设计面试
设计面试
架构设计
【中等】一个单体项目整体吞吐达到 1 万 QPS,要微服务化拆分吗?⭐
QPS 1w 不是微服务拆分的理由。
微服务拆分的首要驱动力是业务复杂度和团队协作,而不是单纯的高并发。
单体如何扛住 1w QPS?
| 手段 | 说明 | 效果 |
|---|---|---|
| 缓存 | Redis 挡住 90% 的读请求 | 读 QPS 1w → DB 1k |
| 异步 | MQ 削峰填谷,异步处理写请求 | 写流量平滑,系统不垮 |
| 集群 | 单体水平扩容,前面挂 Nginx | 3 台机器即可分担 1w QPS |
| 数据库优化 | 索引、分库分表(必要时) | 数据库不再是瓶颈 |
微服务拆分的考量维度?
| 维度 | 需要拆分的信号 | 记忆点 |
|---|---|---|
| 团队(团队规模与协作) | 团队 > 10 人,多个小组并行开发,频繁代码冲突、互相等待发版 | 人少别折腾,人多再拆分 |
| 业务(业务复杂度与边界) | 模块间耦合严重(如订单和用户表 JOIN 过多),改一处影响多处 | 业务耦合难维护,拆清边界各自顾 |
| 技术(技术异构需求) | 部分模块需不同技术栈(如 Go 写高并发,Python 做 AI) | 技术栈要换,微服务来担 |
| 资源(资源独立性与隔离) | 某个模块(如秒杀)占满 CPU 或内存,导致其他模块响应变慢 | 资源争抢乱,拆分各自安 |
| 运维(运维与发布频率) | 核心模块需每周发版,非核心模块每日发版,但发版必须一起停服 | 发布频率不一致,独立部署最合适 |
| 性能(性能独立扩缩容) | 秒杀模块需要瞬间扩容 10 倍,但其他模块不需要,单体只能一起扩,浪费资源 | 部分模块要扩缩,拆分才能单独做 |
决策清单:什么时候该拆?
如果以下问题有 3 个以上回答“是”,可以考虑启动微服务拆分:
- 代码冲突:合并代码时经常需要跟同事沟通解决冲突吗?
- 互相等待:A 组的功能上线必须等 B 组的功能一起发布吗?
- 局部故障扩散:一个模块出问题(如内存泄露)导致整个系统崩溃吗?
- 扩容浪费:秒杀活动时,不得不把整个系统(包括不相关的模块)一起扩容吗?
- 技术束缚:想用新的技术框架(如 Go 写高性能模块),但因为单体无法引入吗?
- 数据库耦合:所有业务都挤在一个数据库里,连表查询越来越多,越来越慢吗?
【中等】项目上线后,一般要关注哪些指标?⭐
新项目上线需监控四类指标:
- 性能指标:QPS、RT、吞吐量 → 系统能不能扛住?
- 错误指标:错误率、异常日志量 → 服务稳不稳定?
- 资源指标:CPU、内存、磁盘IO、网络带宽 → 资源够不够用?
- 业务指标:PV/UV、核心接口调用量、核心转化率、留存率 → 业务跑得顺不顺?
【困难】跨海外业务请求延迟大怎么办?
核心思路:物理距离不可改变,根本在于避免或减少实时跨国数据传输。
记忆点:本地部署降延迟,异步同步防跨海,网络压缩辅优化。
- 服务本地化:在目标区域部署完整应用和数据库,用户请求在本地闭环,大幅降低延迟。
- 数据预同步:通过异步机制(主从复制、消息队列)提前将数据推送至海外,避免实时跨海读写。
- 网络优化:无法避免的实时请求,使用 CDN、专线或 SD-WAN 优化路径,并启用数据压缩(Gzip、Snappy)减少传输体积。
系统设计
【困难】如何设计一个秒杀系统?⭐⭐⭐
秒杀系统所要应对的场景就是:瞬时海量请求。
秒杀系统的难点
- 高并发:秒杀系统是极致的高并场景发自不用说。其高并发可以细分为二:
- 并发读:主要是读取剩余库存量以及商品信息
- 并发写:主要是下单后,系统写入订单记录
- 超卖:秒杀系统中售卖的商品一般都是性价比很高,不怎么赚钱,甚至赔钱赚哟喝的商品。一旦出现超卖现象,会给商家带来巨大的经济损失。从系统层面来看,比如某秒杀商品本来库存 100 件,但是在高并发场景下,瞬时下单量超过 100 件,处理不当,让这些下单都成功了,就会出现超卖。
- 恶意请求:有些人为了低价购入秒杀商品,通过在多台机器上跑脚本,模拟大量用户抢商品的请求(走自己的路,让别人无路可走)。
- 数据库崩溃:海量请求下,如果没有 MQ 削峰,没有过载保护,让所有请求都打到数据库,那么数据库基本就挂了。数据库如果挂了,也会波及其他业务,从而可能让整个系统、网站陷入瘫痪。
- 对现有业务造成冲击
秒杀系统设计目标
秒杀系统架构的思考角度可以概括为:稳、准、快
- 稳(高可用):系统架构要满足高可用,系统要能撑住活动。
- 准(一致性):商品减库存方式非常关键,不能出现超卖。
- 快(高性能):整个请求链路,从前端到后端,依赖组件都要做到协同优化。
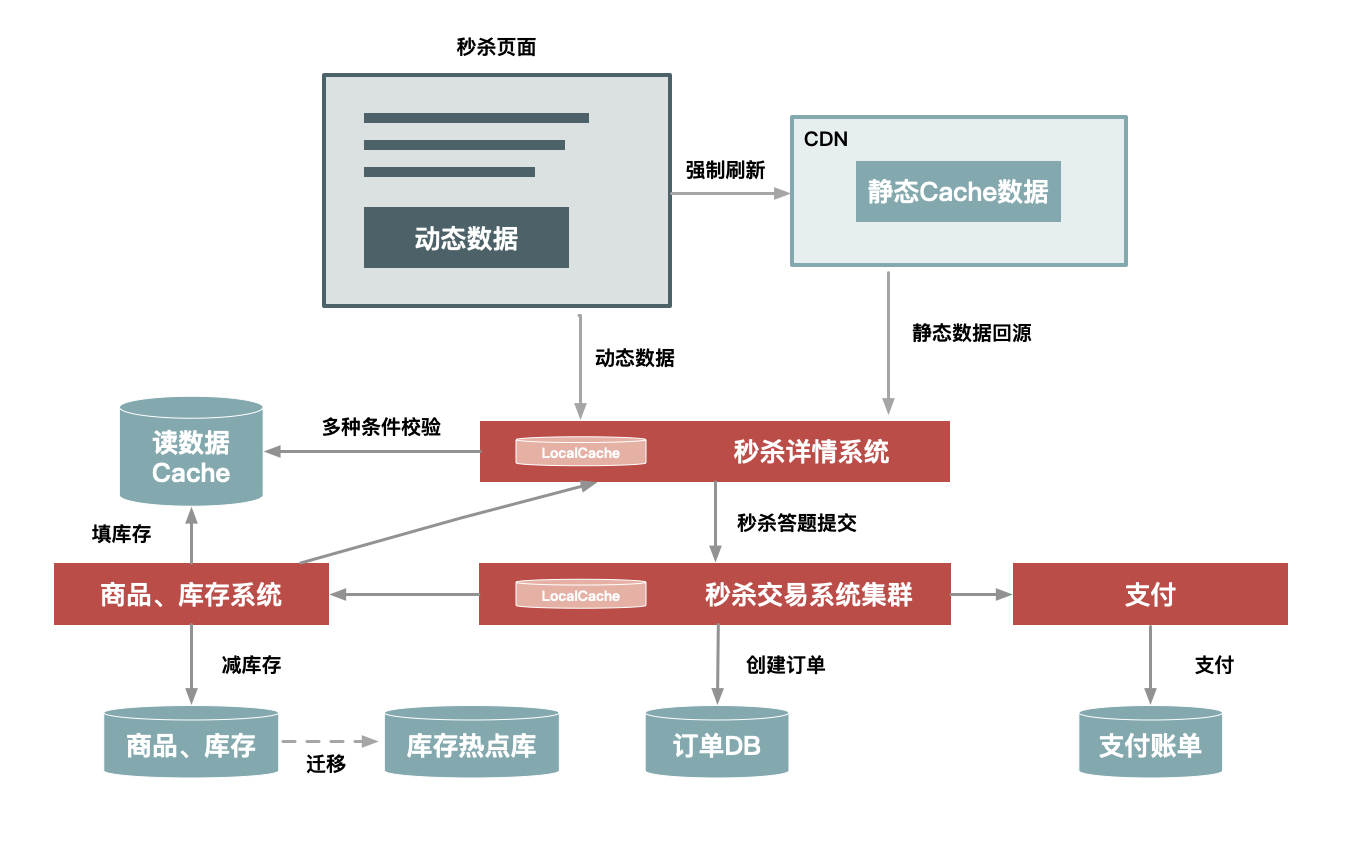
前端优化-静态页面
把秒杀商品页面静态化,减少查数据库的 IO 开销。然后,可以将这些静态页面做 CDN 缓存,如果项目是前后端分离的,还可以在反向代理服务器侧设置静态缓存。
如每个商品都由 ID 来标识,那么 http://item.xxx.com/item.htm?id=xxxx 就可以作为唯一的 URL 标识。相应的页面可以提前做前端缓存,这样就不需要向后台查询商品信息。
前端优化-按钮控制
在秒杀活动开启时间前,下单按钮禁用。
此外,按钮一旦点击之后,禁用一段时间,防止有人疯狂输出。
后端优化-限流、熔断、降级、隔离
秒杀活动,本质上还是一个营销活动,性质和打折、促销一样。
秒杀系统设计底线原则,是不应该影响现有业务。所以,为了避免防不胜防,百密一疏的情况下,秒杀系统崩了。
- 隔离:将秒杀系统、数据与其他正常业务隔离。彼此隔离,自然互不影响。
- 限流:设置阈值,超过阈值,拒绝请求。防止数据库被打死。
- 降级:保证核心业务继续工作,非核心业务各安天命。
- 熔断:不要影响别的系统。
后端优化-多级缓存
缓存要预热,避免瞬间流量冲击。
此外,防止雪崩、穿透、击穿问题的常规处理要做好。
缓存也要保证高可用。
后端优化-流量削峰
削峰的思路:排队、答题、分层过滤。
- 排队:用消息队列来缓冲瞬时流量的方案。但是,消息队列自身也有上限,如果积压过多,也会处理不了。
- 答题(摇一摇):可以限制秒杀器并延缓请求。
- 分层过滤:采用漏斗式的设计尽可能拦截无效请求。
后端优化-减库存
恶意下单
恶意下单的解决方案还是要结合安全和反作弊措施来制止:
- 识别频繁下单不付款或重复下单不付款的卖家,阻断其下单。
- 限制个人购买数
避免超卖
减库存在数据一致性上,主要就是保证大并发请求时库存数据不能为负数,也就是要保证数据库中的库存字段值不能为负数,一般我们有多种解决方案:一种是在应用程序中通过事务来判断,即保证减后库存不能为负数,否则就回滚;另一种办法是直接设置数据库的字段数据为无符号整数,这样减后库存字段值小于零时会直接执行 SQL 语句来报错;再有一种就是使用 CASE WHEN 判断语句,例如这样的 SQL 语句:
UPDATE item SET inventory = CASE WHEN inventory >= xxx THEN inventory-xxx ELSE inventory END在交易环节中,“库存”是个关键数据,也是个热点数据,因为交易的各个环节中都可能涉及对库存的查询。但是,我在前面介绍分层过滤时提到过,秒杀中并不需要对库存有精确的一致性读,把库存数据放到缓存(Cache)中,可以大大提升读性能。
后端优化-URL 动态化
通过 MD5 之类的加密算法加密随机的字符串去做 url,然后通过前端代码获取 url 后台校验才能通过。
【困难】如何设计一个文件上传系统?⭐⭐
存储选型
小厂可以直接用 OSS 云服务,如阿里云 OSS 或腾讯云 OSS。
中大厂可以基于 FastDFS、MiniIO 等服务自建。
超大文件上传
| 方案 | 实现 | 优势 |
|---|---|---|
| 分片上传 | 客户端切分成片 (1-10MB),并行上传,服务端合并 | 突破单文件大小限制,并行加速 |
| 流式上传 | 边读边传,不落本地磁盘 | 节省客户端内存 |
| 分段合并 | 服务端接收分片,异步合并 | 避免长连接占用 |
断点续传
- 客户端:记录已上传分片列表(localStorage/IndexedDB)
- 上传前:请求服务端获取已上传分片列表
- 上传时:只传缺失分片
- 完成:服务端合并
避免重复文件存储
- 客户端计算文件数字签名(采用 MD5、SHA 等算法)
- 如果文件特别大,可以将文件按固定大小切片。针对每个切片,分别取头部固定数量的字节生成签名(即分片哈希)。
- 服务端查询文件哈希值是否存在
- 存在:直接返回已有文件 URL(0 秒完成)
- 不存在:执行正常上传
哈希碰撞:文件哈希碰撞概率极低,但也不可不防:
- 首先,文件数字签名采用尽可能安全的哈希算法,如 SHA-256。
- 当数字签名相同时,再对比一下文件大小,大小不同一定不是同一文件。
- 此外,还可以抽取文件的部分字节内容进行比对。
注意:需记录文件被引用次数,引用数为零时物理删除。
文件哈希这种思路,不仅可用于避免重复文件存储,也可以用于秒传。一旦发现上传的是重复文件,直接返回上传成功。
限流
限流策略:
- 单用户:10MB/s 或 100 个文件/小时
- 单 IP:3 个并发上传
- 单文件大小:100MB(图片)/1GB(视频)
- 集群总带宽:1Gbps(Nginx 限速)
实现:令牌桶/漏桶算法 + Redis 计数器
性能设计
| 优化点 | 方案 | 效果 |
|---|---|---|
| 分片并发 | 3-5 片并行上传 | 带宽利用率提升 |
| 压缩传输 | Gzip 压缩文本文件 | 传输量减少 70% |
| CDN 加速 | 上传域名走 CDN 动态加速 | 跨地域延迟降低 |
| 就近上传 | DNS 解析就近上传节点 | 减少网络往返 |
| 内存池 | 复用缓冲区 | GC 压力降低 |
【中等】如何设计一个单点登录系统(SSO)?⭐⭐
SSO 核心是统一认证中心 + 可信凭证,子系统无需存储用户信息,仅校验凭证。
技术选型:前后端分离 / 微服务选 JWT,传统 Web 选 CAS,第三方授权选 OAuth2.0。
关键保障:凭证防篡改、登出同步、高可用部署,避免单点故障。
核心组件
| 组件 | 作用 |
|---|---|
| 认证中心(SSO Server) | 唯一登录入口,负责用户身份校验、颁发凭证、登出同步 |
| 子系统(SSO Client) | 业务系统(如订单、商品、支付系统),依赖认证中心验证用户身份 |
| 凭证(Token/Ticket) | 认证中心颁发的身份标识(如 JWT、ST 票),用于子系统校验 |
| 用户 | 访问各子系统的终端用户 |
步骤 1、选择 SSO 实现方案
| 方案 | 核心逻辑 | 适用场景 |
|---|---|---|
| Token 方案(JWT) | 认证中心生成 JWT Token,子系统本地验签(无需回调认证中心) | 前后端分离、微服务、跨域(APP / 小程序) |
| CAS 协议(票据) | 子系统跳转认证中心登录,认证中心返回 ST 票,子系统回调认证中心验票 | 传统 Web 系统、需严格会话控制 |
| OAuth2.0(授权) | 子系统申请授权,认证中心颁发 Access Token,用于访问用户资源 | 第三方授权登录(如微信 / 支付宝登录) |
步骤 2、设计凭证机制(凭证防篡改)
- JWT Token(推荐):
- 结构:Header(加密算法)+ Payload(用户 ID / 过期时间)+ Signature(签名);
- 核心:子系统用公钥验签,无需调用认证中心,性能高;
- 防护:设置短过期时间(如 1 小时),配合刷新令牌(Refresh Token)续期,Token 不可篡改。
- 票据(CAS 方案):
- TGT:用户登录后认证中心生成的会话凭证(存服务端);
- ST:子系统跳转时,认证中心基于 TGT 生成的一次性票据,子系统回调认证中心校验 ST 有效性。
步骤 3、设计登录流程(以 JWT 为例)
- 用户访问子系统 A,未登录则跳转至认证中心;
- 用户在认证中心输入账号密码,校验通过后,认证中心生成 JWT Token(含用户 ID、过期时间),返回给用户;
- 用户携带 Token 访问子系统 A,子系统 A 验签通过后,建立本地会话,实现登录;
- 用户访问子系统 B,携带同一 Token,子系统 B 验签通过后,直接免登。
步骤 4、设计登出流程(关键防残留)
- 用户在任一子系统发起登出请求,跳转至认证中心;
- 认证中心:
- 若用 JWT:将 Token 加入 Redis 黑名单(解决 JWT 无法主动销毁);
- 若用 CAS:销毁服务端 TGT 会话;
- 认证中心通知所有子系统销毁本地会话(如通过 MQ 推送登出消息);
- 子系统校验 Token 时,先查黑名单,失效则拒绝访问。
步骤 5、核心防护设计(必做)
- 防伪造:Token 签名加密(如 HS256/RSA),避免篡改;
- 防过期:Refresh Token 机制,Token 过期后自动刷新;
- 防跨域:配置 CORS 白名单,仅允许可信子系统访问;
- 防重放:Token 加入 nonce 随机数,或设置极短过期时间;
- 高可用:认证中心集群部署,Token 黑名单(Redis)做主从同步。
【中等】如何实现微信扫码登录?
第一阶段:准备阶段(生成二维码)
这个阶段的目标是:让 PC 网页拿到一个唯一标识本次登录请求的 UUID,并把它画成二维码。
要点:网页后端生成唯一 ID,Redis 记下它状态,URL 塞进二维码里。
步骤:
- 准备材料:第三方网站需要在微信开放平台提前注册,拿到
AppID和AppSecret。 - 请求二维码:用户点击“微信登录”,PC 端网页向后端请求一个二维码。
- 生成 UUID:第三方服务器生成一个唯一的、临时的 UUID(或称为 state/ticket),并把这个 UUID 的状态(如:未扫描)存到 Redis 中。
- 返回二维码:服务器把包含
AppID、redirect_uri(回调地址)和这个UUID的信息,包装成一个 URL,返回给前端画成二维码。
第二阶段:扫描阶段(扫码确认)
这个阶段的目标是:用户扫码确认,让微信服务器知道“这个 UUID 被这个微信号授权了”。
要点:手机扫码读 UUID,微信确认发授权,绑定 UUID 和 openid。
步骤:
- 扫码:用户打开微信,扫描 PC 上的二维码。微信 APP 解析出二维码中的
UUID。 - 跳转授权:微信 APP 将该
UUID和用户的身份信息(openid)发送给微信服务器,并展示授权页面(“XX 应用请求获取你的昵称、头像”)。 - 用户确认:用户点击“确认登录”。
- 记录绑定:微信服务器记录下
UUID和openid的绑定关系,并通知第三方服务器(通过回调)这个UUID已被授权。
第三阶段:回调阶段(登录成功)
这个阶段的目标是:PC 网页得知授权成功,拿到用户信息,完成登录。
要点:前端一直轮询,发现授权赶紧换,换到 Token 取信息,生成票据登录。
步骤:
- 轮询查状态:在用户扫码的同时,PC 前端一直在轮询调用后端接口,问“我这个
UUID的状态变了吗?”。 - 状态变更:一旦微信服务器通知了第三方服务器“授权成功”,第三方服务器就会把 Redis 中该
UUID的状态更新为“已授权”,并准备好code(授权码)。 - 换取 Token:PC 前端轮询到状态变成“已授权”,后端立即使用
code+AppSecret去微信服务器换取AccessToken。 - 获取用户信息:用
AccessToken调用微信接口,获取用户openid、昵称、头像等信息。 - 登录成功:后端用这些信息生成自己系统的
Session或JWT Token返回给前端,登录完成。
【中等】如何设计一个短链服务?⭐
功能设计
要点:生成、存储、重定向
生成:长链变短码
生成短链的方案:
- 哈希:对长链接进行哈希(如
MD5),得到一个 32 位字符串。 - 自增 ID:用一个中心服务(如 Redis)生成自增数字 ID(如:100001, 100002)。
短链不够短,可以采用转码:把数值转成 62 进制(用光所有数字+大小写字母)。例如 ID 100001 -> 短码 aB3。
存储:写 DB,读 Cache
- 写路径:
长链接 -> 发号器拿 ID -> 转短码 -> 存 MySQL(落盘) - 读路径(关键):
- 第一步:查 Redis(缓存),有就直接用。
- 第二步:Redis 没有,查 MySQL(数据库)。
- 第三步:查到后,回写 Redis,下次就快了。
重定向:301 还是 302?
- 301(永久):
- 特点:浏览器会记住,下次不访问短链服务器了。
- 缺点:没法统计点击次数。
- 302(临时):
- 特点:每次都先找短链服务器,再跳转。
- 优点:可以精确计数(点了几次,谁点的)。
- 结论:推荐 302,为了数据和灵活性。
性能设计
- 缓存:缓存挡住 99%的读请求,不让流量打垮 DB。
- 预发号:短链生成服务不要每次都找发号器,而是一次性生成一批短链(比如 1000 个)放本地内存,用完了再拿。减少对发号器的压力。
- 布隆过滤器:
- 如果有人恶意输入不存在的短码(如
aaaaaa),系统会先去查 Redis 和 DB,造成缓存穿透。 - 布隆过滤器像一个前置的“筛查员”,快速判断这个短码肯定不存在,直接拦截掉,保护后端。
- 如果有人恶意输入不存在的短码(如
分布式设计
【困难】如何设计一个网关?⭐⭐
参考:网关
【困难】如何设计一个 RPC 框架?⭐⭐⭐
设计一个 RPC 框架,可以自下而上梳理一下所需要的能力:
- 通信传输模块:RPC 本质上就是一个远程调用,那肯定就需要通过网络来传输数据。
- 协议模块:传输的数据如何定义,就需要通过协议和序列化方式来确定。此外,为了减少传输数据的大小,可以加入压缩功能。
- 代理模块:为了屏蔽用户的感知,让用户更聚焦于自身业务,需要引入动态代理来托管远程调用。
以上,是一个 RPC 框架的基础能力,使用于 P2P 场景。
但是,如果面对集群模式,以上能力就不够了。同一个服务可能有多个提供者。消费者选择调用哪个提供者?消费者怎么找到提供者的访问地址?请求提供者失败了如何处理?这些都依赖于服务治理的能力。
服务治理,需要很多个模块的能力:服务发现、负载均衡、路由、容错、配置挂历等。
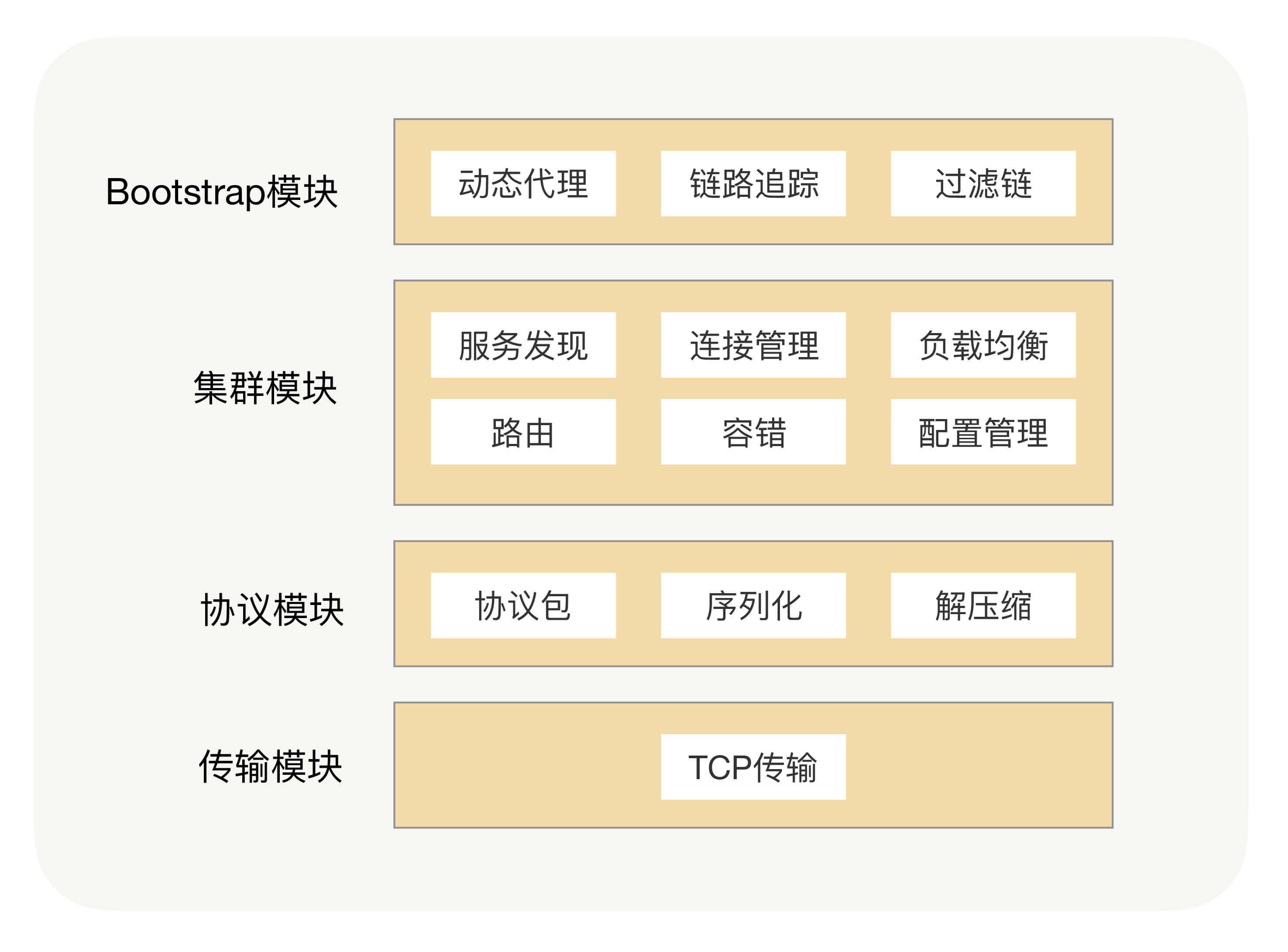
具备了这些能力就万事大吉了吗?RPC 框架很难一开始就面面俱到,但作为基础能力,在实际应用中,难免会有定制化的要求。这就要求 RPC 框架具备良好的扩展性。
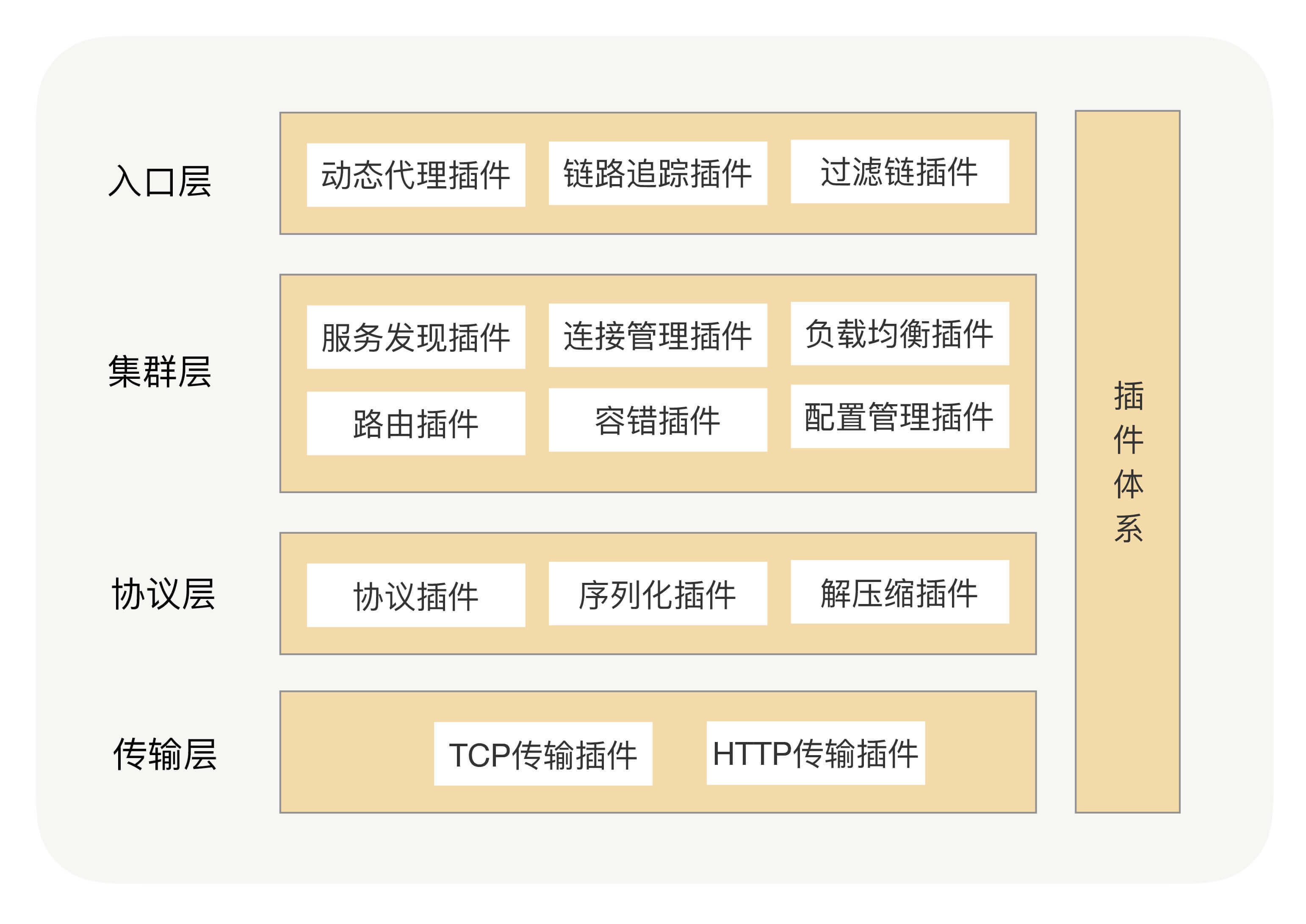
通常来说,框架软件可以通过 SPI 技术来实现微内核+插件架构。根据依赖倒置原则,框架应该先将每个功能点都抽象成接口,并提供默认实现。然后,利用 SPI 机制,可以动态地为某个接口寻找服务实现。
加上了插件功能之后,我们的 RPC 框架就包含了两大核心体系——核心功能体系与插件体系,如下图所示:
【困难】如何设计一个 MQ?⭐⭐⭐
消息模型设计——存什么?
| 模型 | 特点 | 适用场景 | 代表产品 |
|---|---|---|---|
| 点对点(Queue) | 一条消息只被一个消费者消费 | 任务队列 | Kafka、RabbitMQ |
| 发布订阅(Topic) | 一条消息被所有订阅者消费 | 事件广播 | Kafka、RocketMQ |
存储设计——放哪儿?
要点: 顺序写 + 分段存储 + 索引 + 刷盘策略
核心策略:
- 顺序写(性能关键):一般采用日志文件存储,所有消息顺序追加,不分 Topic。
- 分段存储:每个文件固定大小(如 1GB),写满后建新文件
- 索引机制:一般记录消息在日志中的 Offset。
- 刷盘策略
- 同步刷盘:消息落盘才返回成功(安全)
- 异步刷盘:先写内存,批量刷盘(性能)
推拉模型设计——怎么取?
| 模式 | 特点 | 实现方式 |
|---|---|---|
| Push | Broker 主动推,实时性高 | 长连接推送(易压垮消费端) |
| Pull | 消费端主动拉,控制性强 | 定时拉取(延迟可调) |
| Long Polling | 拉不到就等一会儿 | 综合两者优点 |
高可用设计——挂了怎么办?
要点: 主从复制 + 故障转移 + 多副本
- 复制(Kafka/RocketMQ)
- Master: 处理读写
- Slave: 从 Master 同步数据,Master 挂掉后接管
- 多副本(Kafka)
- 每个 Partition 有多个 Replica,Leader 负责读写
- ISR 机制保证数据一致性
可靠性设计——消息不丢不重
要点: ACK 机制 + 重试 + 死信队列
关键机制:
- 生产者 ACK:发送后等待 Broker 确认
- 消费者 ACK:处理完才提交 offset
- 重试队列:消费失败的消息重试 N 次
- 死信队列:超过重试次数,人工介入
性能设计——如何快
| 优化项 | 做法 | 效果 |
|---|---|---|
| 分区 | 分而治之+负载均衡 | 使负载在集群中尽量均衡 |
| 零拷贝 | 使用 mmap 或 sendfile | 减少数据拷贝次数 |
| 页缓存 | 充分利用 OS Page Cache | 读写性能提升 |
| 批处理 | 批量发送、批量刷盘 | TPS 大幅提升 |
| 压缩 | 消息体压缩(gzip/lz4) | 网络带宽节省 |
【困难】如何设计一个分布式锁?⭐⭐⭐
参考:分布式锁
【中等】如何设计一个分布式 ID 发号器?⭐⭐⭐
参考:分布式 ID
【中等】如何设计一个配置中心?⭐
【中等】如何实现链路追踪?⭐⭐
【困难】如何实现分布式事务?⭐⭐⭐
参考:分布式事务
【困难】如何实现流量控制?⭐⭐⭐
参考:流量控制
【中等】服务重启时,如何避免客户端重连引发的流量洪峰?
客户端退避抖动错峰,服务端预热限流渐进,注册中心延迟上下线,无损发布保平稳。
服务重启后,大量客户端同时重连会瞬间产生流量洪峰,可能压垮服务。避免这一问题的核心是错峰连接与服务平滑上线,需要客户端与服务端协同设计。
客户端策略:重连退避与抖动
客户端必须实现智能重连机制,而不是失败后立即重试。
- 指数退避:每次重连失败后,等待时间指数增长(如 1s、2s、4s、8s...),避免集中重试。
- 随机抖动:在退避时间基础上加入随机因子(如 ±50%),防止多个客户端因相同退避策略而同时重连。
- 限制重试次数:设置最大重试次数或最大退避时间,避免无限制重连。
服务端策略:平滑重启与流量控制
服务端需确保自身在重启过程中具备抗冲击能力,并主动引导客户端错峰。
- 优雅启停:服务关闭前先注销注册中心,拒绝新流量,处理完存量请求后再退出。启动时,先完成缓存预热、连接池初始化等,再对外提供服务。
- 延迟注册与渐进式放量:服务启动后,不立即注册到服务发现组件,而是等待一段时间(如 30 秒),确保内部准备就绪。注册后,可通过负载均衡权重逐步放量(如先分配 10% 流量,观察稳定后再提升权重),让服务缓慢承接请求。
- 服务端限流:在网关或入口层配置限流规则(如令牌桶),即使客户端瞬间涌入,也能保护后端服务不被冲垮。
- 客户端主动降级:若服务端返回限流或过载响应,客户端应触发本地降级或返回友好提示,并继续执行重连退避。
架构层面:无损发布与容量规划
- 无损发布平台:借助 K8s 的 Readiness 探针和 PreStop 钩子,确保新实例完全就绪后才接入流量,旧实例在流量切走后优雅退出。
- 容量预估:根据客户端规模预估重启后的瞬时流量,提前扩容实例数量,留足余量。
功能设计
【中等】如何设计一个排行榜功能?⭐⭐
可以使用 Redis 的 zset 数据类型来实现。
【中等】如何设计一个点赞功能?⭐
点赞功能的核心操作是:
- 点赞
- 取消点赞
- 查看点赞列表
本质是一个按时间排序的去重集合。
实现思路
- 缓存抗流量:点赞信息先存储在 Redis。点赞数存储在 String 类型,采用 INCR 原子增减;点赞者维护在 Set 类型。响应时间在 10ms 以内。
- 异步削峰:点赞事件通过 MQ 异步通知,吞吐量可轻松抗住每秒 10 万级消息。
- 批量入库:消费者批量聚合一段时间窗口的点赞信息,如每 5 秒或每 1000 条点赞消息,触发批量入库。——Write Behind 缓存同步更新策略。
【中等】如何实现一个订单超时取消功能?
本质是一个延迟任务调度问题。主流实现方案有:
- 定时任务扫描
- 延迟消息队列:底层采用时间轮实现。
【中等】如何解决订单重复支付情况?
比如用户用微信、支付宝支付,由于支付渠道是第三方系统,数据不互通,因此无法阻止用户付款。
解决核心思路:支付回调幂等性处理。
记忆点:重复支付即退款,幂等记录防重,对账兜底保安全。
第一步、支付回调处理:
- 每次回调先检查订单当前状态。
- 若订单已支付(或已全额支付),则判定为重复支付。
第二步、重复支付处理:
- 记录重复支付流水。
- 立即发起退款(自动调用支付网关退款接口),将多付金额原路退回。
- 退款若失败,发起重试,重试超过一定次数,记录下来,通知运营转为人工处理。
第三步、幂等性:支付流水表建立唯一索引(如订单号+支付渠道+交易号),防止重复记录。
第四步、对账兜底:每日对账系统检查支付流水与订单状态,发现多付但未退款的,自动触发退款。
【中等】如何实现一个分布式单例对象?
要让一个对象在分布式环境下全局唯一,需要满足两个条件:
- 进程内单例:在每台机器上,这个对象只初始化一次(本地单例)。
- 进程间互斥:在整个集群中,只允许一台机器的这个对象真正工作,其他机器的对象处于**“待命”或“禁用”**状态。
实现思路分为两步:
- 用分布式锁控制创建过程,保证同一时刻只有一个进程能创建。
- 把对象存到外部存储,让所有进程都能访问到。
【中等】如何实现接口每分钟调用统计功能?⭐⭐
要点:记、存、看
记(数据埋点)
拦截接口调用(拦截器、过滤器或 AOP),记录每次请求。
- 关键信息:
- 接口名:
/api/user - 时间桶:当前时间的分钟级窗口,例如
2026-02-26 14:00
- 接口名:
- 操作:每一次请求,就给对应的“接口+分钟”计数器加 1。为了不影响正常请求业务,可以丢入一个 MQ 统一异步处理。
存(数据存储)
统计的核心是:写入极其频繁(每次请求都要写),读取相对低频(每分钟/每小时看一次)。
推荐方案:Redis Hash:
- 数据结构:用 Redis 的 Hash。
- Key:统计日期+分钟,如
stats:20260226:1400 - Field:接口名,如
/api/user - Value:调用次数(整数)
- Key:统计日期+分钟,如
- 操作:每次请求执行
HINCRBY stats:20260226:1400 /api/user 1 - 优点:
- 极高性能:内存操作,原子递增。
- 结构清晰:一个 Key 存一分钟的所有接口数据。
- 自动过期:可以给 Key 设置过期时间(比如保留 7 天),自动清理旧数据。
看(数据展示)
从存储中读取数据并展示出来。
- 查询实时分钟数据:直接
HGETALL stats:20260226:1400,拿到这一分钟所有接口的计数。 - 查询历史趋势:遍历多个分钟 Key,聚合出接口的调用趋势。
- 可视化:可以对接 Grafana,或自己写一个简单的接口返回 JSON 数据供前端图表展示。
要点:“Redis Hash 来计数,每分钟一个 Key,Field 是接口,Value 是次数。”
【中等】如何设计一个购物车功能?⭐⭐
要点:购物车设计 = Redis 存储 + 实时库存价格校验 + 合并结算 + 多端同步,核心是数据一致性和用户体验。
数据存储
| 维度 | 关注点 | 解决方案 |
|---|---|---|
| 存储选型 | 高性能+持久化平衡 | Redis(主)+ MySQL(备/历史) |
| 数据结构 | 灵活查询 | Hash 结构:cart:user:{id} → field=skuId, value=商品详情 |
| 过期策略 | 僵尸数据清理 | 7 天过期 + 定期清理未登录购物车 |
核心功能
| 功能 | 难点 | 解决 |
|---|---|---|
| 添加商品 | 重复 SKU 合并 | 存在则累加数量,不超过限购 |
| 数量更新 | 库存边界 | 实时校验库存上限、下限 1 |
| 实时价格 | 价格变动 | 查询时从商品服务拉取最新价 |
| 选中结算 | 批量操作 | 维护selected状态位,全选/反选 |
库存处理
- 预占库存:结算时 Redis 原子扣减(Lua 脚本)
- 释放库存:超时未支付/取消订单 → 回补
- 实时校验:添加/更新时查真实库存
多端同步
- 未登录 → LocalStorage
- 登录时 → 合并 LocalStorage 到 Redis
- 多端 → 同一 Redis,实时同步
异常场景
| 场景 | 问题 | 处理 |
|---|---|---|
| 库存不足 | 下单失败 | 标记失效,提示用户 |
| 价格变动 | 金额不符 | 重新计算,弹窗确认 |
| 商品下架 | 无法购买 | 自动移除,提示原因 |
【中等】如何设计一个抢红包功能?
两种红包
| 类型 | 算法 | 要点 |
|---|---|---|
| 普通红包 | 总金额 / 个数 | 每人固定金额,简单。 |
| 随机红包 | 二倍均值法(实时) 或 线段分割法(预生成) | 总额固定,每人 ≥ 0.01 元,随机公平。 |
随机红包核心算法
- 二倍均值法(实时计算)
- 公式:当前金额 = 随机 [0.01, 剩余金额/剩余人数 × 2 - 0.01]
- 特点:实时计算,期望公平,但最后一人金额波动大。
- 记忆点:每次随机上限是剩余均值两倍,保证公平不超总。
- 线段分割法(预生成)
- 原理:把总金额(分)看作线段,随机切 N-1 刀,按切点分段作为金额。
- 特点:提前生成金额列表存入队列,抢时顺序取,每人概率完全相同。
- 记忆点:预切线段存队列,顺序取出无争议。
技术关键点
- 金额单位:用 “分”(整数),避免浮点误差。
- 并发控制:Redis
LPOP原子弹出预先生成的金额列表,或用 Lua 脚本保证一致性。 - 持久化:红包状态(已抢列表、剩余金额)需持久化到 DB/Redis,重启后恢复。
- 过期退回:未抢完的红包超时后,根据已抢记录计算剩余金额,原路退回。
扩展问题
- 最后一人金额波动大?
- 是的,二倍均值法最后一人拿剩余,方差较大;线段分割法可消除波动。
- 0.1 元发 10 人?
- 不够每人 1 分,发红包时前置校验:总金额 ≥ 人数 × 最小单位(1 分)。
- 系统重启怎么办?
- 持久化存储红包状态,重启后从存储恢复继续服务;预生成方案天然支持断点续抢。
【中等】如何设计一个取消订单功能?⭐
取消订单基本流程
记忆点:“校验、改状态、释放库存、退券、退款。”
| 操作 | 说明 |
|---|---|
| 校验状态 | 只有待支付/已超时订单才可取消,已支付/已发货等不能取消 |
| 更新状态 | 将订单状态改为“已取消” |
| 释放库存 | 恢复商品库存(若锁定过库存) |
| 退还优惠券/积分 | 若有使用的优惠券需退回 |
| 触发退款 | 若已支付(仅当允许取消已支付订单时),走退款流程 |
并发冲突场景:取消与支付同时发生
- 用户点击“取消”的同时,支付回调也到达。
- 若不加控制,可能出现:
- 订单被取消后却支付成功(资金损失)
- 订单支付成功却被取消(体验问题)
核心目标:保证最终一致性,避免资损。
解决方案
方案一、基于数据库行锁 + 状态机(推荐)
- 原理:在更新订单状态时,使用数据库行锁或乐观锁,保证状态变更的原子性。
- 实现:
UPDATE orders SET status = 'CANCELED' WHERE id = ? AND status = 'PENDING'UPDATE orders SET status = 'PAID' WHERE id = ? AND status = 'PENDING'- 两条更新语句同时执行时,只有一条能成功(因为
status = 'PENDING'条件)。
- 优点:简单可靠,利用数据库 ACID。
- 缺点:依赖数据库,但订单系统通常足够。
方案二、分布式锁
- 原理:对订单 ID 加锁(如 Redis 锁),取消和支付先争抢锁,获得锁的一方执行,另一方等待或重试。
- 适用:跨多个服务或数据库,需要强一致性。
方案三、最终一致性 + 对账补偿
- 原理:允许短暂不一致,通过后续对账或消息补偿修复。
- 流程:
- 取消和支付都正常执行,但记录流水。
- 后台定时任务检查“已取消但已支付”的异常订单,自动退款。
- 优点:高并发下性能好。
- 缺点:需补偿逻辑,可能存在资损窗口。
最佳实践(推荐方案)
业务优化
在页面上可以限时订单取消计时为 10 分钟,但实际后端是延迟 11 分钟取消订单。这样就可以避免用户在取消订单限时最后一刻下定决心付款的情况。
数据库行锁/乐观锁 + 状态机 + 幂等 + 补偿
- 取消和支付都先检查订单状态(SELECT ... FOR UPDATE 或使用乐观锁)。
- 更新时带上原状态条件(
status = 'PENDING')。 - 若更新失败(影响行数为 0),说明状态已变更,根据新状态做不同处理:
- 若已被支付,取消操作失败,提示用户“订单已支付,不能取消”。
- 若已被取消,支付回调需拒绝或触发退款。
- 使用幂等设计:支付回调需幂等,避免重复处理。
- 兜底:对账系统定期扫描异常订单,自动修复(如已取消却支付成功则退款)。
【中等】如何避免用户重复下单(多次下单为支持,占用库存)?⭐
核心思想:同一请求无论提交多少次,只创建一笔订单,只扣一次库存(幂等性设计)。
前端防重
按钮置灰 + Loading:防止用户双击或连续点击。
后端幂等
- 幂等键:客户端生成唯一标识(如 UUID),在创建订单时传入。
- 处理流程:
- 后端先查 Redis 该幂等键是否存在 → 存在则直接返回已创建订单,不再扣库存。
- 不存在则加分布式锁,执行业务(创建订单、扣库存),完成后存入 Redis(带过期时间)。
数据库兜底
- 唯一约束:订单表为幂等键字段建立唯一索引,保证重复插入失败。
库存保护要点
- 库存扣减必须和订单创建在同一个事务中,保证原子性。
- 若幂等键已存在,直接返回已有订单,不再扣减库存。
【困难】如何设计数据同步方案(同步到数仓)?
数据同步 = Canal 采集 Binlog + MQ 保序 + Flink 清洗 + 每日对账,核心是数据不丢不重、顺序一致、延迟可控。
总体架构
订单库(MySQL) → 变更捕获 → 消息队列 → 数据清洗 → 数仓(Hive/ClickHouse)
↑ ↑
业务无侵入 可重试、保序核心方案选型
| 方案 | 原理 | 准确率 | 性能 | 复杂度 | 推荐 |
|---|---|---|---|---|---|
| Canal(Binlog) | 模拟 MySQL 从库解析 binlog | 最高 | 高 | 中 | ⭐️ 首选 |
| MQ 双写 | 业务代码同步发 MQ | 中 | 低 | 低 | 不推荐 |
| DataX 离线抽取 | 定时全量/增量抽取 | 高 | 低(T+1) | 低 | 离线场景 |
| Flink CDC | 实时流计算 | 高 | 高 | 高 | 实时数仓 |
关键机制
- 数据一致性保障
- 断点续传:记录 binlog 位点(position)
- 去重:MQ 消息幂等消费(订单 ID+版本号)
- 补偿:每日 T+1 对账,不一致重新同步
- 事务边界:binlog 事务原子性(同一事务一起发送)
- 顺序性保障:同一个订单的变更必须顺序处理
- 方案 1:MQ 分区键 = order_id(同订单进同一分区)
- 方案 2:Flink keyBy(order_id) 单线程处理
- 性能优化
- 批量发送:Canal 每 500ms/1000 条发送一次
- 压缩传输:启用 MQ 消息压缩(Gzip/Snappy)
- 目标优化:ClickHouse 批量写入(每批 1 万条)
- 分流处理:订单主表+明细表分开同步
binlog 同步流程
订单库 → Canal → Kafka/RocketMQ → Flink/Spark → 数仓
↑ ↑ ↑ ↑
业务写 伪装从库 持久化消息 清洗、维表关联Canal 配置要点
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.filter.regex=order_db.order_table # 监听表
canal.mq.topic=order-binlog
canal.mq.partitionsHash=order_id # 保序数据质量保障
实时监控
- 延迟监控:当前时间 - 最后一条同步时间 < 5 分钟
- 数量监控:源库增量 ≈ 数仓增量(允许误差)
- 异常监控:解析失败率 < 0.1%
对账机制
每日凌晨执行:
SELECT COUNT(*) FROM order_db.order_table
MINUS
SELECT COUNT(*) FROM dwd_order_table WHERE dt = 昨日不一致则触发离线重新同步
脏数据处理
- 格式错误 → 发到死信队列(人工介入)
- 维表不存在 → 先存待补表,维表到位后更新
容灾
- 主链路:Canal → Kafka(主集群)
- 备链路:DataX 每日全量(兜底)
- Kafka 故障:消息积压,Canal 本地文件缓存(需配置)
- 数仓故障:消息持久化,恢复后重放
【中等】如何实现数据的不停服迁移?
核心思想
双写 + 数据同步 + 灰度切换
让新旧两套存储同时提供服务,逐步把流量切到新库,全程业务无感知。
第一阶段、准备与双写
- 新库上线,应用修改代码:所有写操作同时写入旧库和新库(双写)。
- 双写需保证最终一致性,可异步或同步(视业务容忍度)。
- 读操作仍从旧库读取,确保对业务无影响。
第二阶段、历史数据迁移
- 将旧库中的全量历史数据批量迁移到新库。
- 迁移过程中,增量数据仍在双写,需保证迁移与增量不冲突。
- 常见做法:记录迁移开始的时间戳或位点,迁移完成后,再补录期间产生的增量。
- 使用工具(如 DataX、Kettle)或自研脚本,分批迁移,避免影响线上。
第三阶段、灰度读切换
- 待历史数据迁移完成且双写稳定后,开始灰度切读流量。
- 逐步将读请求从旧库切到新库,比如 1%、10%、50%、100%。
- 每个灰度步骤观察业务指标(响应时间、错误率、数据一致性)。
- 记忆点:读流量灰度切,逐步放量稳观察。
第四阶段、双写降级与最终切换
- 当读流量全部切到新库且稳定运行后,可考虑将双写降级为只写新库。
- 此时旧库可作为备份,观察一段时间无异常后,正式下线旧库。
- 保留旧库一段时间(如一周),以备紧急回滚。
- 记忆点:双写降级只写新,观察备份再下线。
【困难】如何快速找到附近距离用户最近的 N 家商户?
方案一、GeoHash + MySQL(通用、易实现)
- 原理:将二维经纬度编码为一维字符串,前缀相同的区域相邻。
- 步骤:
- 商户入库时,根据经纬度计算 GeoHash 值(如 6-8 位),存入数据库并建索引。
- 查询时,计算用户位置的 GeoHash,取前缀匹配(如前 6 位),查询该区域及周围 8 个邻域的商户。
- 对查询结果计算精确距离,排序取前 N 个。
- 优点:实现简单,支持分库分表,精度可控。
- 缺点:边界问题需扩展邻域,精确距离计算需回表。
- 记忆点:GeoHash 编经纬,前缀匹配找附近,邻域扩展防边界,精确计算再排序。
方案二、Redis GEO(高性能、简单)
- 原理:Redis 3.2+ 内置 GEO 类型,基于有序集合(ZSet)存储经纬度,提供地理距离计算。
- 步骤:
- 用
GEOADD将商户 ID 和经纬度加入 Redis。 - 用
GEORADIUS或GEORADIUSBYMEMBER查询用户附近 N 个商户,直接返回距离排序结果。
- 用
- 优点:性能极高(内存操作),API 简单,支持距离排序和返回距离。
- 缺点:数据需全量驻留内存,容量受限于内存;适合商户数量可容纳的场景。
- 记忆点:Redis GEO 内存跑,GEORADIUS 命令好,性能极简成本高。
方案三、Elasticsearch Geo Distance(搜索型、可扩展)
- 原理:ES 内置地理点类型和地理距离查询,利用倒排索引和空间索引。
- 步骤:
- 定义字段类型为
geo_point,索引商户经纬度。 - 使用
geo_distance查询,按距离排序,取前 N 个。
- 定义字段类型为
- 优点:支持海量数据,可与全文搜索结合,分布式天然扩展。
- 缺点:需部署 ES 集群,运维成本较高。
- 记忆点:ES 地理点,geo_distance 搜周边,海量数据可扩展。
方案四、空间索引(PostGIS / MySQL Spatial)(数据库原生)
- 原理:关系数据库的空间扩展,使用 R-Tree 索引加速几何计算。
- 步骤:
- 创建
GEOMETRY列存储点坐标,建立空间索引。 - 使用
ST_Distance和ST_Within等函数查询最近点。
- 创建
- 优点:数据库原生支持,无需额外组件,数据一致性好。
- 缺点:某些数据库实现(如 MySQL)的空间索引性能可能不如 GeoHash 或 Redis;PostGIS 性能优异但需 PostgreSQL。
- 记忆点:空间索引 R-Tree,ST 函数算距离,PostGIS 更专业。
方案选型建议
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 商户数百万以内,并发高 | Redis GEO | 简单、快、内存可控 |
| 商户数千万以上,需持久化 | GeoHash + MySQL / MongoDB | 成本低,可水平扩展 |
| 需要复杂查询(文本+地理) | Elasticsearch | 功能全面,扩展性强 |
| 已有 PostgreSQL | PostGIS | 原生支持,性能优异 |
优化技巧
- 多级索引:先用行政区划(城市、区县)粗筛,再用 GeoHash 细查。
- 缓存热点:热门区域的查询结果可缓存,减少重复计算。
- 动态网格:根据商户密度动态调整网格大小,平衡精度和性能。
- 异步更新:商户位置变化不频繁,可异步更新索引。
【中等】调用第三方接口应注意哪些问题?⭐⭐
要点
- 预防性设计:超时、重试、熔断、限流。
- 安全性:加密、认证、凭证管理、脱敏。
- 一致性:幂等、补偿、版本兼容。
- 资源隔离:线程池、连接池、信号量。
- 可观测性:日志、监控、链路追踪。
网络与超时控制
- 连接超时:设置合理的建立连接超时(如 3-5 秒),避免长时间等待。
- 读取超时:设置接口响应数据读取超时(如 10 秒),防止对方服务慢导致线程挂起。
- DNS 解析超时:确保 DNS 查询不成为瓶颈,可考虑使用备用 DNS 或 IP 直连。
异常处理与重试
- 区分异常类型:网络抖动(可重试) vs 业务错误(不可重试,需人工介入)。
- 重试策略:指数退避 + 最大重试次数(如 3 次),避免加重对方负载。
- 幂等性保证:重试时需确保接口支持幂等,否则需业务层去重。
接口限流与熔断
- 限流:根据对方接口配额或自身系统能力,进行本地限流(如 Guava RateLimiter)或分布式限流。
- 熔断:引入熔断机制(如 Sentinel、Hystrix),当错误率达到阈值时快速失败,防止雪崩。
- 降级:定义降级逻辑(如返回缓存数据或默认值),保障核心业务。
数据安全与认证
- 传输加密:使用 HTTPS 确保数据传输安全,防止中间人攻击。
- 身份认证:妥善管理 API Key、Token 等凭证,避免硬编码(使用配置中心或密钥管理服务)。
- 敏感信息:请求/响应中若包含敏感数据,需进行脱敏或加密处理。
幂等性与数据一致性
- 请求幂等:对于可能重复提交的场景(如支付通知),需通过业务唯一键去重。
- 最终一致性:若第三方接口响应延迟或失败,需设计补偿机制(如定时对账、状态同步)。
接口版本管理与兼容性
- 版本控制:明确接口版本(如 URL 路径包含 v1),避免无通知升级导致兼容问题。
- 变更通知:关注第三方接口变更公告,提前适配。
- 灰度验证:新版本接口上线前,先在小流量验证。
资源隔离与线程池管理
- 线程池隔离:为第三方调用分配独立的线程池,避免占用核心业务线程资源。
- 信号量隔离:对于非阻塞调用,可使用信号量控制并发数。
- 连接池管理:合理配置 HTTP 连接池大小、空闲连接回收策略,避免资源泄漏。
安全设计
【中等】如何设计一个接口签名验证机制?
签名(防篡改)
要点:参数排序 + 密钥 = 签名,两边算法一致就安全。
- 做法:客户端将所有请求参数(含时间戳、随机数)按字母排序后拼接,末尾附上双方约定的密钥(Secret),然后计算哈希(如 HMAC-SHA256)得到签名,放在请求头中。
- 服务端校验:用同样的规则重新计算签名,比对客户端签名。一致则参数未被篡改。
时间戳(防过期)
要点:时间戳差值超窗口,请求直接算过期。
- 做法:请求参数中携带客户端生成请求的 Unix 时间戳(timestamp)。
- 服务端校验:用当前时间减去
timestamp,如果差值超过允许的时间窗口(如 5 分钟),则请求过期,拒绝。
随机数(防重放)
要点:随机数存 Redis,窗口期内只一次。
- 做法:请求参数中携带客户端生成的唯一随机字符串(nonce),如 UUID。
- 服务端校验:在通过时间戳校验后,检查 Redis(或其他缓存)中是否已存在该
nonce。- 如果存在 → 重复请求,拒绝。
- 如果不存在 → 存入 Redis,设置过期时间等于时间窗口(5 分钟)。
【中等】如何实现敏感词过滤功能?
构建敏感词库 + 快速多模式匹配算法,在文本中检测并替换敏感词。
业界常用 Trie + DFA 实现敏感词过滤功能(其实就是 AC 自动机的原理):Trie 构建词库,DFA 提供状态转移,一次扫描文本即可匹配所有敏感词。
实现步骤
- 构建 Trie 树:所有敏感词插入 Trie 树。
- 构建失败指针:BFS 遍历 Trie 树,为每个节点设置失败指针,将 Trie 转化为 DFA(确定有穷自动机)。
- 扫描:文本逐字符在自动机上转移,到达敏感词结尾即标记替换。
【中等】接口中的敏感数据(如身份证号、手机号)应该如何保护?
核心原则:传输通道加密 + 数据内容加密 + 存储加密 + 密钥安全。
传输加密:双重保险
基础保障:HTTPS(TLS)
要点:HTTPS 是底线,通道不裸奔。
作用:加密整个传输通道,防止中间人窃听、篡改。
要求:全线启用 HTTPS,禁用弱加密套件。
进阶保障:应用层加密(字段级)
- 要点:公钥加密传,私钥解密看,字段级防护更保险。
- 场景:防止内网嗅探、HTTPS 卸载后的风险,或部分参数需要在 URL/日志中可见但需保护内容。
- 做法:
- 客户端使用服务器公钥(RSA)对敏感字段(如身份证号)进行加密。
- 服务端使用私钥解密得到明文。
存储加密:核心防线
算法选择:对称加密(AES-256)
- 要点:AES 加密存密文,IV 随机不重复。
- 原因:对称加密性能好,适合大量数据。
- 做法:
- 存储前,用 AES 密钥对敏感字段加密,得到密文存入数据库。
- 读取时,用相同密钥解密。
- 注意:
- 密钥绝不能硬编码在代码里。
- **初始化向量(IV)**应随机生成并与密文一起存储。
密钥管理:KMS/HSM
- 要点:密钥托管 KMS,轮换审计不放松。
- 要求:密钥应定期轮换,使用专门的密钥管理服务(如 AWS KMS、阿里云 KMS)或硬件安全模块(HSM)。
附加保护措施
- 脱敏显示:展示必须脱敏,日志同样处理——在界面、日志中只显示部分内容(如
138****1234)。 - 最小化收集:能不存就不存,能匿名就匿名——只收集业务必需的数据,不存无关敏感信息。
- 访问审计:访问留痕迹,审计可追溯——记录谁、何时、为什么访问了敏感数据。
【困难】加密后的数据怎么支持模糊搜索?
方案一:分词加密(最常用)
要点:数据分词存密文,搜索分词去匹配,索引加速效果好。
- 原理:
- 对原始数据进行分词(如手机号
13812345678拆成138,1381,13812... 或固定长度组合)。 - 对每个分词进行确定性加密(每次加密结果相同,如 AES 确定模式)。
- 将分词密文存入辅助字段,建立索引。
- 搜索时,对搜索词做相同分词和加密,用加密后的分词去索引中匹配。
- 对原始数据进行分词(如手机号
- 优点:
- 支持模糊搜索:通过匹配部分词实现模糊效果。
- 性能较好:使用索引精确匹配。
- 缺点:
- 安全性略降:确定性加密和分词暴露了部分信息(攻击者可统计频率)。
- 存储增加:需额外字段。
方案二:数据库解密搜索(迫不得已)
要点:解密再查询,简单但巨慢,慎用。
- 原理:
- 在数据库层面使用可解密的函数(如 MySQL 的
AES_DECRYPT)。 SELECT * FROM user WHERE AES_DECRYPT(encrypted_phone, key) LIKE '%138%'。
- 在数据库层面使用可解密的函数(如 MySQL 的
- 优点:
- 实现简单,不改变现有逻辑。
- 缺点:
- 性能极差:无法使用索引,全表扫描解密。
- 密钥暴露风险:密钥需传递给数据库,易泄露。
方案三:外置搜索引擎(专业方案)
要点:专业的事交给 ES,加密索引两不误。
- 原理:
- 将明文数据发送给专业搜索引擎(如 Elasticsearch),利用其内置的加密功能或插件(如 ES 的 Encrypted 字段)。
- ES 对数据加密索引,搜索时同样加密查询词进行匹配。
- 优点:
- 功能强大:支持复杂搜索、分词、排序。
- 安全可控:专业的加密方案。
- 缺点:
- 引入新组件:增加架构复杂度。
- 成本较高。
【困难】如何防止接口被恶意刷量?
第一道防线:认(身份识别)
- 验证码:图形、滑动、点选等,区分人和机器。
- 设备指纹:通过 JS 采集设备信息,识别同一设备的恶意行为。
- 登录态:要求用户登录,增加匿名刷量的门槛。
- 要点:“是人是机,先验明正身。”
第二道防线:控(访问控制)
- IP 黑白名单:直接封禁已知恶意 IP。
- 用户黑白名单:对恶意账号进行限制或封禁。
- 地域限制:仅允许业务覆盖的区域访问。
- 要点:“黑名单直接封,白名单放心过。”
第三道防线:限(流量限制)—— 经典限流
- 接口限流:按 IP、用户、设备维度,限制单位时间内的访问次数(如每秒 5 次)。
- 资源限流:限制单一用户对核心资源(如短信验证码)的获取频率(如 1 分钟 1 条)。
- 并发限流:限制同一用户的并发连接数。
- 要点:“频率超限就拒绝,令牌桶和漏桶齐上阵。”
第四道防线:罚(惩罚与追溯)
- 队列削峰:请求先入消息队列,后端平滑处理,防止瞬间流量打垮系统。
- 日志告警:记录异常行为,触发告警,人工介入。
- 临时封禁:对异常 IP 或用户实施临时封禁(如封禁 24 小时)。
- 要点:“日志留痕,告警通知,封禁伺候。”
【中等】如何实现一个滑动验证码功能?如何防止被机器识别破解?
实现原理
- 生成(服务器)
- 动作:随机生成一张背景图和一张滑块图,并记录缺口的目标位置(x 坐标)。
- 关键:缺口的形状、位置每次都变,防止模板匹配。
- 交互(前端)
- 动作:用户拖动滑块拼合缺口。
- 关键:前端不仅要记录最终位置,还要记录整个拖动过程的轨迹(鼠标坐标、速度、时间戳)。
- 双重校验(服务器)
- 位置校验:最终坐标是否接近目标位置(允许微小误差)。
- 行为校验:轨迹是否符合真人操作特征(加速度、停顿、抖动)。
四层防护防破解
机器破解的核心难点在于:不仅要算对位置,还要演得像人。
缺口识别对抗(防模板匹配)
- 破解手段:机器用 OpenCV 模板匹配找缺口。
- 防护手段:
- 背景干扰:增加复杂背景、干扰线、噪点 。
- 缺口变形:滑块形状随机旋转、缩放 。
- 伪缺口:增加多个类似缺口迷惑机器 。
- 要点:“缺口形状天天变,模板匹配不好辨。”
轨迹校验对抗(防机械滑动)
- 破解手段:机器用匀速直线滑动。
- 防护手段:
- 加速度检测:真人滑动是先快后慢(匀加速→匀减速),机器常是匀速 。
- 停顿检测:真人会在中途停顿(观察位置),机器常一气呵成 。
- 抖动检测:真人手眼配合有微小抖动(±2 像素),机器轨迹过于平滑 。
- 要点:“匀速直线是机器,有快有慢才像人。”
行为上下文对抗(防脚本模拟)
- 破解手段:机器直接调用接口模拟轨迹。
- 防护手段:
- 初始位置随机:真人点击滑块不总在正中心,而是在滑块区域内随机 。
- 滑动前停顿:真人会先观察(停顿 0.1-0.5 秒),机器常立即滑动 。
- 设备指纹:校验浏览器指纹、Canvas 指纹,识别是否为真实浏览器 。
- 要点:“点击位置不固定,观察片刻再行动。”
动态策略对抗(防持续攻击)
- 破解手段:机器不断换 IP、换设备重试。
- 防护手段:
- 频次限制:同一 IP/设备短时内失败多次,直接拦截 。
- 智能切换:检测到疑似攻击,自动升级为点选验证码或短信验证 。
- 要点:“发现异常就升级,让你破解白费力。”
【中等】短信验证码如何防止被恶意轰炸?
| 层次 | 手段 | 目标 |
|---|---|---|
| 限 | 频次、IP、设备限制 | 控制速度,不让刷 |
| 验 | 滑动验证码 | 区分人机,拦住脚本 |
| 控 | 总量封顶、前置校验 | 不合逻辑就不发 |
| 罚 | 临时封禁、递增等待 | 增加攻击成本 |
| 断 | 监控告警、手动熔断 | 保住预算,快速止损 |
限(频率控制)
- 发送频次限制:
- 同手机号:60 秒内只能发 1 次,24 小时内不超过 5-10 次。
- 同 IP:1 分钟内同一 IP 不能发超过 3 条。
- 同设备:设备指纹维度限制。
- 要点:“手机号限频,IP 也限频,双重保险。”
验(前置验证)
- 发送前必须通过验证码:点击“获取验证码”前,先完成滑动验证码或点选验证。
- 作用:拦截 99%的自动化脚本攻击。
- 要点:“想发短信?先证明你是人。”
控(业务逻辑控制)
- 每日总量封顶:单个手机号每天最多收 10 条,达到上限当天不再发送。
- 发送前校验:如注册场景,先检查手机号是否已注册,已注册则提示“该手机已注册”,不发送验证码。
- 要点:“到量就停,不合逻辑也不发。”
罚(异常惩罚)
- 临时封禁:检测到异常高频发送(如 1 分钟请求 10 次),对该 IP 或手机号临时封禁 30 分钟。
- 增加等待时间:第二次发送等待 60 秒,第三次等待 120 秒,指数级递增。
- 要点:“越界就罚,越罚越等。”
断(降级熔断)
- 监控告警:监控短信发送成功率、失败率、总条数。发现异常激增,触发告警。
- 手动熔断:紧急情况下,运维可一键关闭短信发送功能,或切换备用通道。
- 要点:“异常激增即告警,一键熔断保成本。”
【中等】如何在涉及金钱的场景,避免因人为配置失误(如折扣粒度配错、优惠金额配错),导致资金损失?
产品维度防呆设计:审、看、控
审(多重审核)
要点:多重审核层层过,配置变更需签字。
- 多重审核:敏感配置(如折扣、满减)必须经过运营→主管→财务多重审核,才能生效。
- 配置即代码:将复杂配置转化为结构化表单,审批人能看到前后差异对比,避免肉眼漏看。
看(预览和评估)
要点:预览效果先看看,影响范围算清楚。
- 配置预览:在配置页提供实时预览,展示生效后的效果(如“满 100 减 50”后的订单实付金额)。
- 影响范围评估:自动计算配置会影响多少商品、多少用户、预估成本,让运营心里有数。
控(权限与复核)
要点:权限分离保安全,二次确认防手滑。
- 权限分离:配置权限与审批权限分离,运营只能提交,不能直接发布。
- 敏感操作复核:关键配置(如全场五折)需输入支付密码或短信验证码二次确认。
技术维度防御性编程:校验、版本、流控、观测
数据校验
- 边界校验:折扣率必须介于 0 到 1 之间(如 0.5 表示五折),金额必须为正整数。
- 冲突校验:
- 优惠金额 ≤ 订单金额;
- 如果同时存在多种优惠,是否允许叠加;
- 叠加优惠后实付 ≥ 0;
- 不出现负金额。
- 单元测试覆盖:核心优惠计算逻辑要有自动化测试,防止代码逻辑与配置冲突。
版本与回滚
- 配置版本管理:每次配置变更都生成新版本,支持一键回滚到上一稳定版本。
- 灰度发布:先对 1%用户生效,观察无异常后再全量。
限流与熔断
- 限流保护:如果错误配置导致瞬间大量请求(如 0 元购),限流能保护下游订单系统不被冲垮。
- 熔断机制:监控到错误率或收入异常,自动熔断优惠活动。
监控与告警
- 实时监控:监控核心指标(如客单价、优惠总额、GMV),设置上下限阈值。
- 异常告警:一旦指标偏离超过 20%,立即通过短信、电话通知负责人。
风控
- 限制优惠单日次数:限制单用户单日最多享受优惠次数,或采用风控识别异常用户,防止薅羊毛。
【中等】如何保证 JWT 安全?
保证 JWT 安全需要从签名、传输、存储、生命周期、数据内容等多个维度进行防护。
要点:加密签名防篡改,HTTPS 防截获,短生命周期减损失,安全存储避 XSS,黑名单与刷新机制保可控。
- 使用强签名算法并保护密钥:选择 RS256(非对称)或 HS256(对称),避免使用已弃用的算法(如 none)。私钥或对称密钥需妥善保管,定期轮换。
- 设置合理的过期时间:JWT 应设置较短的过期时间(如 15 分钟),配合 Refresh Token 机制,降低被盗用后的风险窗口。
- 强制 HTTPS 传输:防止中间人截获令牌。所有涉及 JWT 的请求必须通过 TLS 加密通道。
- 避免在 JWT 中存放敏感数据:Payload 是 Base64 编码,可被轻松解码,切勿存放密码、身份证号等明文敏感信息。如需存储,应使用 JWE(JSON Web Encryption)进行加密。
- 选择安全的存储位置:Web 端推荐将 JWT 存储在 HttpOnly Cookie 中,并设置 Secure 和 SameSite 属性,防止 XSS 和 CSRF 攻击。移动端可存储在安全存储区(如 Keychain)。
- 服务端维护令牌黑名单:对于登出、修改密码等场景,需将对应的 JWT 加入黑名单(如 Redis 缓存),直至过期,防止继续使用。
- 防重放攻击:可在 JWT 中加入 jti(唯一标识)并缓存,在一段时间内拒绝相同 jti 的请求,或结合时间戳和 nonce 机制。
- 限制 JWT 大小:避免在令牌中存放过多信息,以免影响网络传输性能。常用的做法是只存必要字段(如用户 ID、角色),其他信息通过缓存获取。
- 双 Token(Access Token + Refresh Token):Refresh Token 应长期有效但仅用于换取新的 Access Token,且需安全存储。每次刷新时可更换 Refresh Token 值,降低被盗风险。
- 监控与告警:记录异常 JWT 使用行为(如异地登录、短时间内多次刷新),及时触发安全策略。
【中等】如何防止 CDN 链接被盗刷?
要点:签名防伪造,时间戳限时,IP 频次控流量,私有 Bucket 加监控,多层防护断盗刷。
基础访问控制
- Referer 防盗链:检查 HTTP 请求头中的 Referer,仅允许特定来源访问。易被伪造,作为基础防护。
- IP 黑白名单:对已知恶意 IP 或区域直接拦截,或仅允许可信 IP 访问。
- User-Agent 限制:屏蔽非标准或恶意 UA,如空 UA、爬虫 UA。
签名鉴权机制
- URL 时间戳签名:在 URL 中嵌入过期时间和签名(如 MD5),服务端验证签名和时效性,过期或篡改的请求直接拒绝。此为 CDN 厂商通用方法(如阿里云 URL 鉴权)。
- 动态令牌:每次请求携带临时 token,服务端验证通过后才返回内容。适用于高安全场景。
频次与用量控制
- 单 IP 频次限制:对同一 IP 的访问频率进行限流,超出阈值则返回 429 或封禁。
- 并发连接限制:限制同一 IP 的并发连接数,防止多线程下载。
- 流量封顶:在 CDN 控制台设置带宽峰值或流量上限,达到阈值自动熔断,避免巨额账单。
- 区域访问控制:若业务仅面向特定地区,可限制其他国家/地区的 IP 访问。
【困难】有哪些常见的安全漏洞?什么原因导致的,有什么样的危害,如何应对?⭐⭐⭐
XSS(跨站脚本)
- 攻:未对输出到 HTML 的内容进行转义,导致恶意脚本在用户浏览器执行。
- 危:窃取 Cookie、会话劫持、钓鱼攻击。
- 防:
- 对特殊字符进行 HTML 转义
- 将 Cookie 标记为 HttpOnly
CSRF(跨站请求伪造)
- 攻:未验证请求来源,攻击者诱导用户在已登录状态下执行非预期操作。
- 危:修改密码、转账、发表内容等。
- 防:
- 使用 CSRF Token(表单或请求头)
- 设置 SameSite Cookie 属性
- 关键操作多重验证
SSRF(服务端请求伪造)
- 攻:服务端接收用户提供的 URL 并发起请求,未对目标进行限制。
- 危:访问内网资源、端口扫描、绕过防火墙。
- 防:
- 对请求目标进行白名单验证
- 禁用不必要的协议
- 限制返回信息
- 使用统一网络出口并设置访问控制
DDoS(分布式拒绝服务攻击)
- 攻:攻击者向目标发送海量请求
- 危:服务中断
- 防:
- 事前高防+限流
- 事中清洗+扩容
- 事后溯源+加固
文件上传漏洞
- 攻:未对上传文件类型、内容、大小进行严格校验,允许上传可执行脚本。
- 危:上传 WebShell 控制服务器、存储恶意文件传播。
- 防:
- 校验文件类型、内容、大小
- 重命名文件并存储于非 Web 可访问目录
- 使用病毒扫描
越权访问
- 攻:未对用户身份和权限进行验证,或验证不严格。
- 危:水平越权访问他人数据,垂直越权执行管理员功能。
- 防:
- 每个接口进行权限校验(RBAC)
- 基于用户 ID 和资源归属进行二次验证
- 使用安全的会话管理
敏感信息泄露
- 攻:硬编码密钥、错误堆栈暴露、传输未加密、日志中打印敏感数据。
- 危:账号密码泄露、密钥暴露导致系统被控。
- 防:
- 密钥存储于配置中心或 KMS
- 生产环境关闭详细错误信息
- 强制 HTTPS
- 日志脱敏
SQL 注入
- 攻:未对用户输入进行过滤或参数化,直接拼接 SQL 语句。
- 危:数据库被偷取、篡改、删除,甚至通过数据库执行系统命令。
- 防:
- 参数绑定:使用预编译语句(PreparedStatement)、ORM 框架内置参数化查询;
- 过滤、校验:严格输入校验;最小化数据库权限。
XXE(XML 外部实体)
- 攻:解析 XML 时启用了外部实体加载,攻击者可读取本地文件或发起 SSRF。
- 危:读取任意文件、内网探测、拒绝服务。
- 防:
- 禁用 XML 外部实体(如 DocumentBuilderFactory.setExpandEntityReferences(false))
- 使用 JSON 替代 XML
通用防御
- 安全开发生命周期:需求阶段进行风险评估,设计、编码阶段遵循安全规范,测试阶段进行黑盒扫描和渗透测试。
- 使用成熟安全框架:Spring Security、Apache Shiro 等,避免自行实现认证授权。
- 依赖管理:定期扫描安全漏洞(使用 OWASP Dependency Check),及时升级修复。
- 纵深防御:网络层防火墙、WAF、主机入侵检测、数据加密、最小权限原则。
- 监控与响应:实时审计异常行为,建立漏洞响应机制,定期演练。
【困难】如何设计一个 OAuth 2.0 服务?⭐⭐
OAuth 2.0 是一种授权框架,允许第三方应用(客户端)在资源所有者(用户)授权后,有限度地访问其受保护资源,而不需要泄露用户凭证。设计一个 OAuth 2.0 服务需要围绕其核心角色、授权模式、安全性和扩展性展开。
OAuth 2.0 核心角色
- 资源拥有者:用户,授权客户端访问其资源。
- 客户端:第三方应用,需获取授权。
- 授权服务器:核心,负责用户认证、客户端管理、颁发令牌。
- 资源服务器:托管受保护资源,验证令牌并响应请求。
授权模式(四种)
- 授权码模式(最常用,最安全)
- 流程:客户端重定向用户至授权服务器 → 用户登录授权 → 授权服务器返回授权码(code) → 客户端用 code + 密钥换取访问令牌(access token) → 访问资源。
- 适用:有后端的 Web 应用。
- 隐式模式(简化,已废弃)
- 流程:直接返回 access token(URL 片段),适用于纯前端应用,但安全性低,现已由授权码 + PKCE 替代。
- 密码模式(直接使用用户名密码,已废弃)
- 流程:客户端收集用户名密码,直接向授权服务器换令牌。
- 适用:高度信任的客户端(如官方应用),但违背 OAuth 初衷。
- 客户端凭证模式
- 流程:客户端使用自己的凭证(client_id + secret)直接获取令牌,代表客户端自身访问资源。
- 适用:服务器到服务器的调用,无用户参与。微服务内部调用,定时任务访问 API 都是这样的场景。
场景设计
【中等】如何在 10 亿个数据中找到最大的 1 万个?
构建容量大小为 1 万的堆,每次从 10 亿数据中读 1 万条数据,写入最小堆,循环直至读完所有数据。最终,还留存在最小堆中的数据就是 TOP 10000
【中等】有几台机器存储着几亿的淘宝搜索日志,假设你只有一台 2g 的电脑,如何选出搜索热度最高的十个关键词?
核心思想:分而治之 + 哈希分桶 + 堆排序
第一步:哈希分桶(分散数据)
- 操作:逐行读取几亿条日志,对每个搜索词计算哈希值,然后取模 N(例如 N=200),将记录追加写入对应的临时文件(
part_0.txt到part_199.txt)。 - 目的:相同的关键词一定会进入同一个临时文件,且每个文件大小可控(如几十到几百 MB)。
- 记忆点:“哈希取模分文件,同词同桶不乱窜。”
第二步:内存统计(桶内计数)
- 操作:依次读取每个临时文件,将其全部加载到内存,用
HashMap统计每个词的出现次数(词频)。 - 结果:每个临时文件生成一个结果文件(
result_0.txt),每行格式关键词 次数。 - 注意:因每个文件较小(≤2G 内存),HashMap 可完全容纳。
- 记忆点:“小文件全读入,哈希表里计次数。”
第三步:堆排取 Top(全局筛选)
- 操作:维护一个大小为 10 的最小堆(堆顶是当前第 10 大的次数)。
- 遍历所有结果文件的每一行,取出
次数与堆顶比较:- 若
次数 > 堆顶,则弹出堆顶,插入该词; - 否则跳过。
- 若
- 遍历所有结果文件的每一行,取出
- 目的:只需遍历一次所有中间结果,内存只存堆(10 个元素)。
- 记忆点:“最小堆里比大小,遍历一遍取前十。”
第四步:输出结果
- 堆中剩下的 10 个词即为搜索热度最高的关键词。
【中等】一张表里有三个字段(id,开始时间,结束时间),表中数据量为 5000W,如何统计流量最大的时候有多少条数据?
可以采用差分数组来实现。
可以通过将每个事件分开的开始时间和结束时间记录为增量(开始时流量 +1,结束时流量 -1),并通过扫描线的方式对每一秒进行累加,最终得到每秒的并发流量。
【中等】有 40 亿个 ID,在 1G 内存中进行去重,如何实现?
核心思想
用位图(Bitmap)标记每个 ID 是否出现过。
一个 bit 代表一个 ID,内存足够,速度极快。
条件
- ID 是 32 位无符号整数,范围
0 ~ 2^32-1(约 42 亿)。 - 因为最大 ID 约 42 亿,所以需要 42 亿个 bit 来标记每个 ID 是否出现。
内存计算
2^32 bits = 512 MB(2^32 / 8 / 1024 / 1024 = 512)。- 1G 内存 > 512MB,完全可行。
步骤
- 初始化:申请一个 512MB 的
byte数组(或bit数组),所有位初始为 0。 - 遍历:依次读取每个 ID,计算其在位图中的位置:
byteIndex = id / 8bitIndex = id % 8- 将对应位设为 1(
byte[byteIndex] |= (1 << bitIndex))。
- 结果:所有被标记为 1 的位对应的 ID 即为去重后的 ID。
优缺点
- 优点:速度快(O(n)),精确,内存可控。
- 缺点:只适用于整数且范围已知,若 ID 范围超过 42 亿(如 64 位),则内存爆炸(需要 2^64 bits,不可能)。
【中等】如果有 500G 数据需要排序,但是只有 4G 内存,如何实现?
核心思想:分块排序 + 多路归并(分而治之)
第一步:分块排序
- 将 500G 数据分成若干个小块,每块大小小于 4G(如 3.5G),保证能加载到内存。
- 对每块数据在内存中进行内部排序(如快速排序)。
- 将排序后的块写回磁盘,成为有序的临时文件。
第二步:多路归并
- 同时打开所有有序临时文件,每个文件分配一个输入缓冲区(如几十 MB)。
- 使用最小堆从所有缓冲区的当前元素中选出最小值,输出到输出缓冲区。
- 当某个输入缓冲区读完时,从对应文件继续读取下一批数据;当输出缓冲区满时,写入最终结果文件。
第三步:清理
- 所有数据归并完成后,删除临时文件。
关键优化点
- 缓冲区大小:合理分配内存,既要保证输入缓冲够用(减少磁盘 I/O),又要留足够空间给堆。
- 堆优化:使用最小堆减少比较次数,提升归并效率。
- 并行 I/O:读写磁盘可异步进行,或使用多线程重叠计算与 I/O。
- 压缩:临时文件可压缩存储,减少磁盘占用和 I/O 量。
【中等】如何导入百万数据量级的 Excel 到数据库?
流式读取 + 分批处理 + 批量插入 + 异步化
第一步、流式读取 Excel
- 问题:一次性读取百万行到内存会 OOM。
- 方案:使用支持流式读取的库(如 EasyExcel、POI 的 SXSSFWorkbook 读模式),逐行读取,逐行处理。
- 记忆点:EasyExcel 流式读,一行一行慢慢来。
第二步、数据校验与转换
- 逐行校验:对每行数据进行格式、合法性校验(如必填、类型、长度)。
- 转换:将 Excel 的行数据转换为数据库实体对象。
- 记忆点:一行一校验,转换不拖延。
第三步、分批缓存与批量插入
- 设定批大小:如每 1000 条记录攒一批,达到批大小后执行一次批量插入。
- 批量插入:使用 JDBC 的 addBatch() 或 MyBatis 的 batch 模式,减少网络和事务开销。
- 事务控制:一批一个事务,避免大事务导致锁竞争。
- 记忆点:千条一批批量插,事务分开保速度。
第四步、异步化与进度反馈
- 异步导入:前端提交导入任务后立即返回任务 ID,后端异步处理。
- 进度反馈:后端定期更新任务进度(如已处理行数),前端轮询展示。
- 记忆点:异步任务不阻塞,进度反馈看得见。
第五步、错误处理与补偿
- 错误记录:将校验失败或插入失败的行记录到错误表或日志文件,并提供下载。
- 断点续传:如果导入过程中断,可记录已成功行数,下次从中断处继续。
- 记忆点:错误行记下来,断点续传更可靠。
性能优化要点
- 数据库连接池:配置合适的连接数。
- 索引策略:导入前可暂时禁用非必要索引,导入后重建。
- 写入方式:使用 JDBC 的 rewriteBatchedStatements=true(MySQL)。
- 内存控制:流式读取 + 批处理,确保内存稳定。
【中等】Excel 导出场景很慢,如何优化?
Excel 导出慢一般有三种情况:
- 数据库查询慢
- 业务逻辑处理慢
- Excel 文件写入慢
数据库查询优化
- 痛点:
LIMIT offset, size分页在 offset 很大时性能极差,需扫描大量无效行。 - 方案:游标分页(基于主键 ID)
- 记录上一批最后一条的 ID,下次查询从该 ID 之后开始。
- SQL 示例:
SELECT * FROM orders WHERE status = 1 AND id > ? ORDER BY id ASC LIMIT 1000
- 前提:ID 字段有索引,且查询必须带
ORDER BY id ASC,让 MySQL 走索引顺序扫描。 - 优势:每次只扫描固定行数,性能稳定,速度提升数百倍。
业务逻辑优化
- 痛点:循环中多次调用 RPC / 缓存,导致网络 IO 次数爆炸,耗时剧增。
- 方案:批量查询
- 先从列表中提取所有查询条件(如用户 ID),一次性批量调用
batchGetUserByIds。 - 再用结果 Map 回填数据,将 N 次 RPC 降为 1 次。
- 先从列表中提取所有查询条件(如用户 ID),一次性批量调用
- 优势:大幅减少网络交互,显著提升接口响应速度。
Excel 生成优化
- 痛点:POI 等传统框架将全量数据加载到内存,大数据量导出易导致 OOM。
- 方案:EasyExcel 流式写入 + 分批查询
- 流式写入:边查边写,每批数据刷入磁盘,内存占用稳定在 100-200 MB。
- 分批查询:结合游标分页,每次查询 1000 行,避免全量加载。
- 进阶:超大数据量可采用多线程分片导出,按地区 / 时间分片,并发生成多个 Sheet 或文件,最后打包 ZIP。
- 优势:避免 OOM,支持超大数据量导出,内存占用可控。
【中等】假设生产者-消费者模型中有 200 万个生产者,只有 1 个消费者,如何实现?
挑战和目标
核心挑战
- 200 万并发写:直接竞争同一个队列会导致严重锁冲突、CPU 飙升。
- 单消费者:消费速度可能成为瓶颈,需最大化消费者效率。
- 内存压力:海量数据堆积可能撑爆内存。
设计目标:高吞吐、低延迟、背压保护、数据不丢失(按需)
生产者优化
问题:200 万个生产者如果直接写入同一队列,竞争激烈。
方案:采用无锁环形队列 + 多生产者序号分配,典型实现是 Disruptor。
- Disruptor 原理:
- 预先分配固定大小的环形缓冲区(RingBuffer)。
- 每个生产者通过 CAS 竞争获取下一个可写入的序号,然后写入数据。
- 消费者通过序号屏障读取。
- 优点:无锁、预分配内存、缓存行填充避免伪共享,性能极高。
- 记忆点:Disruptor 环形缓冲区,CAS 分配序号,多生产者无锁写入。
消费者优化
问题:单消费者处理速度必须跟上 200 万生产者的写入速度。
方案:消费者内部批量处理 + 异步化。
- 批量拉取:消费者每次从环形缓冲区拉取一批数据(如 1000 条),减少调用次数。
- 多线程处理业务:消费者收到一批数据后,提交给线程池并行处理,但需保证消费顺序(如需)。
背压机制
问题:生产者写入速度超过消费者处理速度,数据堆积。
方案:缓冲区满则阻塞,监控阈值防溢出。
- Disruptor 等待策略:当 RingBuffer 满时,生产者可配置阻塞、自旋或抛出异常。
- 拒绝策略:若堆积超过阈值,可降级处理(如丢弃非关键数据、记录日志)。
- 监控告警:实时监控 RingBuffer 使用率,触发扩容或限流。
生产者线程管理
问题:200 万个生产者如果是独立线程,系统无法支撑。
方案:生产者非线程池,IO 模型限并发,事件驱动写队列。
- 使用 NIO 或 Reactor 模型(如 Netty)处理海量连接,每个连接的事件由少量 IO 线程处理,这些线程作为生产者写入队列。
- 若生产者是业务线程,则使用线程池限制并发数,由有限线程代表 200 万任务写入。
【中等】如何对 500 万会员提前 7 天进行过期提醒?
核心思路是:定时任务 + 索引优化 + 异步通知
- 在会员表的
expire_date字段上建立索引。 - 设置一个定时任务,定期滚动翻页扫描表记录,筛选 7 天后过期的数据。
- 对过期会员发送提醒,并在记录表中标记状态为已提醒。
问题排查解决
【中等】接口响应慢如何排查?
先看监控定方向,再查网络和日志,重点排查数据库和代码,最后看外部依赖与并发量。
接口变慢排查步骤
- 看监控:CPU、内存、磁盘、网络是否有瓶颈。
- 查网络:是否有延迟、带宽打满,尤其跨服务 / 跨区域调用。
- 看日志:确认是一直慢,还是特定场景 / 时间段慢。
- 查数据库:慢查询、锁竞争、连接池问题。
- 查代码:新功能是否有高复杂度算法、不必要同步、缓存失效。
接口变慢原因
- 资源瓶颈
- CPU 高:计算密集型任务(加密、大数据处理)→ 用
top/htop定位进程。 - 内存泄漏:GC 频繁 → 用
jvisualvm/JProfiler分析。 - 磁盘 I/O 高:频繁读写(数据库、日志)→ 用
iostat/sar查看。 - 网络问题:带宽不足 / 高延迟 → 用
ping/traceroute或云监控。
- CPU 高:计算密集型任务(加密、大数据处理)→ 用
- 数据库
- 慢查询:复杂 SQL、无索引、全表扫描 → 用慢查询日志 +
EXPLAIN。 - 连接池问题:连接数不足 / 过多 → 用 HikariCP/Druid 监控。
- 锁竞争:行锁 / 表锁冲突 → 用
SHOW ENGINE INNODB STATUS(MySQL)。
- 慢查询:复杂 SQL、无索引、全表扫描 → 用慢查询日志 +
- 代码性能
- 高时间复杂度:循环、递归、排序处理大数据 → 用 JProfiler 找热点。
- 同步 / 死锁:
synchronized粒度太大、死锁 → 检查锁设计。 - 缓存失效:未用缓存、命中率低 → 检查缓存配置与命中率。
- 外部依赖
- 外部服务慢:第三方 API / 支付网关 → 加超时、熔断、降级。
- 并发过高:超出接口承载能力 → 用负载均衡、限流。
【中等】系统每天晚上都会有一小时左右的时间瘫痪,可能原因是什么?
系统规律性瘫痪(每天固定时段)的核心原因大部分与周期性操作或资源瓶颈有关。
常见原因包括:
- 定时任务 / 批处理:夜间运行的定时任务(如数据对账、报表生成、批量更新)可能触发高 CPU / 内存占用、数据库锁竞争或 IO 瓶颈。
- 资源周期性耗尽:如缓存失效(缓存击穿)、连接池 / 线程池被占满(夜间批量请求)、数据库连接不够用。
- 外部依赖异常:第三方系统在夜间维护(如接口限流、服务降级),或消息队列堆积(夜间生产端集中发消息)。
- 夜间运维策略:(如自动扩容缩容关闭)或日志切割导致问题。
【中等】线上服务器 CPU 飙升如何排查?
先止损
如果是单个或少数服务器 CPU 飙升,先把问题服务器从负载均衡器摘掉。
如果是全部服务器 CPU 飙升,先扩容。
排查
第一步、定位高 CPU 进程
- 命令:
top - 操作:按
P键(大写)按 CPU 使用率排序,找到 CPU 占用最高的进程 PID。 - 记忆点:“top 看进程,P 键排第一。”
第二步、定位高 CPU 线程
- 命令:
top -Hp <PID>或ps -mp <PID> -o THREAD,tid,time - 操作:找到该进程内 CPU 占用最高的线程 TID(十进制)。
- 记忆点:“top -Hp 看线程,找到最耗 CPU 的 TID。”
第三步、线程 ID 转十六进制
- 操作:
printf "%x\n" <TID>将十进制 TID 转为十六进制(nid)。 - 记忆点:“TID 转十六进,堆栈里面去找它。”
第四步、打印进程堆栈
- 命令:
jstack <PID> > stack.log或jstack <PID> | grep -A 30 <nid>(十六进制小写) - 操作:输出堆栈,搜索
nid=0x...找到对应线程的堆栈。 - 记忆点:jstack 打堆栈,nid 定位到代码行。
第五步、分析堆栈,定位原因
- 查看线程状态:是 RUNNABLE?还是 BLOCKED?或是在执行 GC?
- 定位代码:找到对应的包名、类名、行号,分析该处逻辑。
- 记忆点:状态码先行,分析逻辑找病因。
常见 CPU 飙升原因
| 原因 | 特征 | 解决 |
|---|---|---|
| 死循环/空转 | 线程一直 RUNNABLE,堆栈在同一代码块反复执行 | 修复代码逻辑 |
| 频繁 GC | CPU 高但堆栈很多 GC 线程 | 分析堆内存、GC 日志 |
| 锁竞争/线程阻塞 | 大量线程 BLOCKED,上下文切换频繁 | 优化锁粒度 |
| 正则表达式回溯 | 复杂正则导致 CPU 爆炸 | 优化正则或使用替代方案 |
| 序列化/反序列化 | 大对象反复序列化 | 优化数据格式 |
| 外部调用无超时 | 无限等待响应 | 设置超时、熔断 |
【中等】线上数据库连接池打满如何排查?
核心思路
- 先止损,再排查。
- 重启服务恢复,监控数据回头看。
排查思路
一、突发流量
- 检查事故时间点是否有运营活动、推送通知。
- 流量突增导致连接被占满,请求排队。
- 根本原因:压测不足、未限流。
- 记忆点:流量突增压垮池,压测限流没做好。
二、慢 SQL
- 查找近期上线的功能,分析慢查询日志。
- 检查是否存在全表扫描、未命中索引、锁等待。
- 一条慢 SQL 跑 10 秒,连接就被占 10 秒。
- 记忆点:慢 SQL 占连接,索引加好不能忘。
三、连接池配置过小
- 很多框架默认最大连接数只有 8 或 10,业务量稍大就不够。
- 需根据压测调整最小/最大连接数、超时时间。
- 记忆点:默认配置太小,压测调整才好。