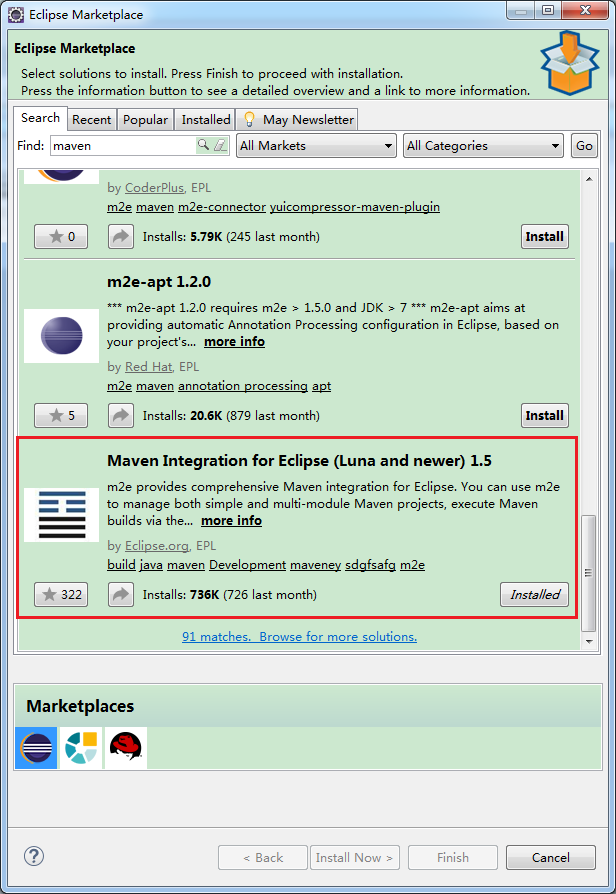
JavaWeb 之 Jsp 指南
JavaWeb 之 Jsp 指南
简介
什么是 Java Server Pages
JSP全称Java Server Pages,是一种动态网页开发技术。
它使用 JSP 标签在 HTML 网页中插入 Java 代码。标签通常以 <% 开头以 %> 结束。
JSP 是一种 Java servlet,主要用于实现 Java web 应用程序的用户界面部分。网页开发者们通过结合 HTML 代码、XHTML 代码、XML 元素以及嵌入 JSP 操作和命令来编写 JSP。
JSP 通过网页表单获取用户输入数据、访问数据库及其他数据源,然后动态地创建网页。
JSP 标签有多种功能,比如访问数据库、记录用户选择信息、访问 JavaBeans 组件等,还可以在不同的网页中传递控制信息和共享信息。
为什么使用 JSP
JSP 也是一种 Servlet,因此 JSP 能够完成 Servlet 能完成的任何工作。
JSP 程序与 CGI 程序有着相似的功能,但和 CGI 程序相比,JSP 程序有如下优势:
- 性能更加优越,因为 JSP 可以直接在 HTML 网页中动态嵌入元素而不需要单独引用 CGI 文件。
- 服务器调用的是已经编译好的 JSP 文件,而不像 CGI/Perl 那样必须先载入解释器和目标脚本。
- JSP 基于 Java Servlets API,因此,JSP 拥有各种强大的企业级 Java API,包括 JDBC,JNDI,EJB,JAXP 等等。
- JSP 页面可以与处理业务逻辑的 servlets 一起使用,这种模式被 Java servlet 模板引擎所支持。
最后,JSP 是 Java EE 不可或缺的一部分,是一个完整的企业级应用平台。这意味着 JSP 可以用最简单的方式来实现最复杂的应用。
JSP 的优势
以下列出了使用 JSP 带来的其他好处:
- 与 ASP 相比:JSP 有两大优势。首先,动态部分用 Java 编写,而不是 VB 或其他 MS 专用语言,所以更加强大与易用。第二点就是 JSP 易于移植到非 MS 平台上。
- 与纯 Servlets 相比:JSP 可以很方便的编写或者修改 HTML 网页而不用去面对大量的 println 语句。
- 与 SSI 相比:SSI 无法使用表单数据、无法进行数据库链接。
- 与 JavaScript 相比:虽然 JavaScript 可以在客户端动态生成 HTML,但是很难与服务器交互,因此不能提供复杂的服务,比如访问数据库和图像处理等等。
- 与静态 HTML 相比:静态 HTML 不包含动态信息。
JSP 工作原理
JSP 是一种 Servlet,但工作方式和 Servlet 有所差别。
Servlet 是先将源代码编译为 class 文件后部署到服务器下的,先编译后部署。
Jsp 是先将源代码部署到服务器再编译,先部署后编译。
Jsp 会在客户端第一次请求 Jsp 文件时被编译为 HttpJspPage 类(Servlet 的一个子类)。该类会被服务器临时存放在服务器工作目录里。所以,第一次请求 Jsp 后,访问速度会变快就是这个道理。
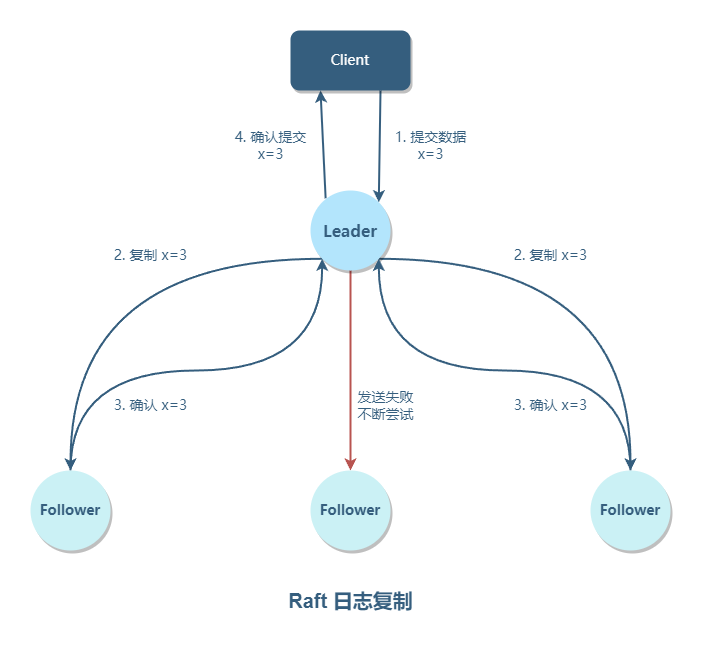
JSP 工作流程
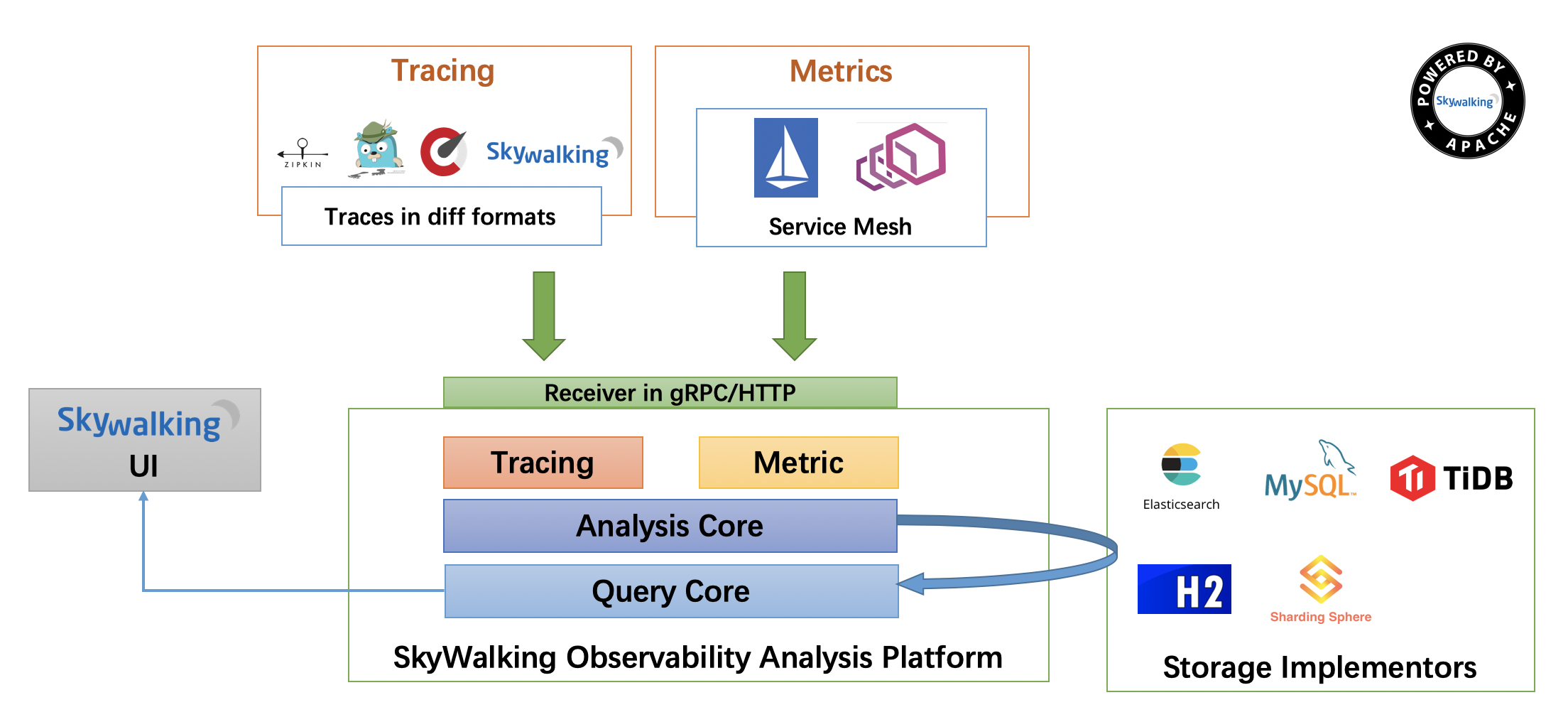
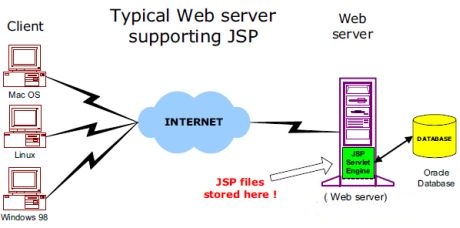
网络服务器需要一个 JSP 引擎,也就是一个容器来处理 JSP 页面。容器负责截获对 JSP 页面的请求。本教程使用内嵌 JSP 容器的 Apache 来支持 JSP 开发。
JSP 容器与 Web 服务器协同合作,为 JSP 的正常运行提供必要的运行环境和其他服务,并且能够正确识别专属于 JSP 网页的特殊元素。
下图显示了 JSP 容器和 JSP 文件在 Web 应用中所处的位置。
工作步骤
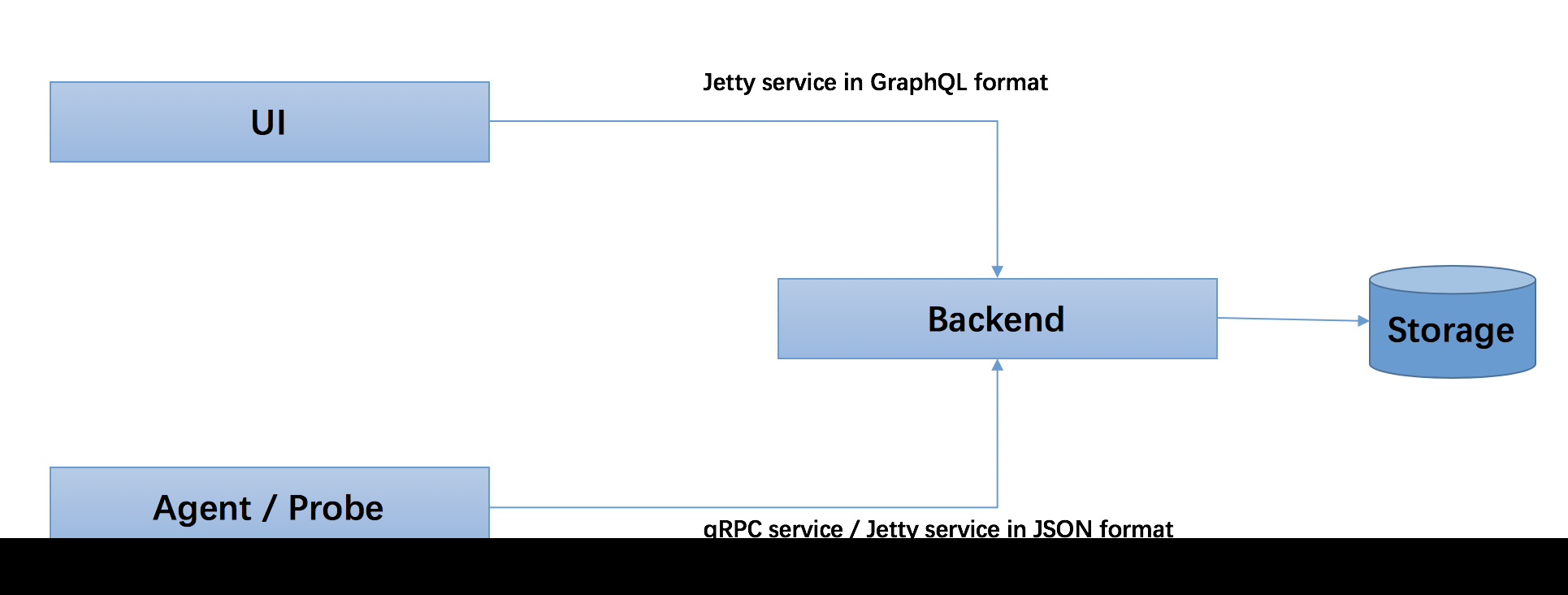
以下步骤表明了 Web 服务器是如何使用 JSP 来创建网页的:
- 就像其他普通的网页一样,您的浏览器发送一个 HTTP 请求给服务器。
- Web 服务器识别出这是一个对 JSP 网页的请求,并且将该请求传递给 JSP 引擎。通过使用 URL 或者.jsp 文件来完成。
- JSP 引擎从磁盘中载入 JSP 文件,然后将它们转化为 servlet。这种转化只是简单地将所有模板文本改用 println()语句,并且将所有的 JSP 元素转化成 Java 代码。
- JSP 引擎将 servlet 编译成可执行类,并且将原始请求传递给 servlet 引擎。
- Web 服务器的某组件将会调用 servlet 引擎,然后载入并执行 servlet 类。在执行过程中,servlet 产生 HTML 格式的输出并将其内嵌于 HTTP response 中上交给 Web 服务器。
- Web 服务器以静态 HTML 网页的形式将 HTTP response 返回到您的浏览器中。
- 最终,Web 浏览器处理 HTTP response 中动态产生的 HTML 网页,就好像在处理静态网页一样。
以上提及到的步骤可以用下图来表示:
一般情况下,JSP 引擎会检查 JSP 文件对应的 servlet 是否已经存在,并且检查 JSP 文件的修改日期是否早于 servlet。如果 JSP 文件的修改日期早于对应的 servlet,那么容器就可以确定 JSP 文件没有被修改过并且 servlet 有效。这使得整个流程与其他脚本语言(比如 PHP)相比要高效快捷一些。
JSP 生命周期
理解 JSP 底层功能的关键就是去理解它们所遵守的生命周期。
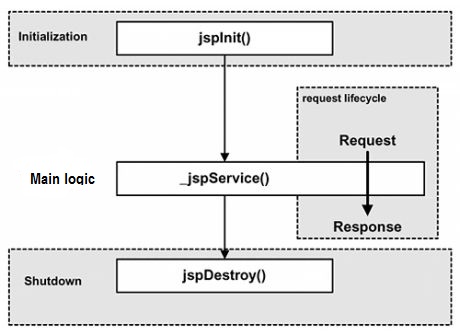
JSP 生命周期就是从创建到销毁的整个过程,类似于 servlet 生命周期,区别在于 JSP 生命周期还包括将 JSP 文件编译成 servlet。
以下是 JSP 生命周期中所走过的几个阶段:
- 编译阶段:servlet 容器编译 servlet 源文件,生成 servlet 类
- 初始化阶段:加载与 JSP 对应的 servlet 类,创建其实例,并调用它的初始化方法
- 执行阶段:调用与 JSP 对应的 servlet 实例的服务方法
- 销毁阶段:调用与 JSP 对应的 servlet 实例的销毁方法,然后销毁 servlet 实例
很明显,JSP 生命周期的四个主要阶段和 servlet 生命周期非常相似,下面给出图示:
JSP 编译
当浏览器请求 JSP 页面时,JSP 引擎会首先去检查是否需要编译这个文件。如果这个文件没有被编译过,或者在上次编译后被更改过,则编译这个 JSP 文件。
编译的过程包括三个步骤:
- 解析 JSP 文件。
- 将 JSP 文件转为 servlet。
- 编译 servlet。
JSP 初始化
容器载入 JSP 文件后,它会在为请求提供任何服务前调用 jspInit()方法。如果您需要执行自定义的 JSP 初始化任务,复写 jspInit()方法就行了,就像下面这样:
1 | public void jspInit(){ |
一般来讲程序只初始化一次,servlet 也是如此。通常情况下您可以在 jspInit()方法中初始化数据库连接、打开文件和创建查询表。
JSP 执行
这一阶段描述了 JSP 生命周期中一切与请求相关的交互行为,直到被销毁。
当 JSP 网页完成初始化后,JSP 引擎将会调用 _jspService() 方法。
_jspService() 方法需要一个 HttpServletRequest 对象和一个 HttpServletResponse 对象作为它的参数,就像下面这样:
1 | void _jspService(HttpServletRequest request, |
_jspService() 方法在每个 request 中被调用一次并且负责产生与之相对应的 response,并且它还负责产生所有 7 个 HTTP 方法的回应,比如 GET、POST、DELETE 等等。
JSP 清理
JSP 生命周期的销毁阶段描述了当一个 JSP 网页从容器中被移除时所发生的一切。
jspDestroy()方法在 JSP 中等价于 servlet 中的销毁方法。当您需要执行任何清理工作时复写 jspDestroy()方法,比如释放数据库连接或者关闭文件夹等等。
jspDestroy()方法的格式如下:
1 | public void jspDestroy() { |
语法
脚本
脚本程序可以包含任意量的 Java 语句、变量、方法或表达式,只要它们在脚本语言中是有效的。
脚本程序的语法格式:
1 | <% 代码片段 %> |
或者,您也可以编写与其等价的 XML 语句,就像下面这样:
1 | <jsp:scriptlet> |
任何文本、HTML 标签、JSP 元素必须写在脚本程序的外面。
下面给出一个示例,同时也是本教程的第一个 JSP 示例:
1 | <html> |
注意:请确保 Apache Tomcat 已经安装在 C:\apache-tomcat-7.0.2 目录下并且运行环境已经正确设置。
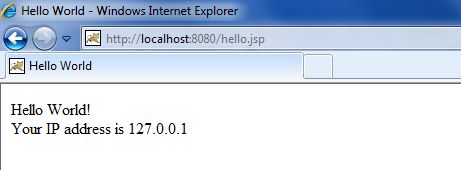
将以上代码保存在 hello.jsp 中,然后将它放置在 C:\apache-tomcat-7.0.2\webapps\ROOT 目录下,打开浏览器并在地址栏中输入 http://localhost:8080/hello.jsp 。运行后得到以下结果:
中文编码问题
如果我们要在页面正常显示中文,我们需要在 JSP 文件头部添加以下代码:<>
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
接下来我们将以上程序修改为:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
这样中文就可以正常显示了。
JSP 声明
一个声明语句可以声明一个或多个变量、方法,供后面的 Java 代码使用。在 JSP 文件中,您必须先声明这些变量和方法然后才能使用它们。
JSP 声明的语法格式:
1 | <%! declaration; [ declaration; ]+ ... %> |
或者,您也可以编写与其等价的 XML 语句,就像下面这样:
1 | <jsp:declaration> |
程序示例:
1 | <%! int i = 0; %> <%! int a, b, c; %> <%! Circle a = new Circle(2.0); %> |
JSP 表达式
一个 JSP 表达式中包含的脚本语言表达式,先被转化成 String,然后插入到表达式出现的地方。
由于表达式的值会被转化成 String,所以您可以在一个文本行中使用表达式而不用去管它是否是 HTML 标签。
表达式元素中可以包含任何符合 Java 语言规范的表达式,但是不能使用分号来结束表达式。
JSP 表达式的语法格式:
1 | <%= 表达式 %> |
同样,您也可以编写与之等价的 XML 语句:
1 | <jsp:expression> |
程序示例:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
运行后得到以下结果:
1 | 今天的日期是: 2016-6-25 13:40:07 |
JSP 注释
JSP 注释主要有两个作用:为代码作注释以及将某段代码注释掉。
JSP 注释的语法格式:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
运行后得到以下结果:
1 | 今天的日期是: 2016-6-25 13:41:26 |
不同情况下使用注释的语法规则:
| 语法 | 描述 |
|---|---|
<%-- 注释 --%> |
JSP 注释,注释内容不会被发送至浏览器甚至不会被编译 |
<!-- 注释 --> |
HTML 注释,通过浏览器查看网页源代码时可以看见注释内容 |
<% |
代表静态 <% 常量 |
%> |
代表静态 %> 常量 |
' |
在属性中使用的单引号 |
" |
在属性中使用的双引号 |
控制语句
JSP 提供对 Java 语言的全面支持。您可以在 JSP 程序中使用 Java API 甚至建立 Java 代码块,包括判断语句和循环语句等等。
if…else 语句
If…else块,请看下面这个例子:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
运行后得到以下结果:
1 | IF...ELSE 实例 |
switch…case 语句
现在来看看 switch…case 块,与 if…else 块有很大的不同,它使用 out.println(),并且整个都装在脚本程序的标签中,就像下面这样:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
浏览器访问,运行后得出以下结果:
1 | SWITCH...CASE 实例 |
循环语句
在 JSP 程序中可以使用 Java 的三个基本循环类型:for,while,和 do…while。
让我们来看看 for 循环的例子,以下输出的不同字体大小的”菜鸟教程”:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
运行后得到以下结果:

将上例改用 while 循环来写:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
浏览器访问,输出结果为(fontSize 初始化为 0,所以多输出了一行):

JSP 运算符
JSP 支持所有 Java 逻辑和算术运算符。
下表罗列出了 JSP 常见运算符,优先级从高到底:
| 类别 | 操作符 | 结合性 |
|---|---|---|
| 后缀 | () [] . (点运算符) |
左到右 |
| 一元 | ++ - - ! ~ |
右到左 |
| 可乘性 | * / % |
左到右 |
| 可加性 | + - |
左到右 |
| 移位 | >> >>> << |
左到右 |
| 关系 | > >= < <= |
左到右 |
| 相等/不等 | == != |
左到右 |
| 位与 | & |
左到右 |
| 位异或 | ^ |
左到右 |
| 位或 | ` | ` |
| 逻辑与 | && |
左到右 |
| 逻辑或 | ` | |
| 条件判断 | ?: |
右到左 |
| 赋值 | `= += -= *= /= %= >>= <<= &= ^= | =` |
| 逗号 | , |
左到右 |
JSP 字面量
JSP 语言定义了以下几个字面量:
- 布尔值(boolean):true 和 false;
- 整型(int):与 Java 中的一样;
- 浮点型(float):与 Java 中的一样;
- 字符串(string):以单引号或双引号开始和结束;
- Null:null。
指令
JSP 指令用来设置整个 JSP 页面相关的属性,如网页的编码方式和脚本语言。
JSP 指令以开<%@开始,以%>结束。
JSP 指令语法格式如下:
1 | <%@ directive attribute="value" %> |
指令可以有很多个属性,它们以键值对的形式存在,并用逗号隔开。
JSP 中的三种指令标签:
| 指令 | 描述 |
|---|---|
<%@ page ... %> |
定义网页依赖属性,比如脚本语言、error 页面、缓存需求等等 |
<%@ include ... %> |
包含其他文件 |
<%@ taglib ... %> |
引入标签库的定义,可以是自定义标签 |
Page 指令
Page 指令为容器提供当前页面的使用说明。一个 JSP 页面可以包含多个page指令。
Page 指令的语法格式:
1 | <%@ page attribute="value" %> |
等价的 XML 格式:
1 | <jsp:directive.page attribute="value" /> |
例:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
属性
下表列出与 Page 指令相关的属性:
| 属性 | 描述 |
|---|---|
| buffer | 指定 out 对象使用缓冲区的大小 |
| autoFlush | 控制 out 对象的 缓存区 |
| contentType | 指定当前 JSP 页面的 MIME 类型和字符编码 |
| errorPage | 指定当 JSP 页面发生异常时需要转向的错误处理页面 |
| isErrorPage | 指定当前页面是否可以作为另一个 JSP 页面的错误处理页面 |
| extends | 指定 servlet 从哪一个类继承 |
| import | 导入要使用的 Java 类 |
| info | 定义 JSP 页面的描述信息 |
| isThreadSafe | 指定对 JSP 页面的访问是否为线程安全 |
| language | 定义 JSP 页面所用的脚本语言,默认是 Java |
| session | 指定 JSP 页面是否使用 session |
| isELIgnored | 指定是否执行 EL 表达式 |
| isScriptingEnabled | 确定脚本元素能否被使用 |
Include 指令
JSP 可以通过include指令来包含其他文件。
被包含的文件可以是 JSP 文件、HTML 文件或文本文件。包含的文件就好像是该 JSP 文件的一部分,会被同时编译执行。
Include 指令的语法格式如下:
1 | <%@ include file="文件相对 url 地址" %> |
include 指令中的文件名实际上是一个相对的 URL 地址。
如果您没有给文件关联一个路径,JSP 编译器默认在当前路径下寻找。
等价的 XML 语法:
1 | <jsp:directive.include file="文件相对 url 地址" /> |
Taglib 指令
JSP 允许用户自定义标签,一个自定义标签库就是自定义标签的集合。
taglib指令引入一个自定义标签集合的定义,包括库路径、自定义标签。
taglib指令的语法:
1 | <%@ taglib uri="uri" prefix="prefixOfTag" %> |
uri 属性确定标签库的位置,prefix 属性指定标签库的前缀。
等价的 XML 语法:
1 | <jsp:directive.taglib uri="uri" prefix="prefixOfTag" /> |
JSP 动作元素
JSP 动作元素是一组 JSP 内置的标签,只需要书写很少的标记代码就能使用 JSP 提供的丰富功能。JSP 动作元素是对常用的 JSP 功能的抽象与封装,包括两种,自定义 JSP 动作元素与标准 JSP 动作元素。
与 JSP 指令元素不同的是,JSP 动作元素在请求处理阶段起作用。JSP 动作元素是用 XML 语法写成的。
利用 JSP 动作可以动态地插入文件、重用 JavaBean 组件、把用户重定向到另外的页面、为 Java 插件生成 HTML 代码。
动作元素只有一种语法,它符合 XML 标准:
1 | <jsp:action_name attribute="value" /> |
动作元素基本上都是预定义的函数,JSP 规范定义了一系列的标准动作,它用 JSP 作为前缀,可用的标准动作元素如下:
| 语法 | 描述 |
|---|---|
| jsp:include | 在页面被请求的时候引入一个文件。 |
| jsp:useBean | 寻找或者实例化一个 JavaBean。 |
| jsp:setProperty | 设置 JavaBean 的属性。 |
| jsp:getProperty | 输出某个 JavaBean 的属性。 |
| jsp:forward | 把请求转到一个新的页面。 |
| jsp:plugin | 根据浏览器类型为 Java 插件生成 OBJECT 或 EMBED 标记。 |
| jsp:element | 定义动态 XML 元素 |
| jsp:attribute | 设置动态定义的 XML 元素属性。 |
| jsp:body | 设置动态定义的 XML 元素内容。 |
| jsp:text | 在 JSP 页面和文档中使用写入文本的模板 |
常见的属性
所有的动作要素都有两个属性:id 属性和 scope 属性。
- id 属性:id 属性是动作元素的唯一标识,可以在 JSP 页面中引用。动作元素创建的 id 值可以通过 PageContext 来调用。
- scope 属性:该属性用于识别动作元素的生命周期。 id 属性和 scope 属性有直接关系,scope 属性定义了相关联 id 对象的寿命。 scope 属性有四个可能的值: (a) page, (b)request, (c)session, 和 (d) application。
<jsp:include>
<jsp:include> 用来包含静态和动态的文件。该动作把指定文件插入正在生成的页面。
如果被包含的文件为 JSP 程序,则会先执行 JSP 程序,再将执行结果包含进来。
语法格式如下:
1 | <jsp:include page="相对 URL 地址" flush="true" /> |
前面已经介绍过 include 指令,它是在 JSP 文件被转换成 Servlet 的时候引入文件,而这里的 jsp:include 动作不同,插入文件的时间是在页面被请求的时候。
以下是 include 动作相关的属性列表。
| 属性 | 描述 |
|---|---|
| page | 包含在页面中的相对 URL 地址。 |
| flush | 布尔属性,定义在包含资源前是否刷新缓存区。 |
示例:
以下我们定义了两个文件 date.jsp 和 main.jsp,代码如下所示:
date.jsp 文件代码:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
main.jsp 文件代码:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
现在将以上两个文件放在服务器的根目录下,访问 main.jsp 文件。显示结果如下:
1 | include 动作实例 |
<jsp:useBean>
jsp:useBean 动作用来加载一个将在 JSP 页面中使用的 JavaBean。
这个功能非常有用,因为它使得我们可以发挥 Java 组件复用的优势。
jsp:useBean 动作最简单的语法为:
1 | <jsp:useBean id="name" class="package.class" /> |
在类载入后,我们既可以通过 jsp:setProperty 和 jsp:getProperty 动作来修改和检索 bean 的属性。
以下是 useBean 动作相关的属性列表。
| 属性 | 描述 |
|---|---|
| class | 指定 Bean 的完整包名。 |
| type | 指定将引用该对象变量的类型。 |
| beanName | 通过 java.beans.Beans 的 instantiate() 方法指定 Bean 的名字。 |
在给出具体实例前,让我们先来看下 jsp:setProperty 和 jsp:getProperty 动作元素:
<jsp:setProperty>
jsp:setProperty 用来设置已经实例化的 Bean 对象的属性,有两种用法。首先,你可以在 jsp:useBean 元素的外面(后面)使用 jsp:setProperty,如下所示:
1 | <jsp:useBean id="myName" ... /> |
此时,不管 jsp:useBean 是找到了一个现有的 Bean,还是新创建了一个 Bean 实例,jsp:setProperty 都会执行。第二种用法是把 jsp:setProperty 放入 jsp:useBean 元素的内部,如下所示:
1 | <jsp:useBean id="myName" ... > |
此时,jsp:setProperty 只有在新建 Bean 实例时才会执行,如果是使用现有实例则不执行 jsp:setProperty。
jsp:setProperty 动作有下面四个属性,如下表:
| 属性 | 描述 |
|---|---|
| name | name 属性是必需的。它表示要设置属性的是哪个 Bean。 |
| property | property 属性是必需的。它表示要设置哪个属性。有一个特殊用法:如果 property 的值是”*“,表示所有名字和 Bean 属性名字匹配的请求参数都将被传递给相应的属性 set 方法。 |
| value | value 属性是可选的。该属性用来指定 Bean 属性的值。字符串数据会在目标类中通过标准的 valueOf 方法自动转换成数字、boolean、Boolean、 byte、Byte、char、Character。例如,boolean 和 Boolean 类型的属性值(比如”true”)通过 Boolean.valueOf 转换,int 和 Integer 类型的属性值(比如”42”)通过 Integer.valueOf 转换。 value 和 param 不能同时使用,但可以使用其中任意一个。 |
| param | param 是可选的。它指定用哪个请求参数作为 Bean 属性的值。如果当前请求没有参数,则什么事情也不做,系统不会把 null 传递给 Bean 属性的 set 方法。因此,你可以让 Bean 自己提供默认属性值,只有当请求参数明确指定了新值时才修改默认属性值。 |
<jsp:getProperty>
jsp:getProperty 动作提取指定 Bean 属性的值,转换成字符串,然后输出。语法格式如下:
1 | <jsp:useBean id="myName" ... /> |
下表是与 getProperty 相关联的属性:
| 属性 | 描述 |
|---|---|
| name | 要检索的 Bean 属性名称。Bean 必须已定义。 |
| property | 表示要提取 Bean 属性的值 |
实例
以下实例我们使用了 Bean:
1 | package com.runoob.main; |
编译以上实例文件 TestBean.java :
1 | $ javac TestBean.java |
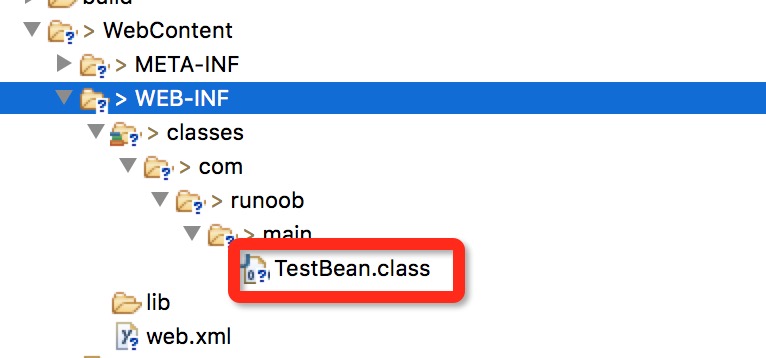
编译完成后会在当前目录下生成一个 TestBean.class 文件, 将该文件拷贝至当前 JSP 项目的 WebContent/WEB-INF/classes/com/runoob/main 下( com/runoob/main 包路径,没有需要手动创建)。
下面是一个 Eclipse 中目录结构图:
下面是一个很简单的例子,它的功能是装载一个 Bean,然后设置/读取它的 message 属性。
现在让我们在 main.jsp 文件中调用该 Bean:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
浏览器访问,执行以上文件,输出如下所示:

<jsp:forward>
jsp:forward 动作把请求转到另外的页面。jsp:forward 标记只有一个属性 page。语法格式如下所示:
1 | <jsp:forward page="相对 URL 地址" /> |
以下是 forward 相关联的属性:
| 属性 | 描述 |
|---|---|
| page | page 属性包含的是一个相对 URL。page 的值既可以直接给出,也可以在请求的时候动态计算,可以是一个 JSP 页面或者一个 Java Servlet. |
实例
以下实例我们使用了两个文件,分别是: date.jsp 和 main.jsp。
date.jsp 文件代码如下:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
main.jsp 文件代码:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
现在将以上两个文件放在服务器的根目录下,访问 main.jsp 文件。显示结果如下:
1 | 今天的日期是: 2016-6-25 14:37:25 |
<jsp:plugin>
jsp:plugin 动作用来根据浏览器的类型,插入通过 Java 插件 运行 Java Applet 所必需的 OBJECT 或 EMBED 元素。
如果需要的插件不存在,它会下载插件,然后执行 Java 组件。 Java 组件可以是一个 applet 或一个 JavaBean。
plugin 动作有多个对应 HTML 元素的属性用于格式化 Java 组件。param 元素可用于向 Applet 或 Bean 传递参数。
以下是使用 plugin 动作元素的典型实例:
1 | <jsp:plugin type="applet" codebase="dirname" code="MyApplet.class" |
如果你有兴趣可以尝试使用 applet 来测试 jsp:plugin 动作元素,<fallback> 元素是一个新元素,在组件出现故障的错误是发送给用户错误信息。
<jsp:element> 、 <jsp:attribute>、<jsp:body>
<jsp:element> 、 <jsp:attribute>、<jsp:body> 动作元素动态定义 XML 元素。动态是非常重要的,这就意味着 XML 元素在编译时是动态生成的而非静态。
以下实例动态定义了 XML 元素:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" |
浏览器访问以下页面,输出结果如下所示:

<jsp:text>
jsp:text动作元素允许在 JSP 页面和文档中使用写入文本的模板,语法格式如下:
1 | <jsp:text>模板数据</jsp:text> |
以上文本模板不能包含其他元素,只能只能包含文本和 EL 表达式(注:EL 表达式将在后续章节中介绍)。请注意,在 XML 文件中,您不能使用表达式如 ${whatever > 0},因为>符号是非法的。 你可以使用 ${whatever gt 0}表达式或者嵌入在一个 CDATA 部分的值。
1 | <jsp:text><![CDATA[<br>]]></jsp:text> |
如果你需要在 XHTML 中声明 DOCTYPE,必须使用到 <jsp:text> 动作元素,实例如下:
1 | <jsp:text><![CDATA[<!DOCTYPE html |
你可以对以上实例尝试使用jsp:text及不使用该动作元素执行结果的区别。
JSP 隐式对象
JSP 隐式对象是 JSP 容器为每个页面提供的 Java 对象,开发者可以直接使用它们而不用显式声明。JSP 隐式对象也被称为预定义变量。
JSP 所支持的九大隐式对象:
| 对象 | 描述 |
|---|---|
| request | HttpServletRequest类的实例 |
| response | HttpServletResponse类的实例 |
| out | PrintWriter类的实例,用于把结果输出至网页上 |
| session | HttpSession类的实例 |
| application | ServletContext类的实例,与应用上下文有关 |
| config | ServletConfig类的实例 |
| pageContext | PageContext类的实例,提供对 JSP 页面所有对象以及命名空间的访问 |
| page | 类似于 Java 类中的 this 关键字 |
| Exception | Exception类的对象,代表发生错误的 JSP 页面中对应的异常对象 |
request 对象
request对象是javax.servlet.http.HttpServletRequest 类的实例。
每当客户端请求一个 JSP 页面时,JSP 引擎就会制造一个新的request对象来代表这个请求。
request对象提供了一系列方法来获取 HTTP 头信息,cookies,HTTP 方法等等。
response 对象
response对象是javax.servlet.http.HttpServletResponse类的实例。
当服务器创建request对象时会同时创建用于响应这个客户端的response对象。
response对象也定义了处理 HTTP 头模块的接口。通过这个对象,开发者们可以添加新的 cookies,时间戳,HTTP 状态码等等。
out 对象
out对象是javax.servlet.jsp.JspWriter类的实例,用来在response对象中写入内容。
最初的JspWriter类对象根据页面是否有缓存来进行不同的实例化操作。可以在page指令中使用buffered='false'属性来轻松关闭缓存。
JspWriter类包含了大部分java.io.PrintWriter类中的方法。不过,JspWriter新增了一些专为处理缓存而设计的方法。还有就是,JspWriter类会抛出IOExceptions异常,而PrintWriter不会。
下表列出了我们将会用来输出boolean,char,int,double,String,object等类型数据的重要方法:
| 方法 | 描述 |
|---|---|
| out.print(dataType dt) | 输出 Type 类型的值 |
| out.println(dataType dt) | 输出 Type 类型的值然后换行 |
| out.flush() | 刷新输出流 |
session 对象
session对象是javax.servlet.http.HttpSession类的实例。和 Java Servlets 中的session对象有一样的行为。
session对象用来跟踪在各个客户端请求间的会话。
application 对象
application对象直接包装了 servlet 的ServletContext类的对象,是javax.servlet.ServletContext类的实例。
这个对象在 JSP 页面的整个生命周期中都代表着这个 JSP 页面。这个对象在 JSP 页面初始化时被创建,随着jspDestroy()方法的调用而被移除。
通过向application中添加属性,则所有组成您 web 应用的 JSP 文件都能访问到这些属性。
config 对象
config对象是javax.servlet.ServletConfig类的实例,直接包装了 servlet 的ServletConfig类的对象。
这个对象允许开发者访问 Servlet 或者 JSP 引擎的初始化参数,比如文件路径等。
以下是 config 对象的使用方法,不是很重要,所以不常用:
1 | config.getServletName(); |
它返回包含在<servlet-name>元素中的 servlet 名字,注意,<servlet-name>元素在WEB-INF\web.xml文件中定义。
pageContext 对象
pageContext对象是javax.servlet.jsp.PageContext类的实例,用来代表整个 JSP 页面。
这个对象主要用来访问页面信息,同时过滤掉大部分实现细节。
这个对象存储了request对象和response对象的引用。application对象,config对象,session对象,out对象可以通过访问这个对象的属性来导出。
pageContext对象也包含了传给 JSP 页面的指令信息,包括缓存信息,ErrorPage URL,页面 scope 等。
PageContext类定义了一些字段,包括 PAGE_SCOPE,REQUEST_SCOPE,SESSION_SCOPE, APPLICATION_SCOPE。它也提供了 40 余种方法,有一半继承自javax.servlet.jsp.JspContext 类。
其中一个重要的方法就是removeArribute(),它可接受一个或两个参数。比如,pageContext.removeArribute(“attrName”)移除四个 scope 中相关属性,但是下面这种方法只移除特定 scope 中的相关属性:
1 | pageContext.removeAttribute("attrName", PAGE_SCOPE); |
page 对象
这个对象就是页面实例的引用。它可以被看做是整个 JSP 页面的代表。
page对象就是this对象的同义词。
exception 对象
exception对象包装了从先前页面中抛出的异常信息。它通常被用来产生对出错条件的适当响应。
EL 表达式
EL 表达式是用${}括起来的脚本,用来更方便地读取对象。EL 表达式写在 JSP 的 HTML 代码中,而不能写在<%与%>引起的 JSP 脚本中。
JSP 表达式语言(EL)使得访问存储在 JavaBean 中的数据变得非常简单。JSP EL 既可以用来创建算术表达式也可以用来创建逻辑表达式。在 JSP EL 表达式内可以使用整型数,浮点数,字符串,常量 true、false,还有 null。
一个简单的语法
典型的,当您需要在 JSP 标签中指定一个属性值时,只需要简单地使用字符串即可:
1 | <jsp:setProperty name="box" property="perimeter" value="100" /> |
JSP EL 允许您指定一个表达式来表示属性值。一个简单的表达式语法如下:
1 | {expr} |
其中,expr 指的是表达式。在 JSP EL 中通用的操作符是”.”和”[]”。这两个操作符允许您通过内嵌的 JSP 对象访问各种各样的 JavaBean 属性。
举例来说,上面的 <jsp:setProperty> 标签可以使用表达式语言改写成如下形式:
1 | <jsp:setProperty |
当 JSP 编译器在属性中见到”${}”格式后,它会产生代码来计算这个表达式,并且产生一个替代品来代替表达式的值。
您也可以在标签的模板文本中使用表达式语言。比如 <jsp:text> 标签简单地将其主体中的文本插入到 JSP 输出中:
1 | <jsp:text> |
现在,在jsp:text标签主体中使用表达式,就像这样:
1 | <jsp:text> |
在 EL 表达式中可以使用圆括号来组织子表达式。比如 ${(1 + 2) _ 3} 等于 9,但是 ${1 + (2 _ 3)} 等于 7。
想要停用对 EL 表达式的评估的话,需要使用 page 指令将 isELIgnored 属性值设为 true:
1 | <%@ page isELIgnored ="true|false" %> |
这样,EL 表达式就会被忽略。若设为 false,则容器将会计算 EL 表达式。
EL 中的基础操作符
EL 表达式支持大部分 Java 所提供的算术和逻辑操作符:
| 操作符 | 描述 |
|---|---|
| . | 访问一个 Bean 属性或者一个映射条目 |
| [] | 访问一个数组或者链表的元素 |
| ( ) | 组织一个子表达式以改变优先级 |
| + | 加 |
| - | 减或负 |
| * | 乘 |
| / or div | 除 |
| % or mod | 取模 |
| == or eq | 测试是否相等 |
| != or ne | 测试是否不等 |
| < or lt | 测试是否小于 |
| > or gt | 测试是否大于 |
| <= or le | 测试是否小于等于 |
| >= or ge | 测试是否大于等于 |
| && or and | 测试逻辑与 |
| || or or | 测试逻辑或 |
| ! or not | 测试取反 |
| empty | 测试是否空值 |
JSP EL 中的函数
JSP EL 允许您在表达式中使用函数。这些函数必须被定义在自定义标签库中。函数的使用语法如下:
1 | ${ns:func(param1, param2, ...)} |
ns 指的是命名空间(namespace),func 指的是函数的名称,param1 指的是第一个参数,param2 指的是第二个参数,以此类推。比如,有函数 fn:length,在 JSTL 库中定义,可以像下面这样来获取一个字符串的长度:
1 | ${fn:length("Get my length")} |
要使用任何标签库中的函数,您需要将这些库安装在服务器中,然后使用 <taglib> 标签在 JSP 文件中包含这些库。
JSP EL 隐含对象
JSP EL 支持下表列出的隐含对象:
| 隐含对象 | 描述 |
|---|---|
| pageScope | page 作用域 |
| requestScope | request 作用域 |
| sessionScope | session 作用域 |
| applicationScope | application 作用域 |
| param | Request 对象的参数,字符串 |
| paramValues | Request 对象的参数,字符串集合 |
| header | HTTP 信息头,字符串 |
| headerValues | HTTP 信息头,字符串集合 |
| initParam | 上下文初始化参数 |
| cookie | Cookie 值 |
| pageContext | 当前页面的 pageContext |
您可以在表达式中使用这些对象,就像使用变量一样。接下来会给出几个例子来更好的理解这个概念。
pageContext 对象
pageContext 对象是 JSP 中 pageContext 对象的引用。通过 pageContext 对象,您可以访问 request 对象。比如,访问 request 对象传入的查询字符串,就像这样:
1 | ${pageContext.request.queryString} |
Scope 对象
pageScope,requestScope,sessionScope,applicationScope 变量用来访问存储在各个作用域层次的变量。
举例来说,如果您需要显式访问在 applicationScope 层的 box 变量,可以这样来访问:applicationScope.box。
param 和 paramValues 对象
param 和 paramValues 对象用来访问参数值,通过使用 request.getParameter 方法和 request.getParameterValues 方法。
举例来说,访问一个名为 order 的参数,可以这样使用表达式:${param.order},或者${param["order"]}。
接下来的例子表明了如何访问 request 中的 username 参数:
1 | <%@ page import="java.io.*,java.util.*" %> <% String title = "Accessing Request |
param 对象返回单一的字符串,而 paramValues 对象则返回一个字符串数组。
header 和 headerValues 对象
header 和 headerValues 对象用来访问信息头,通过使用 request.getHeader 方法和 request.getHeaders 方法。
举例来说,要访问一个名为 user-agent 的信息头,可以这样使用表达式:${header.user-agent},或者 ${header["user-agent"]}。
接下来的例子表明了如何访问 user-agent 信息头:
1 | <%@ page import="java.io.*,java.util.*" %> <% String title = "User Agent |
运行结果如下:

header 对象返回单一值,而 headerValues 则返回一个字符串数组。
JSTL
JSP 标准标签库(JSTL)是一个 JSP 标签集合,它封装了 JSP 应用的通用核心功能。
JSTL 支持通用的、结构化的任务,比如迭代,条件判断,XML 文档操作,国际化标签,SQL 标签。 除了这些,它还提供了一个框架来使用集成 JSTL 的自定义标签。
根据 JSTL 标签所提供的功能,可以将其分为 5 个类别。
- 核心标签
- 格式化标签
- SQL 标签
- XML 标签
- JSTL 函数
JSTL 库安装
Apache Tomcat 安装 JSTL 库步骤如下:
从 Apache 的标准标签库中下载的二进包(jakarta-taglibs-standard-current.zip)。
- 官方下载地址:http://archive.apache.org/dist/jakarta/taglibs/standard/binaries/
- 本站下载地址:jakarta-taglibs-standard-1.1.2.zip
下载 jakarta-taglibs-standard-1.1.2.zip 包并解压,将 jakarta-taglibs-standard-1.1.2/lib/ 下的两个 jar 文件:standard.jar 和 jstl.jar 文件拷贝到 /WEB-INF/lib/ 下。
将 tld 下的需要引入的 tld 文件复制到 WEB-INF 目录下。
接下来我们在 web.xml 文件中添加以下配置:
1 |
|
使用任何库,你必须在每个 JSP 文件中的头部包含 <taglib> 标签。
核心标签
核心标签是最常用的 JSTL 标签。引用核心标签库的语法如下:
1 | <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %> |
| 标签 | 描述 |
|---|---|
<c:out> |
用于在 JSP 中显示数据,就像<%= … > |
<c:set> |
用于保存数据 |
<c:remove> |
用于删除数据 |
<c:catch> |
用来处理产生错误的异常状况,并且将错误信息储存起来 |
<c:if> |
与我们在一般程序中用的 if 一样 |
<c:choose> |
本身只当做 <c:when> 和 <c:otherwise> 的父标签 |
<c:when> |
<c:choose> 的子标签,用来判断条件是否成立 |
<c:otherwise> |
<c:choose> 的子标签,接在 <c:when> 标签后,当 <c:when> 标签判断为 false 时被执行 |
<c:import> |
检索一个绝对或相对 URL,然后将其内容暴露给页面 |
<c:forEach> |
基础迭代标签,接受多种集合类型 |
<c:forTokens> |
根据指定的分隔符来分隔内容并迭代输出 |
<c:param> |
用来给包含或重定向的页面传递参数 |
<c:redirect> |
重定向至一个新的 URL. |
<c:url> |
使用可选的查询参数来创造一个 URL |
格式化标签
JSTL 格式化标签用来格式化并输出文本、日期、时间、数字。引用格式化标签库的语法如下:
1 | <%@ taglib prefix="fmt" uri="http://java.sun.com/jsp/jstl/fmt" %> |
| 标签 | 描述 |
|---|---|
<fmt:formatNumber> |
使用指定的格式或精度格式化数字 |
<fmt:parseNumber> |
解析一个代表着数字,货币或百分比的字符串 |
<fmt:formatDate> |
使用指定的风格或模式格式化日期和时间 |
<fmt:parseDate> |
解析一个代表着日期或时间的字符串 |
<fmt:bundle> |
绑定资源 |
<fmt:setLocale> |
指定地区 |
<fmt:setBundle> |
绑定资源 |
<fmt:timeZone> |
指定时区 |
<fmt:setTimeZone> |
指定时区 |
<fmt:message> |
显示资源配置文件信息 |
<fmt:requestEncoding> |
设置 request 的字符编码 |
SQL 标签
JSTL SQL 标签库提供了与关系型数据库(Oracle,MySQL,SQL Server 等等)进行交互的标签。引用 SQL 标签库的语法如下:
1 | <%@ taglib prefix="sql" uri="http://java.sun.com/jsp/jstl/sql" %> |
| 标签 | 描述 |
|---|---|
<sql:setDataSource> |
指定数据源 |
<sql:query> |
运行 SQL 查询语句 |
<sql:update> |
运行 SQL 更新语句 |
<sql:param> |
将 SQL 语句中的参数设为指定值 |
<sql:dateParam> |
将 SQL 语句中的日期参数设为指定的 java.util.Date 对象值 |
<sql:transaction> |
在共享数据库连接中提供嵌套的数据库行为元素,将所有语句以一个事务的形式来运行 |
XML 标签
JSTL XML 标签库提供了创建和操作 XML 文档的标签。引用 XML 标签库的语法如下:
1 | <%@ taglib prefix="x" uri="http://java.sun.com/jsp/jstl/xml" %> |
在使用 xml 标签前,你必须将 XML 和 XPath 的相关包拷贝至你的 <Tomcat 安装目录>\lib 下:
XercesImpl.jar
xalan.jar
| 标签 | 描述 |
|---|---|
<x:out> |
与 <%= ... >,类似,不过只用于 XPath 表达式 |
<x:parse> |
解析 XML 数据 |
<x:set> |
设置 XPath 表达式 |
<x:if> |
判断 XPath 表达式,若为真,则执行本体中的内容,否则跳过本体 |
<x:forEach> |
迭代 XML 文档中的节点 |
<x:choose> |
<x:when> 和 <x:otherwise> 的父标签 |
<x:when> |
<x:choose> 的子标签,用来进行条件判断 |
<x:otherwise> |
<x:choose> 的子标签,当 <x:when> 判断为 false 时被执行 |
<x:transform> |
将 XSL 转换应用在 XML 文档中 |
<x:param> |
与 <x:transform> 共同使用,用于设置 XSL 样式表 |
JSTL 函数
JSTL 包含一系列标准函数,大部分是通用的字符串处理函数。引用 JSTL 函数库的语法如下:
1 | <%@ taglib prefix="fn" uri="http://java.sun.com/jsp/jstl/functions" %> |
| 函数 | 描述 |
|---|---|
| fn:contains() | 测试输入的字符串是否包含指定的子串 |
| fn:containsIgnoreCase() | 测试输入的字符串是否包含指定的子串,大小写不敏感 |
| fn:endsWith() | 测试输入的字符串是否以指定的后缀结尾 |
| fn:escapeXml() | 跳过可以作为 XML 标记的字符 |
| fn:indexOf() | 返回指定字符串在输入字符串中出现的位置 |
| fn:join() | 将数组中的元素合成一个字符串然后输出 |
| fn:length() | 返回字符串长度 |
| fn:replace() | 将输入字符串中指定的位置替换为指定的字符串然后返回 |
| fn:split() | 将字符串用指定的分隔符分隔然后组成一个子字符串数组并返回 |
| fn:startsWith() | 测试输入字符串是否以指定的前缀开始 |
| fn:substring() | 返回字符串的子集 |
| fn:substringAfter() | 返回字符串在指定子串之后的子集 |
| fn:substringBefore() | 返回字符串在指定子串之前的子集 |
| fn:toLowerCase() | 将字符串中的字符转为小写 |
| fn:toUpperCase() | 将字符串中的字符转为大写 |
| fn:trim() | 移除首尾的空白符 |
Taglib
JSP 自定义标签
自定义标签是用户定义的 JSP 语言元素。当 JSP 页面包含一个自定义标签时将被转化为 servlet,标签转化为对被 称为 tag handler 的对象的操作,即当 servlet 执行时 Web container 调用那些操作。
JSP 标签扩展可以让你创建新的标签并且可以直接插入到一个 JSP 页面。 JSP 2.0 规范中引入 Simple Tag Handlers 来编写这些自定义标记。
你可以继承 SimpleTagSupport 类并重写的 doTag()方法来开发一个最简单的自定义标签。
创建”Hello”标签
接下来,我们想创建一个自定义标签叫作ex:Hello,标签格式为:
1 | <ex:Hello /> |
要创建自定义的 JSP 标签,你首先必须创建处理标签的 Java 类。所以,让我们创建一个 HelloTag 类,如下所示:
1 | package com.runoob; import javax.servlet.jsp.tagext.*; import |
以下代码重写了 doTag()方法,方法中使用了 getJspContext()方法来获取当前的 JspContext 对象,并将”Hello Custom Tag!”传递给 JspWriter 对象。
编译以上类,并将其复制到环境变量 CLASSPATH 目录中。最后创建如下标签库:<Tomcat安装目录>webapps\ROOT\WEB-INF\custom.tld。
1 | <taglib> |
接下来,我们就可以在 JSP 文件中使用 Hello 标签:
1 | <%@ taglib prefix="ex" uri="WEB-INF/custom.tld"%> |
以上程序输出结果为:
1 | Hello Custom Tag! |
访问标签体
你可以像标准标签库一样在标签中包含消息内容。如我们要在我们自定义的 Hello 中包含内容,格式如下:
1 | <ex:Hello> |
我们可以修改标签处理类文件,代码如下:
1 | package com.runoob; |
接下来我们需要修改 TLD 文件,如下所示:
1 | <taglib> |
现在我们可以在 JSP 使用修改后的标签,如下所示:
1 | <%@ taglib prefix="ex" uri="WEB-INF/custom.tld"%> |
以上程序输出结果如下所示:
1 | This is message body |
自定义标签属性
你可以在自定义标准中设置各种属性,要接收属性,值自定义标签类必须实现 setter 方法, JavaBean 中的 setter 方法如下所示:
1 | package com.runoob; |
属性的名称是”message”,所以 setter 方法是的 setMessage()。现在让我们在 TLD 文件中使用的 <attribute> 元素添加此属性:
1 | <taglib> |
现在我们就可以在 JSP 文件中使用 message 属性了,如下所示:
1 | <%@ taglib prefix="ex" uri="WEB-INF/custom.tld"%> |
以上实例数据输出结果为:
1 | This is custom |
你还可以包含以下属性:
| 属性 | 描述 |
|---|---|
| name | 定义属性的名称。每个标签的是属性名称必须是唯一的。 |
| required | 指定属性是否是必须的或者可选的,如果设置为 false 为可选。 |
| rtexprvalue | 声明在运行表达式时,标签属性是否有效。 |
| type | 定义该属性的 Java 类类型 。默认指定为 String |
| description | 描述信息 |
| fragment | 如果声明了该属性,属性值将被视为一个 JspFragment。 |
以下是指定相关的属性实例:
1 | ..... |
如果你使用了两个属性,修改 TLD 文件,如下所示:
1 | ..... |