keword 进行聚合
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
}
}
}
}
// 对 Text 字段进行 terms 聚合查询,失败
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job"
}
}
}
}
// 对 Text 字段打开 fielddata,支持 terms aggregation
PUT employees/_mapping
{
"properties" : {
"job":{
"type": "text",
"fielddata": true
}
}
}
// 对 Text 字段进行 terms 分词。分词后的 terms
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job"
}
}
}
}
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
}
}
}
}
【示例】更多 Bucket 聚合示例
// 对 job 进行近似去重统计
POST /employees/_search
{
"size": 0,
"aggs": {
"cardinate": {
"cardinality": {
"field": "job"
}
}
}
}
// 对 gender 进行聚合
POST /employees/_search
{
"size": 0,
"aggs": {
"gender": {
"terms": {
"field":"gender"
}
}
}
}
// 指定 bucket 的 size
POST /employees/_search
{
"size": 0,
"aggs": {
"ages_5": {
"terms": {
"field":"age",
"size":3
}
}
}
}
// 指定 size,不同工种中,年纪最大的 3 个员工的具体信息
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field":"job.keyword"
},
"aggs":{
"old_employee":{
"top_hits":{
"size":3,
"sort":[
{
"age":{
"order":"desc"
}
}
]
}
}
}
}
}
}
// Salary Ranges 分桶,可以自己定义 key
POST /employees/_search
{
"size": 0,
"aggs": {
"salary_range": {
"range": {
"field":"salary",
"ranges":[
{
"to":10000
},
{
"from":10000,
"to":20000
},
{
"key":">20000",
"from":20000
}
]
}
}
}
}
// Salary Histogram, 工资 0 到 10 万,以 5000 一个区间进行分桶
POST /employees/_search
{
"size": 0,
"aggs": {
"salary_histrogram": {
"histogram": {
"field":"salary",
"interval":5000,
"extended_bounds":{
"min":0,
"max":100000
}
}
}
}
}
// 嵌套聚合 1,按照工作类型分桶,并统计工资信息
POST /employees/_search
{
"size": 0,
"aggs": {
"Job_salary_stats": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"salary": {
"stats": {
"field": "salary"
}
}
}
}
}
}
// 多次嵌套。根据工作类型分桶,然后按照性别分桶,计算工资的统计信息
POST /employees/_search
{
"size": 0,
"aggs": {
"Job_gender_stats": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"gender_stats": {
"terms": {
"field": "gender"
},
"aggs": {
"salary_stats": {
"stats": {
"field": "salary"
}
}
}
}
}
}
}
}
Pipeline(管道聚合)
管道聚合处理从其他聚合而不是文档集生成的输出,从而将信息添加到输出树中。
Pipeline 聚合的分析结果会输出到原结果中,根据位置的不同,分为两类:
- sibling - 结果和现有分析结果同级。例如:max_bucket、min_bucket、avg_bucket、sum_bucket、stats_bucket、extended_stats_bucket、percentiles_bucket。
- parent - 结果内嵌到现有的聚合分析结果中。例如:derivative、cumulative_sum、moving_function。
管道聚合可以通过使用 buckets_path 参数来指示所需指标的路径,从而引用执行计算所需的聚合。管道聚合不能具有子聚合,但根据类型,它可以引用buckets_path中的另一个管道,从而允许链接管道聚合。
以下为 Elasticsearch 支持的管道聚合类型:
| 类型 | 说明 |
|---|---|
| avg_bucket | 平均桶 |
| bucket_script | 桶脚本 |
| bucket_count_ks_test | 桶数 k-s 测试 |
| bucket_correlation | 桶关联 |
| bucket_selector | 桶选择器 |
| bucket_sort | 桶排序 |
| change_point | 更改点 |
| cumulative_cardinality | 累积基数 |
| cumulative_sum | 累计总和 |
| derivative | 导数 |
| extended_stats_bucket | 扩展的统计信息桶 |
| inference_bucket | 推理桶 |
| max_bucket | 最大桶 |
| min_bucket | 最小桶 |
| moving_function | 移动功能 |
| moving_percentiles | 移动百分位数 |
| normalize | 正常化 |
| percentiles_bucket | 百分位数桶 |
| serial_differencing | 序列差分 |
| stats_bucket | 统计桶 |
| sum_bucket | 总和桶 |
【示例】Pipeline 聚合示例
// 平均工资最低的工作类型
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"min_salary_by_job":{
"min_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
// 平均工资最高的工作类型
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"max_salary_by_job":{
"max_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
// 平均工资的平均工资
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"avg_salary_by_job":{
"avg_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
// 平均工资的统计分析
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"stats_salary_by_job":{
"stats_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
// 平均工资的百分位数
POST /employees/_search
{
"size": 0,
"aggs": {
"jobs": {
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
},
"percentiles_salary_by_job":{
"percentiles_bucket": {
"buckets_path": "jobs>avg_salary"
}
}
}
}
// 按照年龄对平均工资求导
POST /employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"derivative_avg_salary":{
"derivative": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
// Cumulative_sum
POST /employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"cumulative_salary":{
"cumulative_sum": {
"buckets_path": "avg_salary"
}
}
}
}
}
}
// Moving Function
POST /employees/_search
{
"size": 0,
"aggs": {
"age": {
"histogram": {
"field": "age",
"min_doc_count": 1,
"interval": 1
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
},
"moving_avg_salary":{
"moving_fn": {
"buckets_path": "avg_salary",
"window":10,
"script": "MovingFunctions.min(values)"
}
}
}
}
}
}
聚合的执行流程
在 ES 中,不仅仅是普通搜索,相关性计算(评分)和聚合计算也是先在每个 shard 的本地进行计算,再由 coordinate node 进行汇总。由于分片的本地计算是独立的,只能基于数据子集来进行计算,所以难免出现数据偏差。
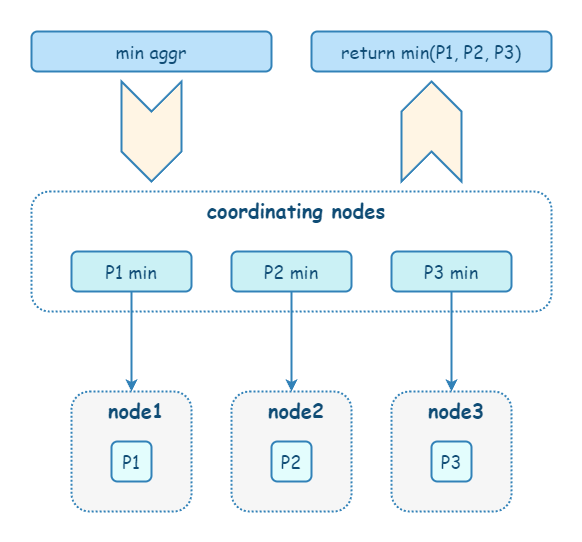
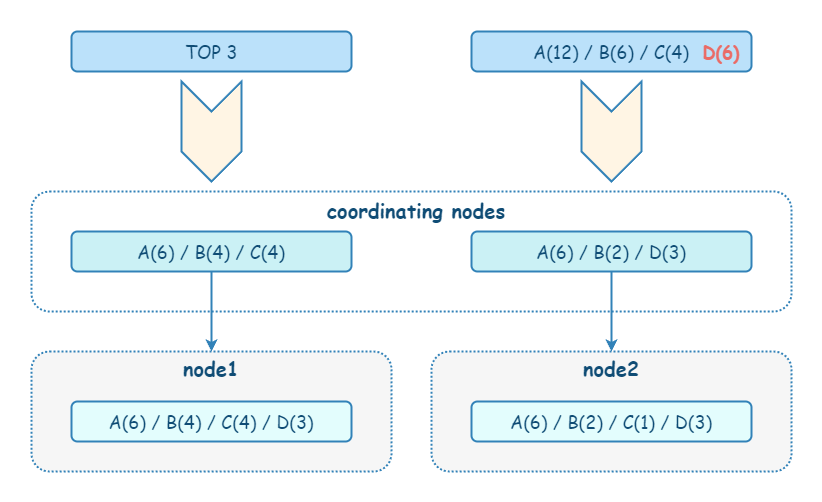
要解决聚合准确性问题,有两个解决方案:
- 解决方案 1:当数据量不大的情况下,设置主分片数为 1,这意味着在数据全集上进行聚合。但这种方案不太现实。
- 解决方案 2:设置
shard_size参数,将计算数据范围变大,牺牲整体性能,提高精准度。shard_size 的默认值是size * 1.5 + 10。
FAQ
如何对海量数据(过亿)进行聚合计算?
Elasticsearch 支持 cardinality(近似计算非重复值) 。它提供一个字段的基数,即该字段的 distinct 或者 unique 值的数目。它是基于 HLL 算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。