分布式存储面试
分布式存储面试
缓存
扩展
【简单】什么是缓存?为什么需要缓存?
缓存就是数据交换的缓冲区,用于将频繁访问的数据暂存在访问速度快的存储介质。
缓存的本质是一种利用空间换时间的设计:牺牲一定的数据实时性,使得访问更快、更近:
- 将数据存储到读取速度更快的存储(设备);
- 将数据存储到离应用最近的位置;
- 将数据存储到离用户最近的位置。
缓存是用于存储数据的硬件或软件的组成部分,以使得后续更快访问相应的数据。缓存中的数据可能是提前计算好的结果、数据的副本等。典型的应用场景:有 cpu cache, 磁盘 cache 等。本文中提及到缓存主要是指互联网应用中所使用的缓存组件。
缓存命中率是缓存的重要度量指标,命中率越高越好。
缓存命中率 = 从缓存中读取次数 / 总读取次数【简单】何时需要缓存?
引入缓存,会增加系统的复杂度,并牺牲一定的数据实时性。所以,引入缓存前,需要先权衡是否值得,考量点如下:
- CPU 开销 - 如果应用某个计算需要消耗大量 CPU,可以考虑缓存其计算结果。典型场景:复杂的、频繁调用的正则计算;分布式计算中间状态等。
- IO 开销 - 如果数据库连接池比较繁忙,可以考虑缓存其查询结果。
在数据层引入缓存,有以下几个好处:
- 提升数据读取速度。
- 提升系统扩展能力,通过扩展缓存,提升系统承载能力。
- 降低存储成本,Cache+DB 的方式可以承担原有需要多台 DB 才能承担的请求量,节省机器成本。

【中等】缓存有哪些分类?
缓存从部署角度,可以分为客户端缓存和服务端缓存。
客户端缓存
- Http 缓存:HTTP/1.1 中的
Cache-Control、HTTP/1 中的Expires - 浏览器缓存:HTML5 提供的 SessionStorage 和 LocalStorage、Cookie
- APP 缓存:Android、IOS
服务端缓存
- CDN 缓存 - CDN 将数据缓存到离用户物理距离最近的服务器,使得用户可以就近获取请求内容。CDN 一般缓存静态资源文件(页面,脚本,图片,视频,文件等)。
- 反向代理缓存 - 反向代理(Reverse Proxy)方式是指以代理服务器来接受网络连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个反向代理服务器。反向代理缓存一般针对的是静态资源,而将动态资源请求转发到应用服务器处理。
- 数据库缓存 - 数据库(如 Mysql)自身一般也有缓存,但因为命中率和更新频率问题,不推荐使用。
- 进程内缓存 - 缓存应用字典等常用数据。
- 分布式缓存 - 缓存数据库中的热点数据。
其中,CDN 缓存、反向代理缓存、数据库缓存一般由专职人员维护(运维、DBA)。
后端开发一般聚焦于进程内缓存、分布式缓存。
【中等】什么是 CDN?CDN 的工作原理是什么?
CDN 是一种将内容缓存到离用户更近的节点的分布式网络系统。CDN 一般缓存静态资源文件(页面,脚本,图片,视频,文件等)。
国内网络异常复杂,跨运营商的网络访问会很慢。为了解决跨运营商或各地用户访问问题,可以在重要的城市,部署 CDN 应用。使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
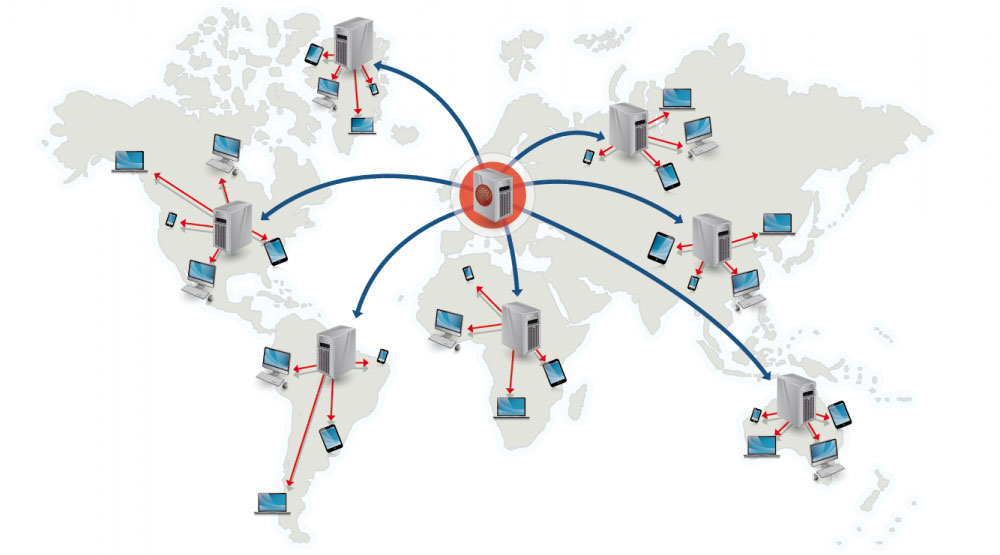
CDN 原理
- 就近调度:用户被导向最近的 CDN 节点
- 缓存+回源:节点有内容直接返回(缓存命中);节点无内容则向源站请求并缓存(缓存未命中)
CDN 特点
优点:
- 缓存加速:提升访问速度,尤其是含有大量图片和静态页面站点
- 带宽优化:自动生成服务器的远程 Mirror(镜像)cache 服务器,远程用户访问时从 cache 服务器上读取数据,减少远程访问的带宽、分担网络流量、减轻原站点 WEB 服务器负载等功能。
- 集群抗攻击 - 广泛分布的 CDN 节点加上节点之间的智能冗余机制,可以有效地预防黑客入侵以及降低各种 D.D.o.S 攻击对网站的影响,同时保证较好的服务质量。
缺点:
- 不适宜缓存动态资源
- 解决方案:主要缓存静态资源,动态资源建立多级缓存或准实时同步;
- 存在数据的一致性问题
- 解决方案(主要是在性能和数据一致性二者间寻找一个平衡)
- 设置缓存失效时间(1 个小时,过期后同步数据)。
- 针对资源设置版本号。
【中等】反向代理缓存的工作原理是什么?
反向代理服务器部署在应用服务器前端,作为流量入口。既是反向代理(转发请求),也是缓存服务器(缓存响应)。
反向代理(Reverse Proxy)方式是指以代理服务器来接受网络连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个反向代理服务器。
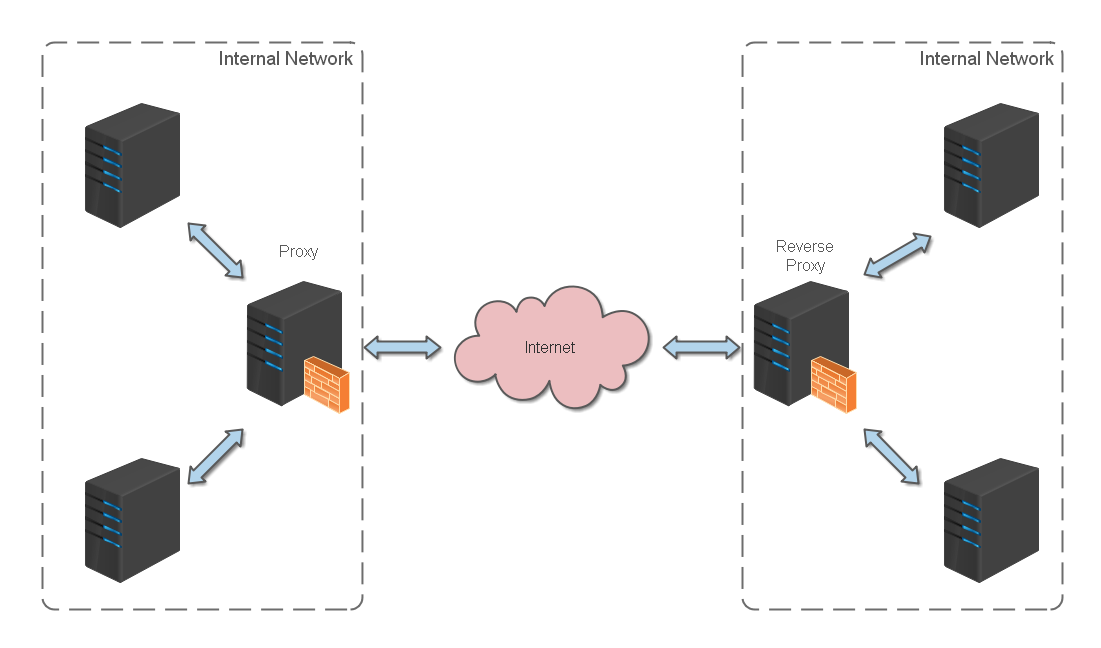
反向代理位于应用服务器同一网络,处理所有对 WEB 服务器的请求。
反向代理缓存的原理:
- 如果用户请求的页面在代理服务器上有缓存的话,代理服务器直接将缓存内容发送给用户。
- 如果没有缓存则先向 WEB 服务器发出请求,取回数据,本地缓存后再发送给用户。
这种方式通过降低向 WEB 服务器的请求数,从而降低了 WEB 服务器的负载。
反向代理缓存一般针对的是静态资源,而将动态资源请求转发到应用服务器处理。常用的缓存应用服务器有 Varnish,Ngnix,Squid。
【中等】缓存有哪些淘汰算法?⭐⭐⭐
扩展
缓存算法设计思路
缓存一般存于访问速度较快的存储介质,快也就意味着资源昂贵并且有限。正所谓,好钢要用在刀刃上。因此,缓存要合理利用,需要设定一些机制,将一些访问频率偏低或过期的数据淘汰。
淘汰缓存首先要做的是,确定什么时候触发淘汰缓存,一般有以下几个思路:
- 基于空间 - 设置缓存空间大小。
- 基于容量 - 设置缓存存储记录数。
- 基于时间
- TTL(Time To Live,即存活期) - 缓存数据从创建到过期的时间。
- TTI(Time To Idle,即空闲期) - 缓存数据多久没被访问的时间。
主流缓存算法对比
接下来,就要确定如何淘汰缓存,常见的缓存淘汰算法有以下几个:
| 算法 | 淘汰策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| FIFO(先进先出) | 淘汰最先进入的数据(队列结构) | 实现简单 | 缓存命中率低(无视访问频率,可能淘汰热点数据) | 数据访问无规律,或实现简单的缓存系统 |
| LIFO(后进先出) | 淘汰最后进入的数据(栈结构) | 实现简单 | 缓存命中率低(无视访问频率,可能淘汰热点数据) | 特殊场景(如回退操作,新数据价值低) |
| MRU(最近最多使用) | 淘汰最近最多使用的数据 | 适合访问局部性强的场景(如用户浏览信息流,看过内容不再看) | 可能频繁淘汰缓存,降低命中率 | 数据访问模式具有“看后即弃”特性(如信息流推荐) |
| LRU(最近最少使用) | 淘汰最近最少被使用的数据(基于访问时间排序) | 避免 FIFO 问题,对热点数据友好,综合性能好 | 临界区问题(热点数据在统计窗口末期无访问会被误淘汰) | 通用场景(Web 缓存、数据库缓存等) |
| LFU(最近最少频率使用) | 淘汰使用频率最低的数据(额外记录访问频率) | 解决 LRU 临界区问题,对长期热点数据保护更好 | 空间开销大(需记录频率); 频率衰减问题(旧热点难以淘汰) | 热点数据稳定,访问模式变化慢(如视频热门榜) |
【困难】缓存更新有哪些策略?⭐⭐⭐
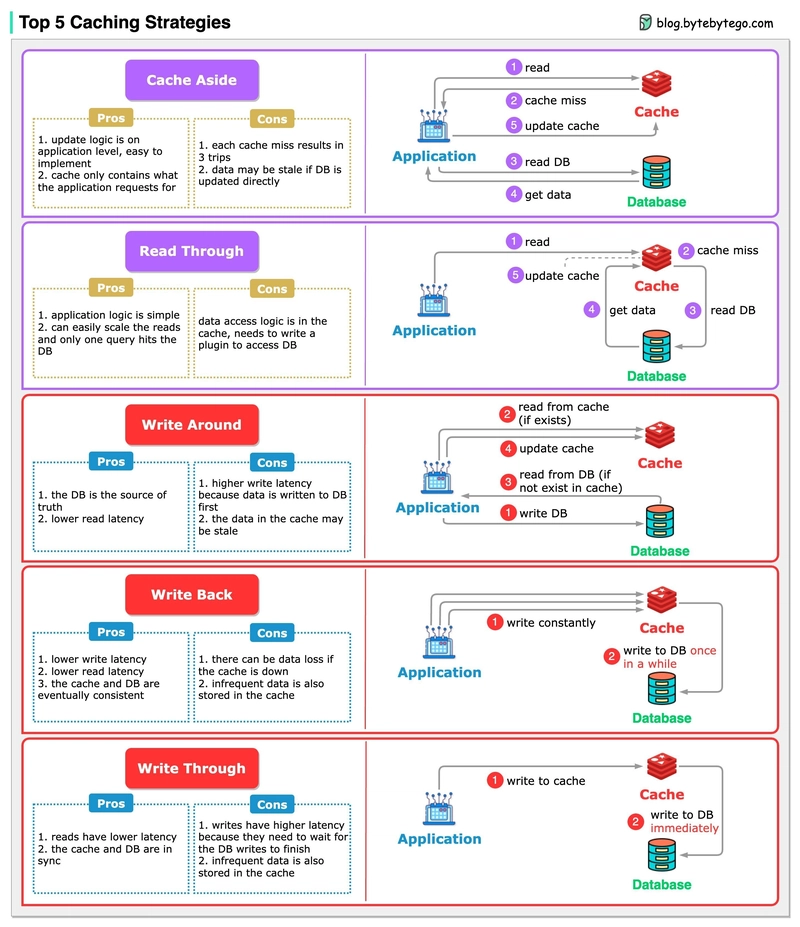
一般来说,系统如果不是严格要求缓存和数据库保持一致性的话,尽量不要将读请求和写请求串行化。串行化可以保证一定不会出现数据不一致的情况,但是它会导致系统的吞吐量大幅度下降。缓存更新的常见策略有以下几种:
- Cache Aside
- Wirte Through
- Read Though
- Wirte Behind
需要注意的是:以上几种缓存更新策略,都无法保证数据强一致。如果一定要保证强一致性,可以通过两阶段提交(2PC)或 Paxos 协议来实现。但是 2PC 太慢,而 Paxos 太复杂,所以如果不是非常重要的数据,不建议使用强一致性方案。
Cache Aside(旁路缓存)
Cache Aside 的思路是:先更新数据库,再删除缓存。具体来说:
失效:尝试读缓存,如果不命中,则读数据库,然后更新缓存。
命中:尝试读缓存,命中则直接返回数据。
更新:先更新数据库,再删除缓存。
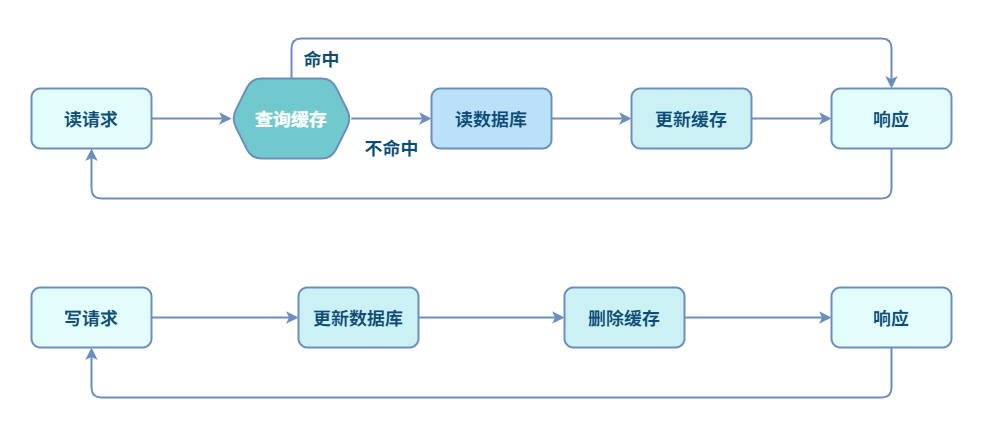
为什么不能先更新数据库,再更新缓存?
多个并发的写操作可能导致脏数据:当有多个并发的写请求时,无法保证更新数据库的顺序和更新缓存的顺序一致,从而导致数据库和缓存数据不一致的问题。
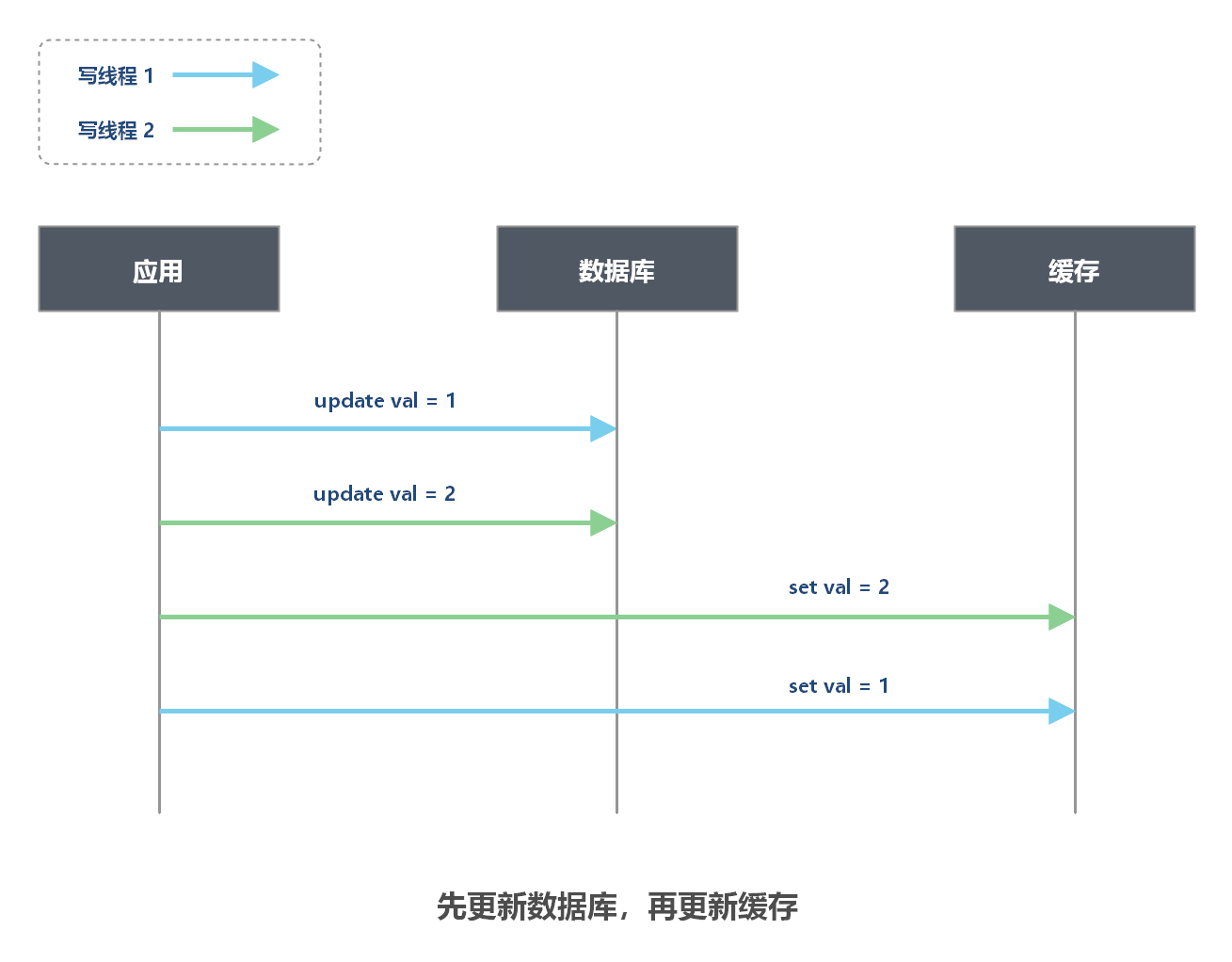
说明:如上图的场景中,两个写线程由于执行顺序,导致数据库中 val = 2,而缓存中 val = 1,数据不一致。
为什么不能先删缓存,再更新数据库?
存在并发读请求和写请求时,可能导致脏数据。
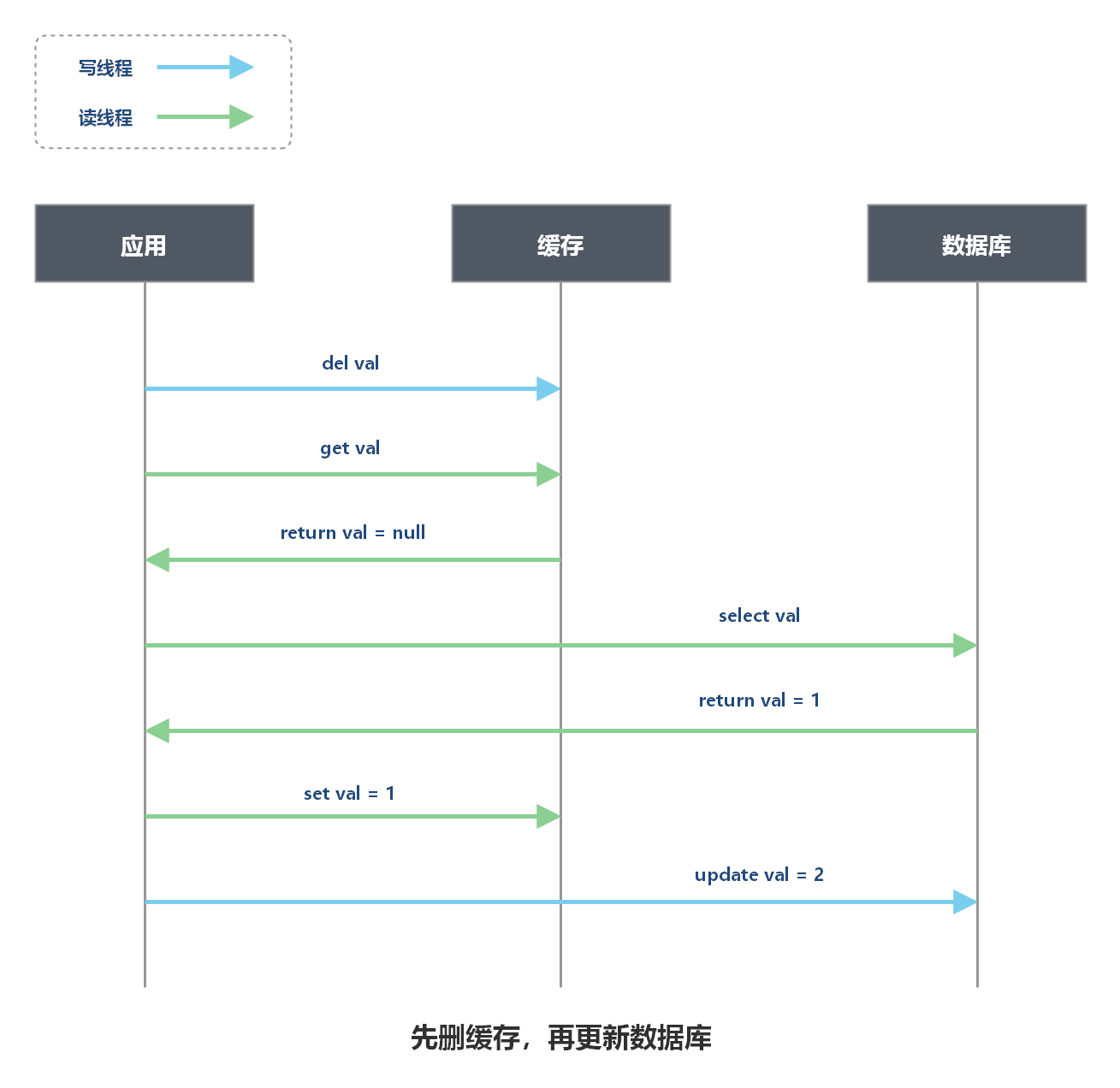
说明:如上图的场景中,读线程和写线程并行执行,导致数据库中 val = 2,而缓存中 val = 1,数据不一致。
先更新数据库,再删除缓存就没问题了吗?
存在并发读请求和写请求时,可能导致脏数据。
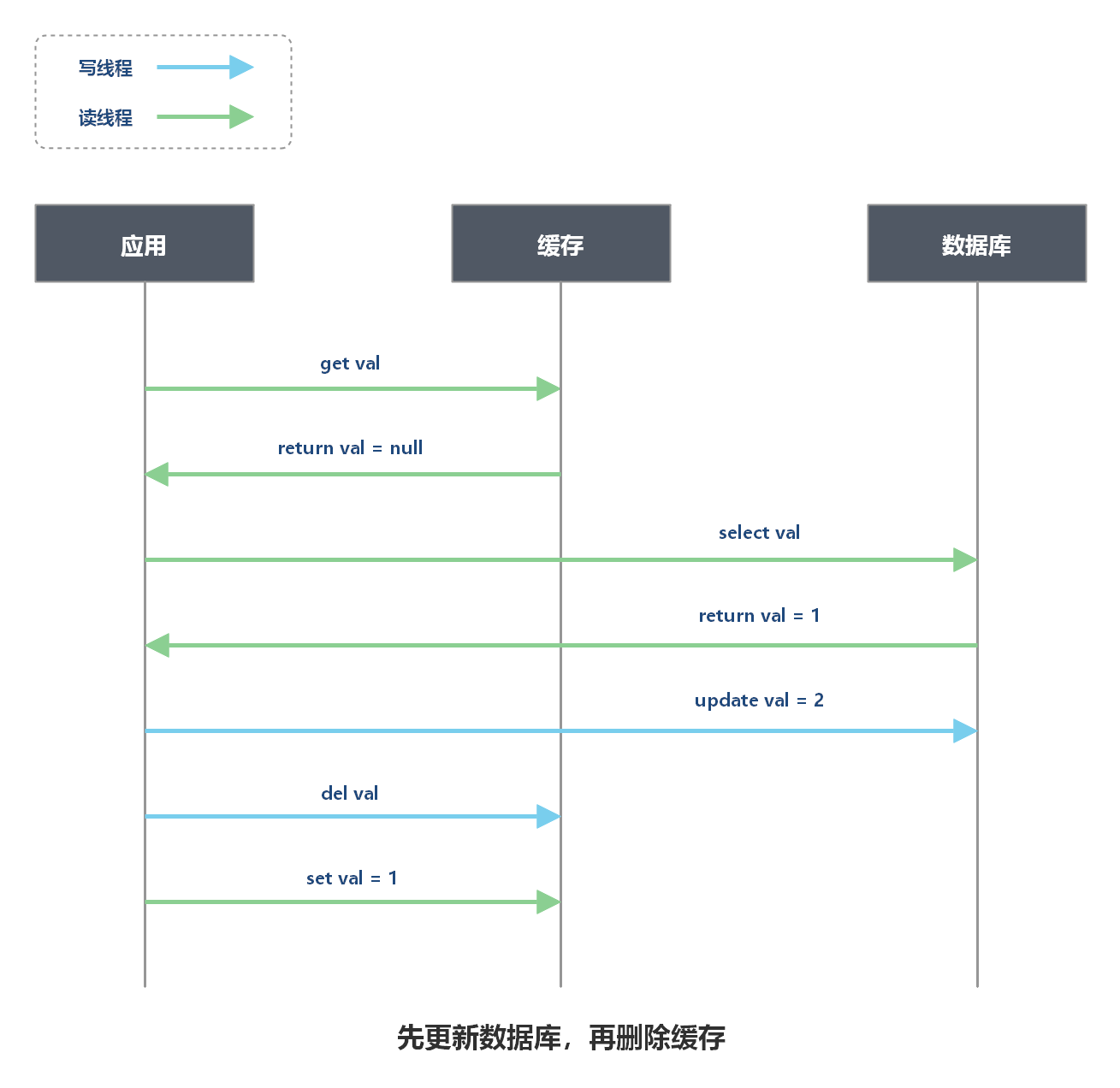
上图中问题发生的概率非常低:因为通常数据库更新操作比内存操作耗时多出几个数量级,最后一步回写缓存速度非常快,通常会在更新数据库之前完成。所以 Cache Aside 模式选择先更新数据库,再删除缓存,而不是先删缓存,再更新数据库。
不过,如果真的出现了这种场景,为了避免缓存中一直保留着脏数据,可以为缓存设置过期时间,过期后缓存自动失效。通常,业务系统中允许少量数据短时间出现不一致的情况。
Read/Write Through(读写穿透)
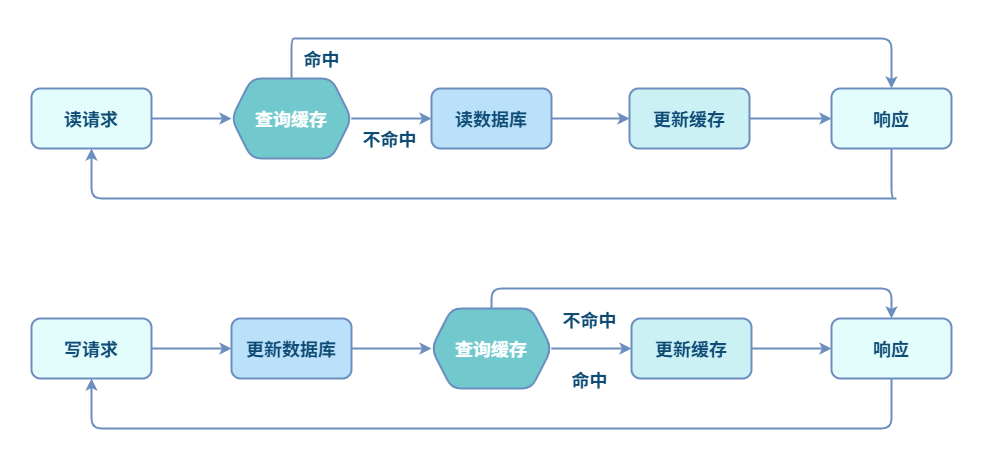
Read Through 的思路是:查询时更新缓存。当缓存失效时,缓存服务自己进行加载。
Write Through 的思路是:当数据更新时,缓存服务负责更新缓存。
Read/Write Through vs. Cache Aside
- Cache Aside 模式中,应用需要维护两个数据源头:一个是缓存,一个是数据库。
- Read-Through 模式中,应用无需管理缓存和数据库,只需要将数据库的同步委托给缓存服务即可。
Write behind(异步回写)
Write Behind 又叫 Write Back。Write Behind 的思路是:应用更新数据时,只更新缓存, 缓存服务每隔一段时间将缓存数据批量更新到数据库中,即延迟写入。这个设计的好处就是让提高 I/O 效率,因为异步,Write Behind 还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
Refresh Ahead(预刷新)
- 原理:缓存过期前主动刷新,避免用户等待
- 优点:减少延迟,体验更平滑
- 缺点:可能浪费资源(预刷新未访问的数据)
【困难】多级缓存架构如何设计?⭐
一般来说,多级缓存架构使用二级缓存已可以满足大部分业务需求,过多的分级会增加系统的复杂度以及维护的成本。因此,多级缓存不是分级越多越好,需要根据实际情况进行权衡。
一个典型的二级缓存架构,可以使用进程内缓存(如: Caffeine/Google Guava/Ehcache/HashMap)作为一级缓存;使用分布式缓存(如:Redis/Memcached)作为二级缓存。
多级缓存查询
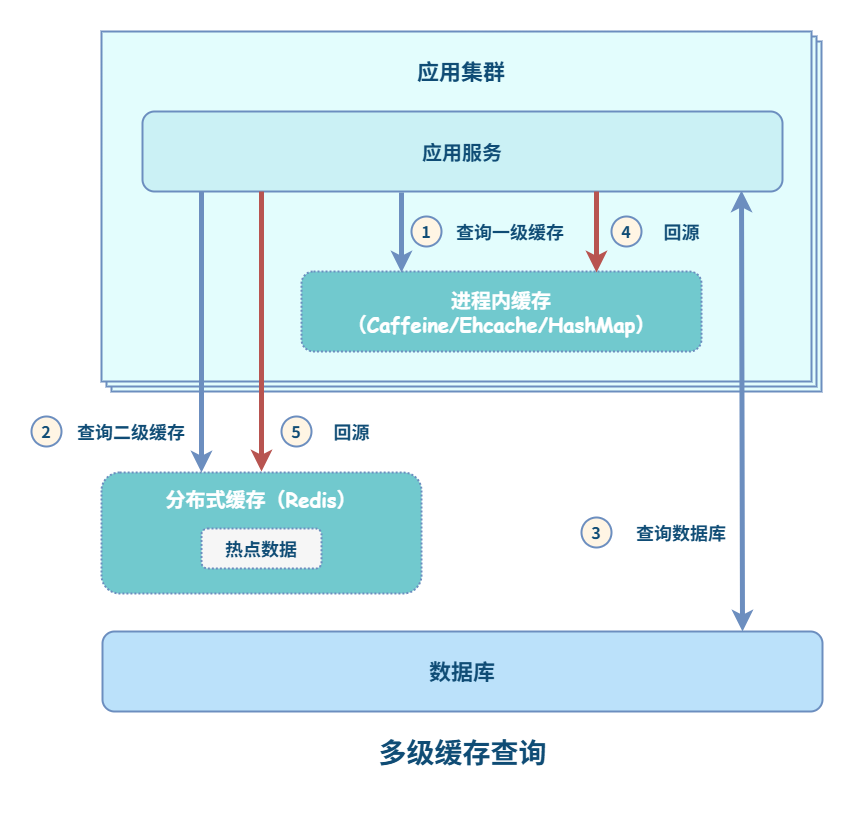
多级缓存查询流程如下:
- 首先,查询 L1 缓存,如果缓存命中,直接返回结果;如果没有命中,执行下一步。
- 接下来,查询 L2 缓存,如果缓存命中,直接返回结果并回填 L1 缓存;如果没有命中,执行下一步。
- 最后,查询数据库,返回结果并依次回填 L2 缓存、L1 缓存。
多级缓存更新
对于 L1 缓存,如果有数据更新,只能删除并更新所在机器上的缓存,其他机器只能通过超时机制来刷新缓存。超时设定可以有两种策略:
- 设置成写入后多少时间后过期
- 设置成写入后多少时间刷新
对于 L2 缓存,如果有数据更新,其他机器立马可见。但是,也必须要设置超时时间,其时间应该比 L1 缓存的有效时间长。
为了解决进程内缓存不一致的问题,设计可以进一步优化:
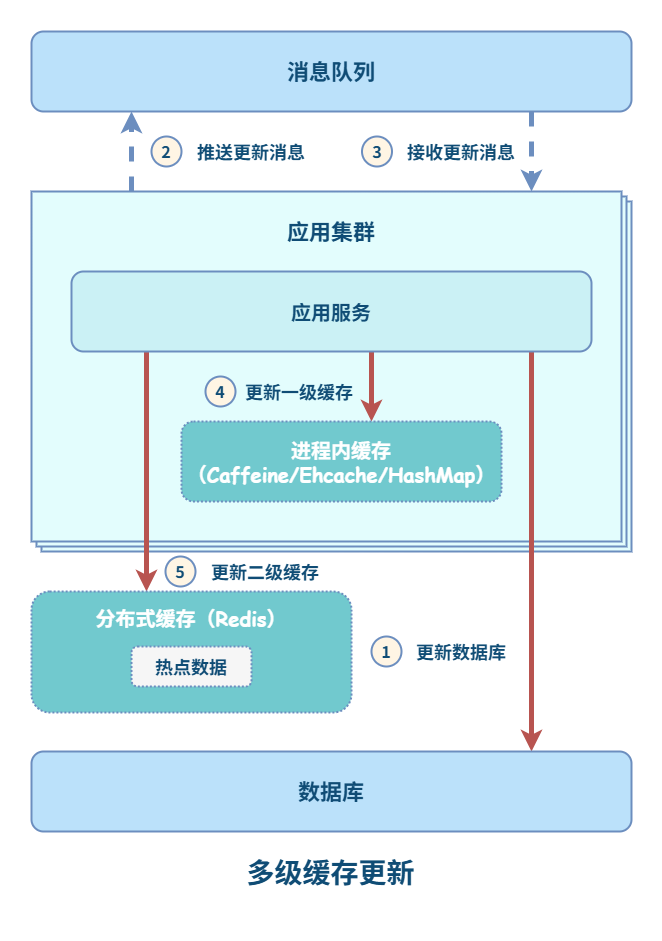
通过消息队列的发布、订阅机制,可以通知其他应用节点对进程内缓存进行更新。使用这种方案,即使消息队列服务挂了或不可靠,由于先执行了数据库更新,但进程内缓存过期,刷新缓存时,也能保证数据的最终一致性。
【中等】什么是缓存雪崩?如何应对?⭐⭐⭐
“缓存雪崩”是指,缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
举例来说,对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机。缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后就挂了。此时,如果没有采用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。
解决缓存雪崩的主要手段如下:
- 增加缓存系统可用性(事前)。例如:部署 Redis Cluster(主从+哨兵),以实现 Redis 的高可用,避免全盘崩溃。
- 采用多级缓存方案(事中)。例如:本地缓存(Ehcache/Caffine/Guava Cache) + 分布式缓存(Redis/ Memcached)。
- 限流、降级、熔断方案(事中),避免被流量打死。如:使用 Hystrix 进行熔断、降级。
- 缓存如果支持持久化,可以在恢复工作后恢复数据(事后)。如:Redis 支持持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
上面的解决方案简单来说,就是多级缓存方案。系统收到一个查询请求,先查本地缓存,再查分布式缓存,最后查数据库,只要命中,立即返回。
解决缓存雪崩的辅助手段如下:
- 监控缓存,弹性扩容。
- 缓存的过期时间可以取个随机值。这么做是为避免缓存同时失效,使得数据库 IO 骤升。比如:以前是设置 10 分钟的超时时间,那每个 Key 都可以随机 8-13 分钟过期,尽量让不同 Key 的过期时间不同。
【中等】什么是缓存穿透?如何应对?⭐⭐⭐
“缓存穿透”是指,查询的数据在数据库中不存在,那么缓存中自然也不存在。所以,应用在缓存中查不到,则会去查询数据库,当这样的请求多了后,数据库的压力就会增大。
解决缓存穿透,一般有两种方法:
(一)缓存空值
对于返回为 NULL 的依然缓存,对于抛出异常的返回不进行缓存。

采用这种手段的会增加我们缓存的维护成本,需要在插入缓存的时候删除这个空缓存,当然我们可以通过设置较短的超时时间来解决这个问题。
(二)过滤不可能存在的数据
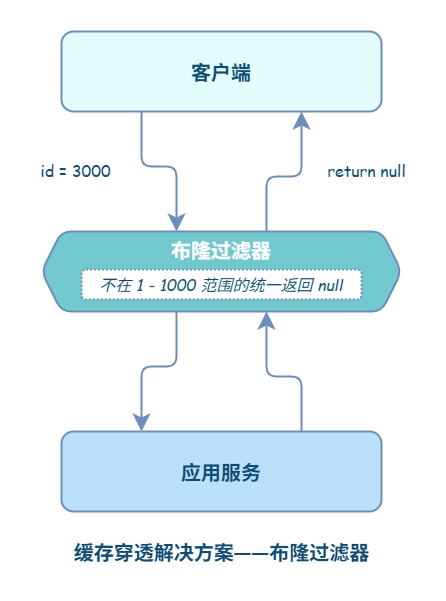
制定一些规则过滤一些不可能存在的数据。可以使用布隆过滤器(针对二进制操作的数据结构,所以性能高),比如你的订单 ID 明显是在一个范围 1-1000,如果不是 1-1000 之内的数据那其实可以直接给过滤掉。
针对于一些恶意攻击,攻击带过来的大量 key 是不存在的,那么我们采用第一种方案就会缓存大量不存在 key 的数据。
此时我们采用第一种方案就不合适了,我们完全可以先对使用第二种方案进行过滤掉这些 key。
针对这种 key 异常多、请求重复率比较低的数据,我们就没有必要进行缓存,使用第二种方案直接过滤掉。
而对于空数据的 key 有限的,重复率比较高的,我们则可以采用第一种方式进行缓存。
【中等】什么是缓存击穿?如何应对?⭐⭐⭐
“缓存击穿”是指,热点缓存数据失效瞬间,大量请求直接访问数据库。例如,某些 key 是热点数据,访问非常频繁。如果某个 key 失效的瞬间,大量的请求过来,缓存未命中,然后去数据库访问,此时数据库访问量会急剧增加。
为了避免这个问题,我们可以采取下面的两个手段:
- 分布式锁 - 锁住热点数据的 key,避免大量线程同时访问同一个 key。
- 定时异步刷新 - 可以对部分数据采取失效前自动刷新的策略,而不是到期自动淘汰。淘汰其实也是为了数据的时效性,所以采用自动刷新也可以。
【中等】如何保证 Redis 中始终是热点数据?
淘汰策略 + 读时缓存 + 过期时间 + 预热 + 监控,让 Redis 自动保留热点数据,冷数据自然淘汰。
选择合适的内存淘汰策略
Redis 提供多种内存淘汰策略,其中最适合热点数据的是基于访问频率或最近访问时间的策略:
- allkeys-lru:从所有键中淘汰最近最少使用的数据。
- volatile-lru:从设置了过期时间的键中淘汰最近最少使用的数据。
- allkeys-lfu(Redis 4.0+):从所有键中淘汰最不经常使用的数据,更精确地统计访问频率。
- volatile-lfu:从设置了过期时间的键中淘汰最不经常使用的数据。
推荐使用 allkeys-lfu 或 allkeys-lru,让 Redis 自主淘汰冷数据,保留热点。
采用 Cache-Aside 模式(读时缓存)
- 查询流程:先读 Redis,命中则直接返回;未命中则查 MySQL,将结果写入 Redis(并设置合理的过期时间),再返回。
- 这种模式自然地将被访问的数据加入缓存,未被访问的数据不会进入 Redis。结合淘汰策略,长时间未被访问的数据会被逐步淘汰,留下的始终是最近/最常访问的数据。
差异化过期时间
- 对于已知的热点类别(如爆款商品、热门用户),可以设置较长的过期时间(如 1 天)。
- 对于普通数据,设置较短的过期时间(如 30 分钟),让冷数据快速失效,减少内存占用。
- 过期时间应结合业务访问规律动态调整,避免集中失效导致缓存雪崩。
预加载(预热)
- 通过离线分析 MySQL 访问日志(如慢查询日志、业务统计),统计出高频访问的数据列表。
- 在系统低峰期或启动时,将这些数据提前加载到 Redis 中,并设置合适的过期时间。
- 预热可以确保核心热点从一开始就存在于缓存中,避免首次访问时的穿透。
监控与动态调整
- 监控 Redis 的内存使用、命中率、淘汰键数量等指标。
- 如果命中率持续偏低,说明缓存内容与热点不匹配,可能需要调整淘汰策略、过期时间或增加内存。
- 可以记录被淘汰的 key,分析是否为误淘汰,从而优化策略。
读写分离
【简单】什么是读写分离?为什么需要读写分离?
读写分离将数据库的读操作和写操作分离到不同的数据库实例。
读写分离作用
- 有效减少锁竞争 - 主服务器只负责写,从服务器只负责读,能够有效的避免由数据更新导致的行锁竞争,使得整个系统的查询性能得到极大的改善。
- 提高查询吞吐量 - 通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。
- 提升数据库可用性 - 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升数据库的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
读写分离工作原理
- 写操作:所有写请求(增删改)只发送到主库
- 数据同步:主库通过复制机制将数据变更同步到从库
- 读操作:读请求分发到多个从库(负载均衡)
- 延迟处理:需处理主从同步延迟带来的数据不一致问题
【中等】如何实现读写分离?
读写分离的基本原理是:主服务器用来处理写操作以及实时性要求比较高的读操作,而从服务器用来处理读操作。
读写分离的实现是根据 SQL 语义分析,将读操作和写操作分别路由至主库与从库。
读写分离有两种实现方式:代码封装、中间件。以下是两种方案的对比:
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 代码封装 | 业务层通过代理类路由读写请求(读走从库,写走主库)。 | 简单灵活,可定制化 - 适合业务特定需求 | 主从切换需修改配置并重启 - 多语言需重复开发 |
| 中间件 | 独立代理服务(如 MySQL-Proxy、ShardingSphere),客户端无感知。 | 屏蔽多语言差异,统一管理数据源 | 有额外维护成本,可能成为性能瓶颈 |
结论:代码封装适合简单架构,但扩展性差;中间件适合复杂架构,但需维护。
常见的读写分离中间件
- MySQL-Proxy(官方)
- Atlas(360)
- ShardingSphere(Apache)
- Mycat
分库分表
【简单】什么是分库分表?为什么需要分库分表?
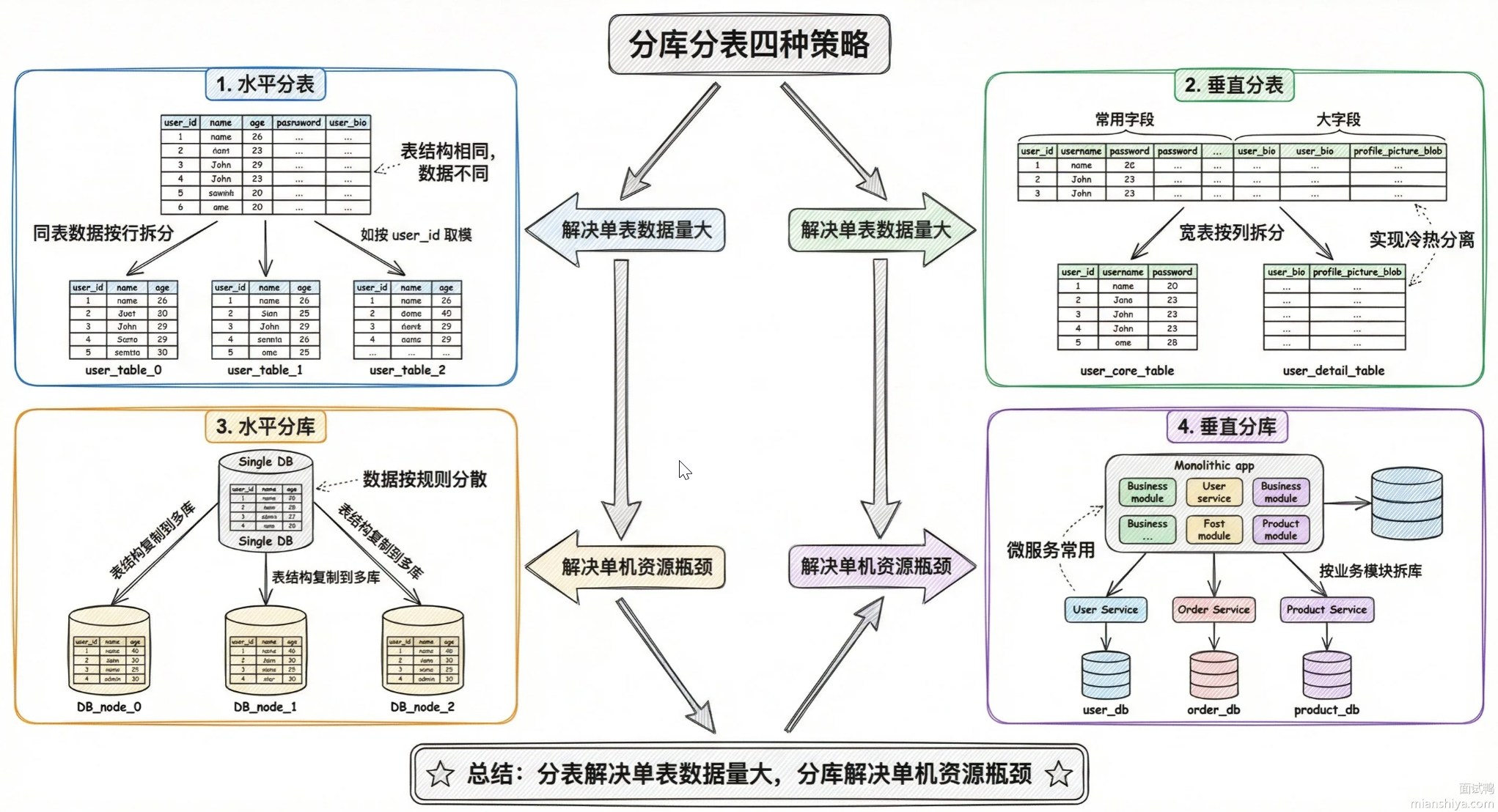
什么是分库分表?
分库分表是一种数据库水平拆分方案,用于解决单机数据库的存储瓶颈和性能瓶颈问题。
- 分库:将数据分散到不同的数据库实例(如
DB1、DB2)。 - 分表:将数据分散到同一数据库的不同表(如
order_1、order_2)。
为何要分库分表?
分库分表主要基于以下理由:
- 并发连接 - 一个健康的单库最好保持在每秒 1000 个并发左右,不要太大。
- 磁盘容量 - 磁盘容量占满,会导致服务器不可用。
- SQL 性能 - 单表数据量过大,会导致 SQL 执行效率低下。一般,单表超过 1000 万条数据,就可以考虑分表了。
| # | 分库分表前 | 分库分表后 |
|---|---|---|
| 并发支撑情况 | MySQL 单机部署,扛不住高并发 | MySQL 从单机到多机,能承受的并发增加了多倍 |
| 磁盘使用情况 | MySQL 单机磁盘容量几乎撑满 | 拆分为多个库,数据库服务器磁盘使用率大大降低 |
| SQL 执行性能 | 单表数据量太大,SQL 越跑越慢 | 单表数据量减少,SQL 执行效率明显提升 |
【困难】如何实现分库分表?⭐⭐
分库分表 = 选好拆分键 + 用对路由算法 + 平滑数据迁移 + 改造查询语句,核心是让数据均匀分布且查询能精准定位到分片。
数值范围路由
数值范围路由,就是根据 ID、时间范围 这类具有排序性的字段来进行划分。例如:用户 Id 为 1-9999 的记录分到第一个库,10000-20000 的分到第二个库,以此类推。
按这种策略划分出来的数据,具有数据连续性。
优点:数据迁移很简单。
缺点:容易产生热点问题,大量的流量都打在最新的数据上了。
Hash 路由
典型的 Hash 路由,如根据数值取模,当需要扩容时,一般以 2 的幂次方进行扩容(这样,扩容时迁移的数据量会小一些)。例如:用户 Id mod n,余数为 0 的记录放到第一个库,余数为 1 的放到第二个库,以此类推。
一般采用 预分区 的方式,提前根据 数据量 规划好 分区数,比如划分为 512 或 1024 张表,保证可支撑未来一段时间的 数据容量,再根据 负载情况 将 表 迁移到其他 数据库 中。扩容时通常采用 翻倍扩容,避免 数据映射 全部被 打乱,导致 全量迁移 的情况。
优点:数据离散分布,不存在热点问题。
缺点:数据迁移、扩容麻烦(之前的数据需要重新计算 hash 值重新分配到不同的库或表)。当 节点数量 变化时,如 扩容 或 收缩 节点,数据节点 映射关系 需要重新计算,会导致数据的 重新迁移。
路由表
这种策略,就是用一张独立的表记录路由信息。
优点:简单、灵活,尤其是在扩容、迁移时,只需要迁移指定的数据,然后修改路由表即可。
缺点:每次查询,必须先查路由表,增加了 IO 开销。并且,如果路由表本身太大,也会面临性能瓶颈,如果想对路由表再做分库分表,将出现死循环式的路由算法选择问题。
【困难】分库分表存在哪些问题?⭐⭐
分库分表主要存在以下问题:
- 分布式 ID 问题
- 分布式事务问题
- 跨节点 Join 和聚合
- 跨节点的排序分页
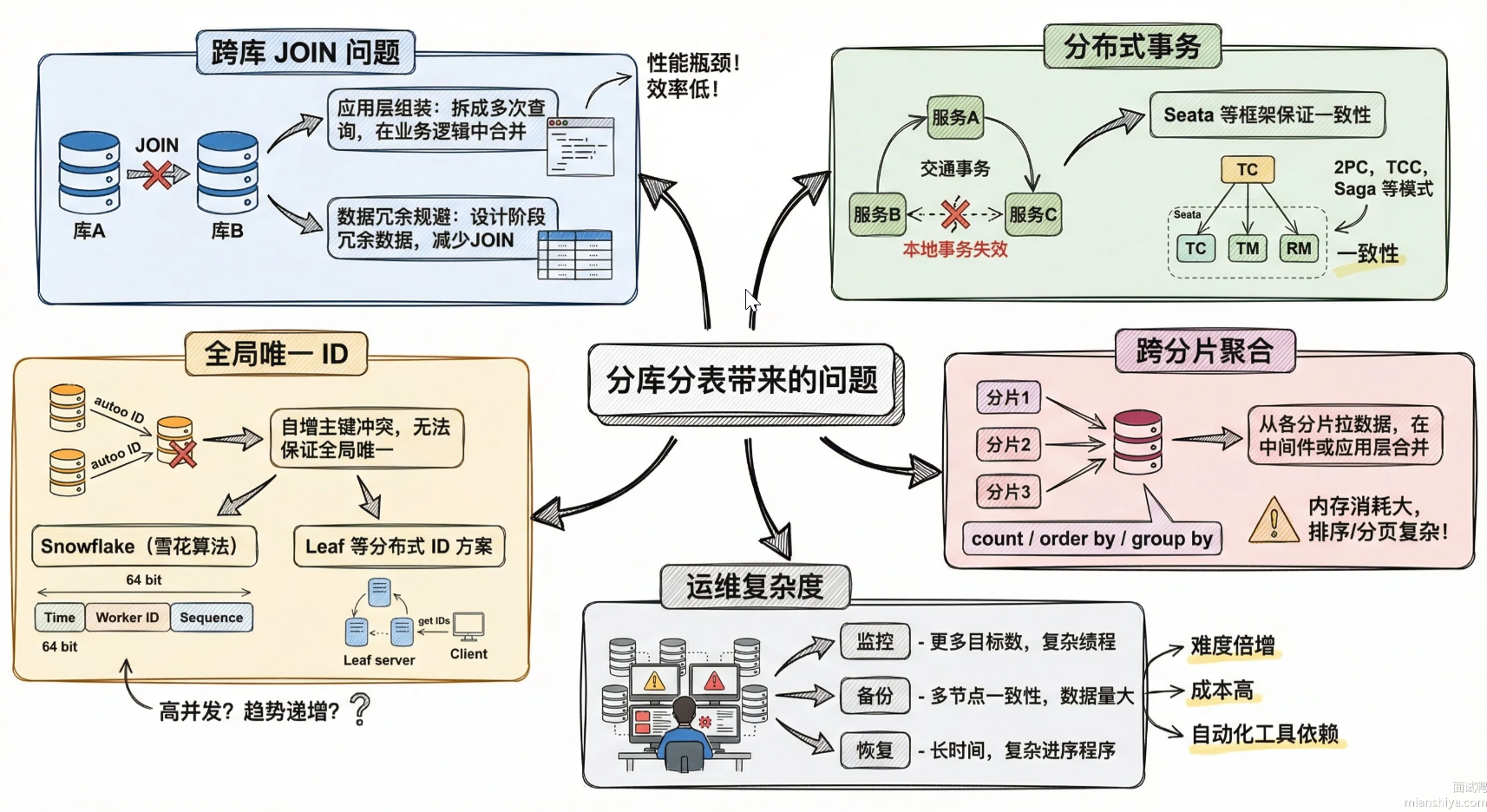
分布式 ID 问题
一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的 ID 无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得 ID,以便进行 SQL 路由。
分布式 ID 的解决方案详见:分布式 ID
分布式事务问题
跨库事务也是分布式的数据库集群要面对的棘手事情。 合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于 XA 的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。
分布式事务的解决方案详见:分布式事务
跨节点 Join 和聚合
分库分表后,无法直接跨节点 join 、count、order by、group by 以及聚合。
针对这类问题,普遍做法是二次查询。
在第一次查询时,获取各个节点上的结果。
在程序中将这些结果进行合并、筛选。
跨节点的排序分页
一般来讲,分页时需要按照指定字段进行排序。当排序字段就是分片字段的时候,我们通过分片规则可以比较容易定位到指定的分片,而当排序字段非分片字段的时候,情况就会变得比较复杂了。为了最终结果的准确性,我们需要在不同的分片节点中将数据进行排序并返回,并将不同分片返回的结果集进行汇总和再次排序,最后再返回给用户。如下图所示:
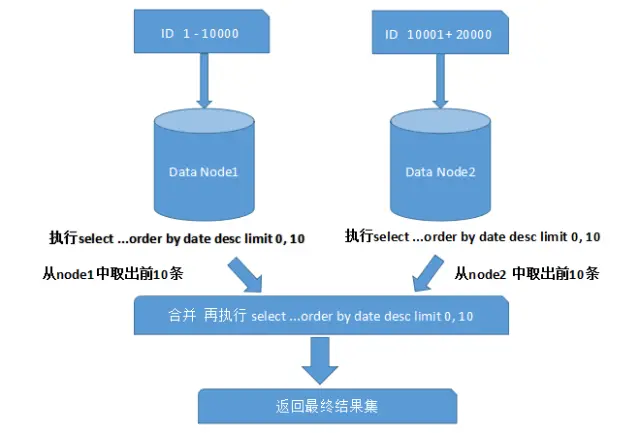
上面图中所描述的只是最简单的一种情况(取第一页数据),看起来对性能的影响并不大。但是,如果想取出第 10 页数据,情况又将变得复杂很多,如下图所示:
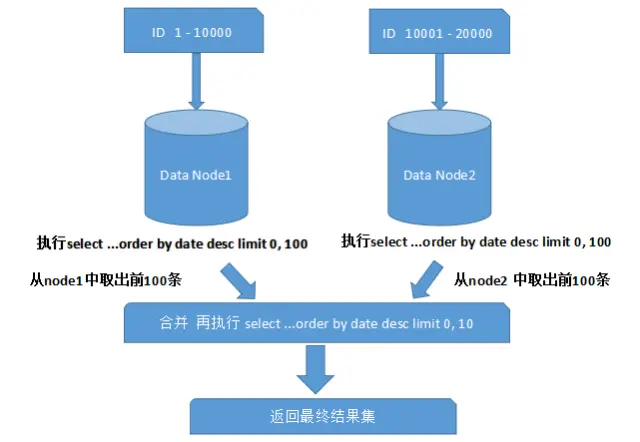
有些读者可能并不太理解,为什么不能像获取第一页数据那样简单处理(排序取出前 10 条再合并、排序)。其实并不难理解,因为各分片节点中的数据可能是随机的,为了排序的准确性,必须把所有分片节点的前 N 页数据都排序好后做合并,最后再进行整体的排序。很显然,这样的操作是比较消耗资源的,用户越往后翻页,系统性能将会越差。
那如何解决分库情况下的分页问题呢?有以下几种办法:
如果是在前台应用提供分页,则限定用户只能看前面 n 页,这个限制在业务上也是合理的,一般看后面的分页意义不大(如果一定要看,可以要求用户缩小范围重新查询)。
如果是后台批处理任务要求分批获取数据,则可以加大 page size,比如每次获取 5000 条记录,有效减少分页数(当然离线访问一般走备库,避免冲击主库)。
分库设计时,一般还有配套大数据平台汇总所有分库的记录,有些分页查询可以考虑走大数据平台。
【困难】如何实现迁库和扩容?⭐⭐
停机迁移/扩容(不推荐)
停机迁移/扩容是最暴力、最简单的迁移、扩容方案。

停机迁移/扩容流程:
- 预估停服时间,发布停服公告;停服,不允许数据访问。
- 编写临时的数据导入程序,从老数据库中读取数据。
- 将数据写入中间件。
- 中间件根据分片规则,将数据分发到分库(分表)中。
- 应用程序修改配置,重启。
停机迁移/扩容方案分析:
- 优点:简单、无数据一致性问题。
- 缺点:
- 停服时间长(数据量大时可能需数小时)。
- 风险高,失败后难以回滚。
结论:代价过高,不推荐使用。
双写迁移
双写迁移方案核心思想:
- 新旧库同时写入,通过开关控制读写状态(只写旧库、只写新库、双写)。
- 逐步切换读请求到新库,确保数据一致性。
双写迁移方案关键步骤:
- 双写阶段:先写旧库,再写新库,以旧库结果为准。记录旧库成功但新库失败的日志,用于补偿。
- 数据校验:运行对比程序,检查新旧库数据差异并修复。
- 灰度切换读请求:逐步将读流量切至新库,观察稳定性。
- 最终切换:读写全部切至新库,清理旧库冗余数据。
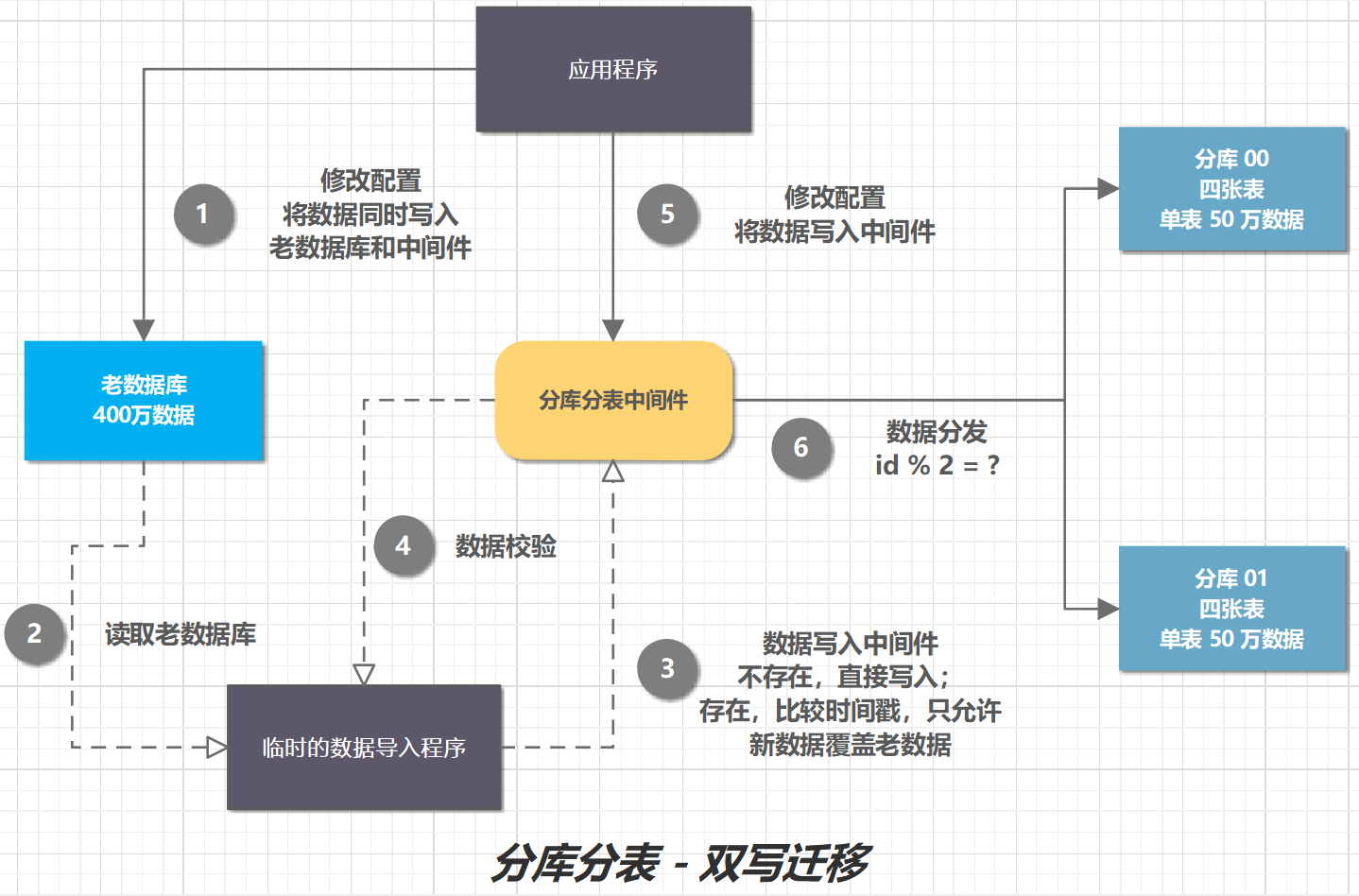
双写迁移流程:
- 修改应用程序配置,将数据同时写入老数据库和中间件。这就是所谓的双写,同时写俩库,老库和新库。
- 编写临时程序,读取老数据库。
- 将数据写入中间件。如果数据不存在,直接写入;如果数据存在,比较时间戳,只允许新数据覆盖老数据。
- 导入数据后,有可能数据还是存在不一致,那么就对数据进行校验,比对新老库的每条数据。如果存在差异,针对差异数据,执行(3)。循环(3)、(4)步骤,直至数据完全一致。
- 修改应用程序配置,将数据只写入中间件。
- 中间件根据分片规则,将数据分发到分库(分表)中。
双写迁移方案分析:
优点:
- 无需停服,业务影响小。
- 可灰度验证,风险可控。
缺点:
- 实现复杂,需处理双写一致性和补偿逻辑。
主从替换
生产环境的数据库,为了保证高可用,一般会采用主从架构。主库支持读写操作,从库支持读操作。
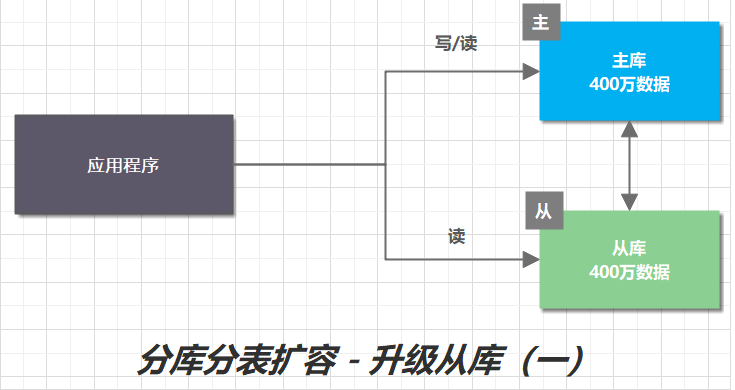
由于主从节点数据一致,所以将从库升级为主节点,并修改分片配置,将从节点作为分库之一,就实现了扩容。
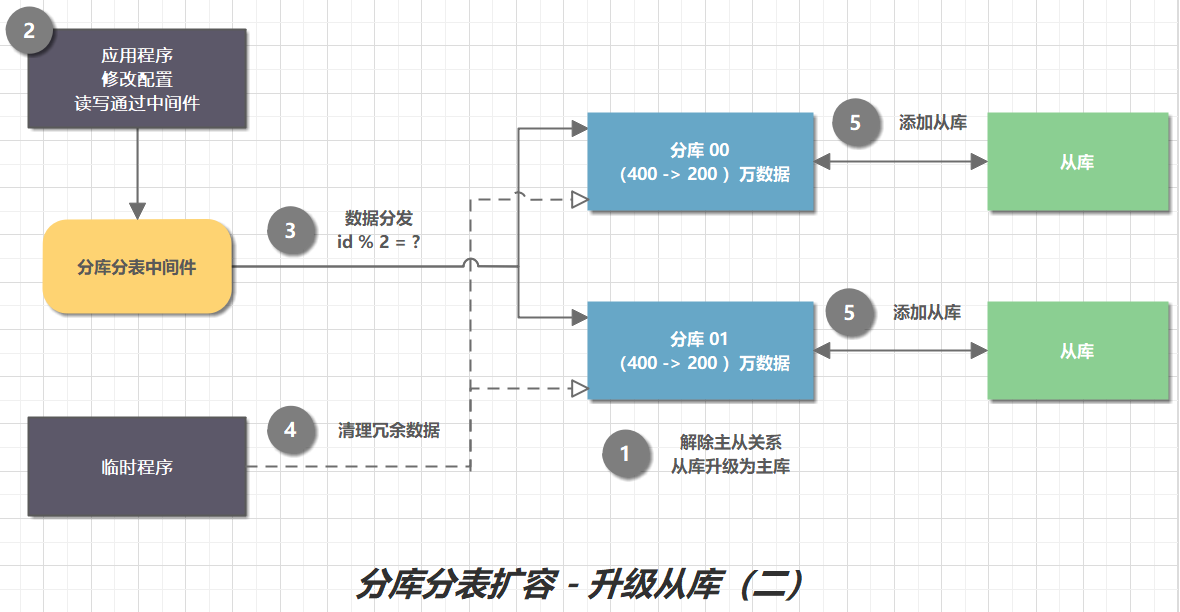
主从替换方案流程:
- 解除主从关系,从库升级为主库。
- 应用程序,修改配置,读写通过中间件。
- 分库分表中间,修改分片配置。将数据按照新的规则分发。
- 编写临时程序,清理冗余数据。比如:原来是一个单库,数据量为 400 万。从节点升级为分库之一后,每个分库都有 400 万数据,其中 200 万是冗余数据。清理完后,进行数据校验。
- 为每个分库添加新的从库,保证高可用。
主从替换方案分析:
- 无需停机,无需全量数据迁移。
- 利用现有从库资源,节省成本。
三种方案对比
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 停机迁移 | 小规模数据,容忍停服 | 简单,无一致性问题 | 停服时间长,风险高 |
| 双写迁移 | 大规模数据,要求高可用 | 无停服,灰度可控 | 复杂,需补偿机制 |
| 主从替换 | 已有主从架构 | 无需迁移数据,快速扩容 | 依赖现有从库,清理冗余复杂 |
推荐选择:
- 优先双写迁移:适合大多数业务,平衡风险与复杂度。
- 主从升级:适合已有主从且数据量适中的场景。
- 避免停机迁移:除非数据量极小且可接受停服。