Java 容器面试一
Java 容器面试一
Java 容器简介
【简单】Java 中有哪些集合类?
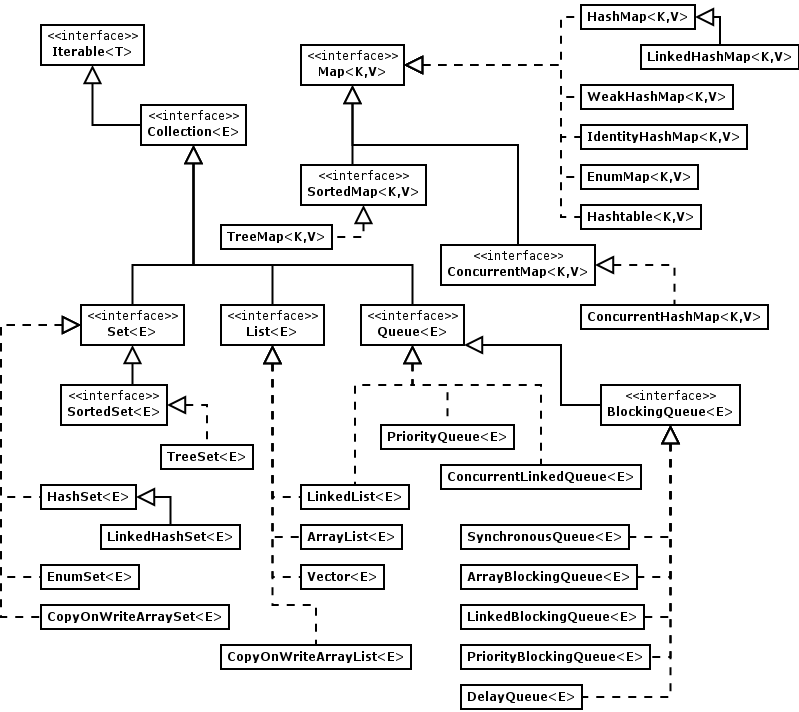
Java 容器类主要位于 java.util 包,分为 Collection 和 Map 两大类:
- Collection(存储独立元素)
- List(有序、可重复)
- ArrayList:基于
Object[]动态数组,查询快,增删慢 - LinkedList:基于双链表(JDK1.6 前是循环链表,1.7 取消循环),增删快,查询慢
- Vector:线程安全的
Object[]动态数组(已过时,推荐ArrayList+Collections.synchronizedList)
- ArrayList:基于
- Set(无序、不可重复)
- HashSet:基于
HashMap实现,不保证顺序 - LinkedHashSet:基于
LinkedHashMap,维护插入顺序 - TreeSet:基于
TreeMap,支持自然排序或自定义Comparator
- HashSet:基于
- Queue(队列,FIFO 或优先级)
- ArrayDeque:基于动态数组,实现栈和队列
- PriorityQueue:基于堆,优先级队列(按
Comparator排序) - LinkedList:也可作为队列/双端队列
- List(有序、可重复)
- Map(键值对存储)
- HashMap:基于哈希表,无序,查找高效(最常用)
- LinkedHashMap:继承
HashMap,额外维护双向链表,保持插入顺序或访问顺序 - TreeMap:基于红黑树,键有序(自然排序或
Comparator) - Hashtable:线程安全(
synchronized修饰方法),但性能差,已被ConcurrentHashMap取代 - ConcurrentHashMap:分段锁(JDK7)或 CAS +
synchronized(JDK8+),高并发优化
- 工具类
- Collections:提供集合操作(排序、查找、同步化等)
- Arrays:提供数组操作(排序、二分查找等)
- Stream(Java 8+):支持函数式编程的流式处理
关键区别:
| 类型 | 特点 | 主要实现类 |
|---|---|---|
| List | 有序、可重复 | ArrayList、LinkedList |
| Set | 无序、不可重复 | HashSet、LinkedHashSet、TreeSet |
| Queue | 队列/栈 | ArrayDeque、PriorityQueue |
| Map | 键值对 | HashMap、LinkedHashMap、TreeMap |
线程安全:
- 单线程:
ArrayList、HashMap - 多线程:
ConcurrentHashMap、CopyOnWriteArrayList
【简单】Comparable 和 Comparator 有什么区别?
Comparable 接口和 Comparator 接口都是 Java 中用于排序的接口,它们在实现类对象之间比较大小、排序等方面发挥了重要作用。
- Comparable → "我能比较"(类自己实现的比较能力)
- Comparator → "比较器"(外部提供的比较工具)
两者通常一起使用,为Java对象提供灵活多样的排序能力。
Comparable vs. Comparator:
| 特性 | Comparable | Comparator |
|---|---|---|
| 包位置 | java.lang | java.util |
| 接口方法 | compareTo(T o) | compare(T o1, T o2) |
| 排序逻辑位置 | 定义在要排序的类内部 | 定义在单独的类或匿名类中 |
| 使用场景 | 类的"自然排序" | 多种排序方式或无法修改类时的排序 |
| 调用方式 | Collections.sort(list) | Collections.sort(list, comparator) |
| 影响范围 | 修改类的原始定义 | 不修改原有类 |
设计目的不同
Comparable:定义对象的自然排序(如String按字母顺序,Integer按数值大小)Comparator:定义多种排序策略或为无法修改源代码的类提供排序
实现方式不同
Comparable:需要修改类本身,实现compareTo()方法
class Person implements Comparable<Person> {
public int compareTo(Person other) {
return this.age - other.age;
}
}
Comparator:独立实现,通常使用匿名类或lambda表达式
Comparator<Person> byName = (p1, p2) -> p1.getName().compareTo(p2.getName());
使用场景选择
- 用
Comparable当:- 类有明确的自然排序标准
- 你能修改类的源代码
- 只需要一种主要排序方式
- 用
Comparator当:- 需要多种排序方式(如按姓名、年龄、工资等)
- 不能修改类的源代码(如第三方库的类)
- 需要临时或特殊的排序规则
Java 8+的便利支持
- Comparator提供了许多方便的静态方法:
// 多级排序
Comparator<Person> comparator =
Comparator.comparing(Person::getLastName)
.thenComparing(Person::getFirstName);
// 逆序排序
Comparator<Person> reverseAge =
Comparator.comparingInt(Person::getAge).reversed();
List
【简单】ArrayList 和 Array(数组)的区别?
ArrayList vs. 数组
| 对比点 | 数组 (Array) | ArrayList |
|---|---|---|
| 长度可变性 | 固定长度,创建后无法调整大小 | 动态扩容(默认扩容1.5倍) |
| 存储类型 | 支持基本类型(int[])和对象类型 | 仅支持引用类型(基本类型需装箱,如 Integer) |
| 内存占用 | 更紧凑(无额外对象开销) | 有额外内存开销(记录大小、扩容预留空间等) |
| 访问方式 | 通过索引直接访问(arr[0]) | 通过 get(index)/set(index) 方法访问 |
| 操作效率 | - 查询:O(1)(极快) - 增删:O(n)(需移动元素) | - 查询:O(1)(底层是数组) - 增删: - 尾部操作:O(1) - 中间操作:O(n)(需移动元素) |
| 功能方法 | 功能简单(依赖 Arrays 工具类) | 提供丰富方法(add()、remove()、contains() 等) |
| 线程安全 | 非线程安全 | 非线程安全(需用 Collections.synchronizedList 包装) |
| 泛型支持 | 不支持泛型(类型检查在运行时) | 支持泛型(编译时类型安全) |
小结:
- 动态性:
ArrayList自动扩容,数组长度固定。 - 类型支持:数组可直接存基本类型,
ArrayList需包装类。 - 性能:
- 数组的随机访问稍快(少一次方法调用)。
ArrayList的尾部插入高效,但中间插入/删除需移动元素。
- 功能:
ArrayList提供更多便捷方法(如迭代、搜索)。 - 内存:数组更节省内存,
ArrayList有额外结构开销。
应用:
- 选数组:需极致性能、固定长度或存储基本类型时(如数学计算)。
- 选ArrayList:需要动态大小、便捷操作或泛型安全时(大多数业务场景)。
【简单】ArrayList 可以添加 null 值吗?
ArrayList 可以添加任意数量的 null 值,包括重复 null,但需谨慎处理潜在的空指针问题。
ArrayList底层基于 Object[] 数组实现,天然支持 null。
注意:
- 可能引发
NullPointerException:- 直接调用
null的方法(如list.get(0).length())会报错。 - 使用
contains(null)或遍历时需判空。
- 直接调用
- 慎用于特定场景:如数据库映射、JSON 序列化工具可能对
null有特殊限制。
与其他容器对比:
- HashSet:允许一个
null。 - TreeSet:若用自然排序,添加
null会抛NullPointerException。 - HashMap:允许
null键和值。 - Hashtable:禁止
null键和值。
建议:
- 明确是否需要
null,避免滥用导致代码健壮性问题。 - 必要时用
Optional或默认值替代null。
【简单】ArrayList 和 LinkedList 有什么区别?
ArrayList vs. LinkedList
| 对比维度 | ArrayList | LinkedList |
|---|---|---|
| 底层数据结构 | 动态数组(Object[]) | 双向链表(Node 节点) |
| 内存占用 | 更紧凑(连续内存) | 更高(每个元素需额外存储前后节点指针) |
| 随机访问性能 | ⚡ O(1)(通过索引直接访问) | 🐢 O(n)(需遍历链表) |
| 插入/删除性能 | - 尾部操作:⚡ O(1) - 中间/头部操作:🐢 O(n)(需移动元素) | - 头尾操作:⚡ O(1) - 中间操作:🐢 O(n)(需遍历定位) |
| 适用场景 | - 频繁随机访问 - 数据量稳定或尾部操作多 | - 频繁头尾插入/删除 - 数据动态性强 |
| 额外功能 | 仅基础列表操作 | 实现了 Deque 接口(可作队列/栈使用) |
| 空间局部性 | ✅ 更好(CPU 缓存友好) | ❌ 较差(节点分散存储) |
对比小结:
List 需遍历链表。 2. **增删效率**:ArrayList 尾部插入快,中间/头部插入慢;Lin
- 访问速度:
ArrayList随机访问极快(数组索引),LinkedkedList头尾插入快,中间插入仍需遍历。 - 内存开销:
LinkedList每个元素多消耗 2 个指针空间(前驱+后继)。 - 功能扩展:
LinkedList支持队列/栈操作(如addFirst(),pollLast())。
选型建议:
- 优先用
ArrayList(大多数场景性能更优)。 - 仅当需要频繁在 头部/中间插入删除,或需要 队列/栈功能 时选
LinkedList。
💡 Java 实践提示:
- 默认情况下,
Collections.synchronizedList包装的ArrayList比LinkedList线程安全开销更低。- Java 8+ 的
Stream操作在ArrayList上效率更高。
Set
【简单】HashSet、LinkedHashSet 和 TreeSet 有什么区别?
| 特性 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底层实现 | 哈希表 (HashMap) | 哈希表 + 链表 | 红黑树 |
| 排序保证 | 无顺序 | 插入顺序 | 自然顺序/自定义排序 |
| 时间复杂度 | 添加/删除/查找: O(1) | 添加/删除/查找: O(1) | 添加/删除/查找: O(log n) |
| 允许null元素 | 允许1个null | 允许1个null | 不允许(除非自定义Comparator允许) |
| 线程安全 | 非线程安全 | 非线程安全 | 非线程安全 |
| 性能特点 | 最快的基础操作 | 比HashSet稍慢但保持顺序 | 最慢但自动排序 |
| 使用场景 | 只需唯一性不关心顺序 | 需要保持插入顺序 | 需要排序的集合 |
顺序特性
HashSet:完全不保证任何顺序(基于哈希值存储)LinkedHashSet:维护元素插入顺序(迭代时按插入顺序返回)TreeSet:根据元素的自然顺序或Comparator进行排序
性能比较
- 操作速度:HashSet ≈ LinkedHashSet > TreeSet
- 内存占用:LinkedHashSet > HashSet > TreeSet
- 迭代性能:LinkedHashSet最优(顺序访问快)
实现原理
HashSet:基于HashMap实现,只使用键LinkedHashSet:继承HashSet,通过链表维护插入顺序TreeSet:基于TreeMap实现(红黑树结构)
构造方式
// HashSet
Set<String> hashSet = new HashSet<>();
// LinkedHashSet
Set<String> linkedHashSet = new LinkedHashSet<>();
// TreeSet - 自然排序
Set<String> treeSet = new TreeSet<>();
// TreeSet - 自定义排序
Set<String> customTreeSet = new TreeSet<>(Comparator.reverseOrder());
使用场景建议
- 需要最快查询且不关心顺序 → HashSet
- 需要保持插入顺序 → LinkedHashSet
- 需要自动排序或范围查询 → TreeSet
- 需要频繁迭代 → LinkedHashSet
特殊注意事项
相等性判断:
- 三者都使用
equals()方法判断元素是否相同 - TreeSet同时会使用
compareTo()或compare()方法(必须与equals逻辑一致)
- 三者都使用
TreeSet排序规则:
- 元素必须实现
Comparable接口,或在构造时提供Comparator - 否则会抛出
ClassCastException
- 元素必须实现
线程安全替代方案:
Set<String> syncSet = Collections.synchronizedSet(new HashSet<>()); Set<String> syncTreeSet = Collections.synchronizedSet(new TreeSet<>());
选择哪种Set实现取决于你的具体需求:要速度(HashSet)、要插入顺序(LinkedHashSet)还是要自动排序(TreeSet)。
Queue
【简单】Queue 与 Deque 有什么区别?
Queue vs. Deque
| 特性 | Queue (队列) | Deque (双端队列) |
|---|---|---|
| 进出原则 | 先进先出 (FIFO) | 两端都可进出 (FIFO + LIFO) |
| 主要操作 | 队尾入队(add/offer),队首出队(remove/poll) | 支持队首/队尾的入队和出队操作 |
| 继承关系 | 基础接口 | 继承自 Queue 接口 |
| 代表子类 | LinkedList, PriorityQueue | ArrayDeque, LinkedList |
| 特殊功能 | - | 支持栈操作(push/pop/peek) |
基本操作对比
queue.offer(e); // 队尾添加(推荐)
queue.add(e); // 队尾添加(可能抛异常)
queue.poll(); // 队首移除并返回(推荐)
queue.remove(); // 队首移除并返回(可能抛异常)
queue.peek(); // 查看队首(不移除)
queue.element(); // 查看队首(可能抛异常)
// 队首操作
deque.offerFirst(e); deque.addFirst(e);
deque.pollFirst(); deque.removeFirst();
deque.peekFirst(); deque.getFirst();
// 队尾操作
deque.offerLast(e); deque.addLast(e);
deque.pollLast(); deque.removeLast();
deque.peekLast(); deque.getLast();
// 栈操作
deque.push(e); // = addFirst(e)
deque.pop(); // = removeFirst()
使用场景差异
- Queue 适用场景(标准的先进先出场景):
- 任务调度系统(先来先服务)
- 消息队列(生产者-消费者模型)
- 广度优先搜索(BFS)
- Deque 适用场景(需要两端操作的场景):
- 撤销操作历史(两端添加,一端移除)
- 滑动窗口算法
- 可同时作为队列和栈使用
- 工作窃取算法(如ForkJoinPool使用Deque)
- 实现高效的头尾操作(ArrayDeque比LinkedList更高效)
小结:
- 需要标准队列行为 → 选择 Queue
- 需要两端操作或栈功能 → 选择 Deque
- 需要优先级排序 → 使用 PriorityQueue(Queue实现)
- 追求高性能 → 优先考虑 ArrayDeque(优于 LinkedList)
性能特点
ArrayDeque(Deque实现)比LinkedList:- 内存更紧凑(数组实现)
- 大多数操作更高效(O(1)时间)
- 但不适合频繁的中间插入/删除
PriorityQueue(Queue实现):- 基于堆结构
- 保证每次取出的都是优先级最高的元素(O(log n)时间)
线程安全注意
- 两者主要实现类(LinkedList/ArrayDeque)都非线程安全
- 线程安全替代方案:
Queue<String> safeQueue = new ConcurrentLinkedQueue<>(); Deque<String> safeDeque = new ConcurrentLinkedDeque<>();
【简单】ArrayDeque 与 LinkedList 有什么区别?
- 性能优先选
ArrayDeque:队列/栈场景,追求更高吞吐和更低内存。 - 功能灵活选
LinkedList:需要中间操作、随机访问或混合数据结构时。
以下是 ArrayDeque 和 LinkedList 的对比表格,清晰概括两者的核心差异:
| 对比项 | ArrayDeque | LinkedList |
|---|---|---|
| 底层数据结构 | 动态数组(循环数组) | 双向链表 |
| 内存占用 | 更低(连续存储,无节点开销) | 更高(每个元素需存储前后节点引用) |
| 头部/尾部操作 | O(1),常数时间更优 | O(1),但实际更慢(需操作节点) |
| 中间插入/删除 | O(n)(需移动元素) | O(1)(已知位置时) |
| 随机访问 | 理论上 O(1),但通常不支持直接索引操作 | O(n)(需遍历链表) |
| 扩容机制 | 动态扩容(默认翻倍),扩容时有开销 | 无扩容概念,按需分配节点 |
| 功能支持 | 仅双端队列操作(Deque) | 同时实现 List 和 Deque,支持索引和中间操作 |
| 线程安全 | 非线程安全 | 非线程安全 |
| 迭代效率 | 更高(连续内存访问) | 较低(非连续内存访问) |
| 适用场景 | 高频双端操作(如栈、队列) | 需要中间操作或混合 List/Deque 需求的场景 |
【简单】PriorityQueue 有什么用?
PriorityQueue 是自动排序的堆结构队列,默认小顶堆,适用优先级调度,但线程不安全。
基本特性
- 基于堆(默认小顶堆),元素按优先级出队(最小/最大值先出)。
- 无界队列(自动扩容),但初始容量为
11。 - 不允许
null,且元素需实现Comparable或提供Comparator。
关键操作
| 方法 | 时间复杂度 | 说明 |
|---|---|---|
add(E e) / offer(E e) | O(log n) | 插入元素,触发堆调整。 |
poll() | O(log n) | 移除并返回队首(优先级最高)。 |
peek() | O(1) | 查看队首但不移除。 |
remove(Object o) | O(n) | 删除指定元素(需遍历堆)。 |
排序规则
- 默认自然排序(元素需实现
Comparable)。 - 自定义排序:通过
Comparator指定(如大顶堆)。PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);
使用场景
- 任务调度(按优先级执行)。
- Top K 问题(维护前 K 个最大/最小值)。
- Dijkstra 算法(优先处理最短路径)。
注意事项
- 非线程安全:多线程需用
PriorityBlockingQueue。 - 迭代无序:遍历顺序不等于优先级顺序。
- 性能权衡:插入/删除 O(log n),但查找 O(n)。
【简单】BlockingQueue 有什么用?
BlockingQueue 是线程安全的队列,支持阻塞操作(队列满时阻塞插入,空时阻塞取出)。主要用于生产者-消费者模型,协调多线程数据交换。
关键方法:
| 方法 | 说明 |
|---|---|
put(E e) | 队列满时阻塞,直到有空间插入。 |
take() | 队列空时阻塞,直到有元素可取。 |
offer(E e) | 非阻塞插入,成功返回 true,失败返回 false。 |
poll() | 非阻塞取出,有元素返回元素,无元素返回 null。 |
peek() | 查看队首元素但不移除(无元素返回 null)。 |
常见实现类
ArrayBlockingQueue:固定大小数组,单锁,适合低并发。LinkedBlockingQueue:链表,双锁(高并发),默认几乎无界。PriorityBlockingQueue:优先级队列(堆实现),无界。SynchronousQueue:不存储元素,直接传递任务(一对一通信)。
适用场景
- 任务调度(线程池任务队列)。
- 数据缓冲(生产者-消费者模型)。
- 流量控制(通过固定容量限制并发)。
注意事项
- 线程安全:所有实现均线程安全,但需注意
peek()和poll()的竞态条件。 - 阻塞策略:
put()/take()会阻塞,offer()/poll()可设置超时。 - 无界队列风险:
LinkedBlockingQueue默认无界,可能导致OOM,建议设置容量。
一句话总结: 多线程间安全传递数据的阻塞队列,核心方法是 put()(阻塞插入)和 take()(阻塞取出),按场景选实现类。
【中等】ArrayBlockingQueue 和 LinkedBlockingQueue 有什么区别?
ArrayBlockingQueue 和 LinkedBlockingQueue 都是 Java 并发包(java.util.concurrent)中的线程安全阻塞队列,但它们在底层实现、性能和适用场景上有显著区别。
ArrayBlockingQueue:固定容量,单锁,适合低并发或内存敏感场景。LinkedBlockingQueue:动态扩容,双锁,适合高并发和高吞吐场景。- 避免
OOM:如果使用LinkedBlockingQueue,建议设置合理容量(默认MAX_VALUE可能导致内存问题)。
ArrayBlockingQueue vs. LinkedBlockingQueue
| 对比项 | ArrayBlockingQueue | LinkedBlockingQueue |
|---|---|---|
| 底层数据结构 | 固定大小的数组(循环队列) | 链表(可动态扩容) |
| 初始化容量 | 必须指定容量(无默认构造方法) | 可选指定容量(默认 Integer.MAX_VALUE) |
| 内存占用 | 更紧凑(连续存储) | 稍高(每个节点存储前后指针) |
| 锁机制 | 单锁(入队和出队共用同一把锁) | 双锁(入队和出队分离锁,减少竞争) |
| 吞吐量 | 较低(锁竞争更激烈) | 较高(读写分离,并发性能更好) |
| 适用场景 | 固定大小队列,避免 OOM | 高并发、动态扩容场景 |
底层数据结构
ArrayBlockingQueue- 基于数组(循环队列),初始化时必须指定固定容量。
- 存储连续,内存局部性好,但扩容需重建数组(不支持动态扩容)。
LinkedBlockingQueue- 基于链表,默认容量
Integer.MAX_VALUE(几乎无界)。 - 可动态增长,但每个节点需额外存储前后指针,内存开销稍大。
- 基于链表,默认容量
锁机制
ArrayBlockingQueue- 使用单锁(
ReentrantLock),入队和出队操作共用同一把锁,竞争较激烈。 - 适合低并发或容量固定的场景。
- 使用单锁(
LinkedBlockingQueue- 采用双锁(
putLock和takeLock),入队和出队操作互不阻塞。 - 高并发下吞吐量更高(如生产者-消费者模型)。
- 采用双锁(
性能对比
| 操作 | ArrayBlockingQueue | LinkedBlockingQueue |
|---|---|---|
入队(put) | 较慢(单锁竞争) | 更快(双锁分离) |
出队(take) | 较慢(单锁竞争) | 更快(双锁分离) |
| 内存占用 | 更紧凑 | 稍高(链表节点开销) |
使用场景建议
选择 ArrayBlockingQueue 的情况:
- ✅ 队列大小固定,防止内存耗尽(如任务队列有严格上限)。
- ✅ 低/中并发,且对内存占用敏感。
选择 LinkedBlockingQueue 的情况:
- ✅ 高并发(生产者-消费者模型)。
- ✅ 队列大小不固定(默认几乎无界,但可手动指定容量)。
- ✅ 需要更高的吞吐量(双锁机制减少竞争)。