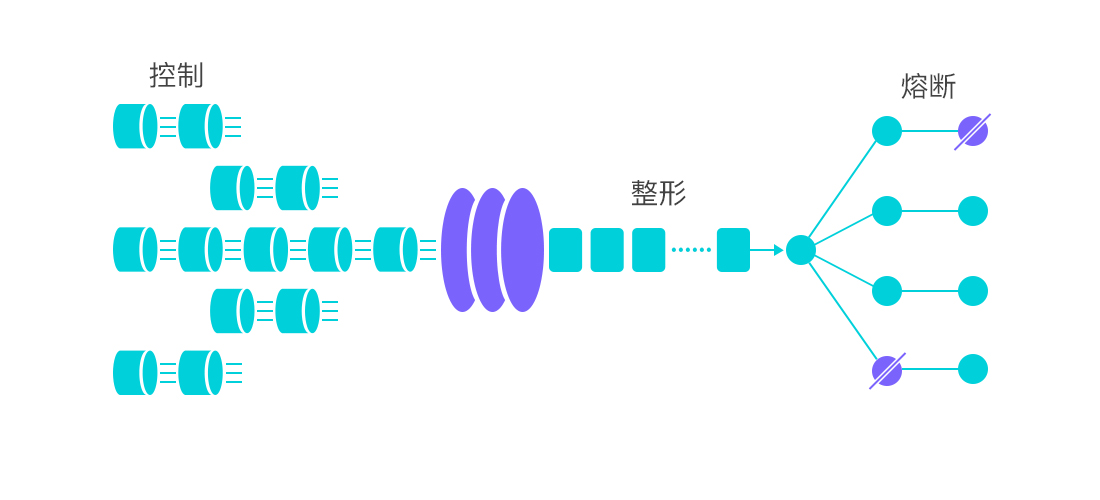
Sentinel 快速入门 Sentinel 简介 Sentinel 是面向分布式、多语言异构化服务架构的流量治理组件,主要以流量为切入点,从流量控制、流量路由、熔断降级、系统自适应保护等多个维度来帮助用户保障微服务的稳定性。
Sentinel 中有两个基本概念:
资源 :资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。只要通过 Sentinel API 定义的代码(即资源),就可以被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。
规则 :围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。
Sentinel 的主要工作机制如下:
对主流框架提供适配或者显示的 API,来定义需要保护的资源,并提供设施对资源进行实时统计和调用链路分析。
根据预设的规则,结合对资源的实时统计信息,对流量进行控制。同时,Sentinel 提供开放的接口,方便您定义及改变规则。
Sentinel 提供实时的监控系统,方便您快速了解目前系统的状态。
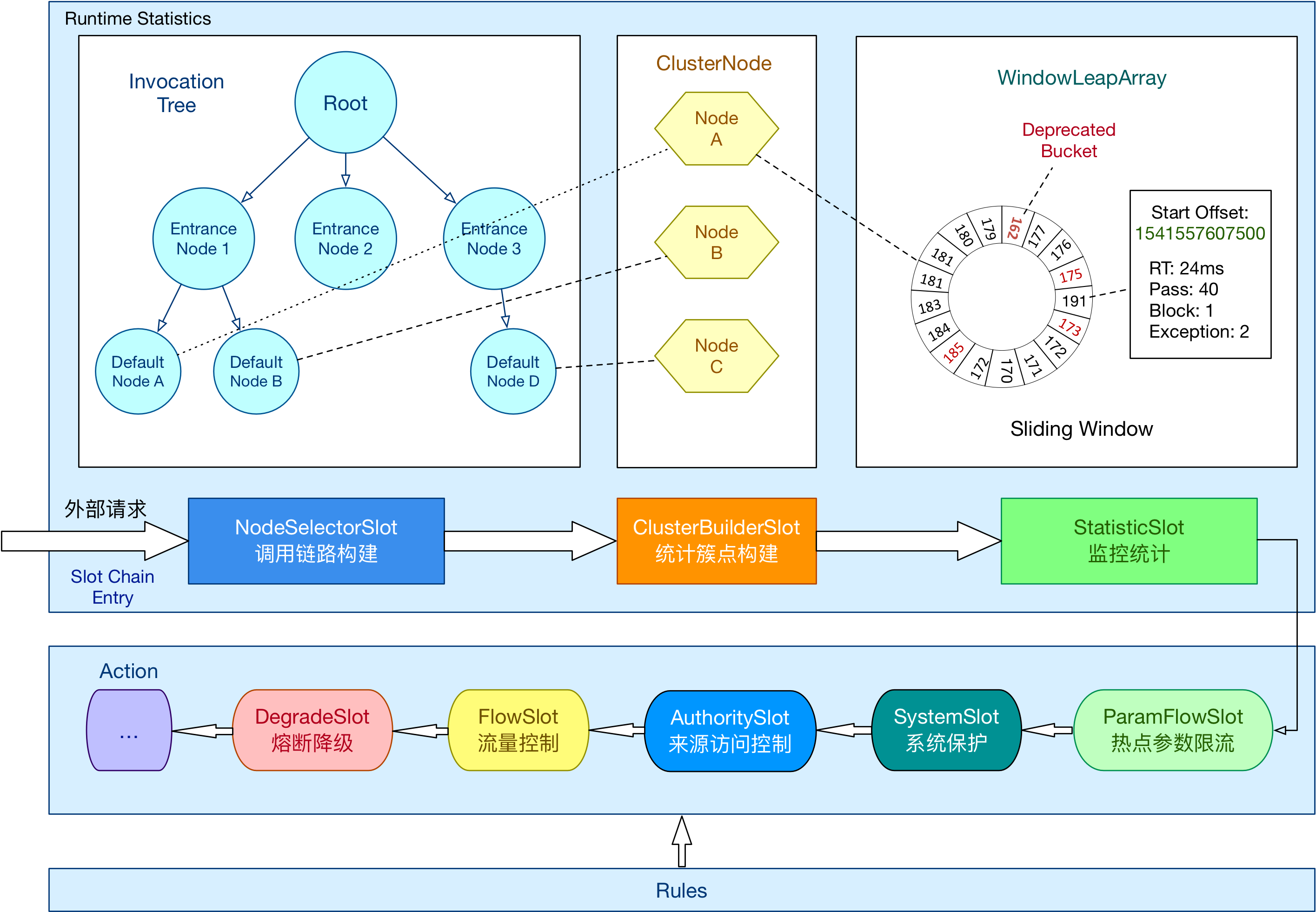
Sentinel 基本原理 在 Sentinel 中,任意资源都对应一个资源名称以及一个 Entry 对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 API 显式创建;每一个 Entry 创建的时候,同时也会创建一条检查链(slot chain)。
Sentinel 会采用职责链模式,依次处理链上的各个插槽。这个链路大致会执行下列操作:
采用滑动时间窗口算法统计当前流量;
依次使用多种限流熔断规则进行流量判断,一旦判定当前流量超出规则中设置的阈值时,即触发限流或熔断,抛出 BlockException 异常;
业务侧根据 BlockException 进行回调处理。
总体的框架如下:
大致介绍一下 Sentinel 的核心插槽:
NodeSelectorSlot 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;ClusterBuilderSlot 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;StatisticSlot 则用于记录、统计不同纬度的 runtime 指标监控信息;FlowSlot 则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;AuthoritySlot 则根据配置的黑白名单和调用来源信息,来做黑白名单控制;DegradeSlot 则通过统计信息以及预设的规则,来做熔断降级;SystemSlot 则通过系统的状态,例如 load1 等,来控制总的入口流量;
除此以外,Sentinel 也支持通过 SPI 技术来自定义规则,用户可以自行加入自定义的 slot 并编排 slot 间的顺序。需要注意的是:
1.7.2 版本以前用 SlotChainBuilder 作为 SPI
1.7.2 版本以后用 ProcessorSlot 作为 SPI
下面将逐一详细讲解各插槽的用法。
NodeSelectorSlot 这个 slot 主要负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级。
1 2 3 4 5 6 ContextUtil.enter("entrance1" , "appA" ); Entry nodeA = SphU.entry("nodeA" );if (nodeA != null ) { nodeA.exit(); } ContextUtil.exit();
上述代码通过 ContextUtil.enter() 创建了一个名为 entrance1 的上下文,同时指定调用发起者为 appA;接着通过 SphU.entry()请求一个 token,如果该方法顺利执行没有抛 BlockException,表明 token 请求成功。
以上代码将在内存中生成以下结构:
1 2 3 4 5 6 7 machine-root / / EntranceNode1 / / DefaultNode(nodeA)
注意:每个 DefaultNode 由资源 ID 和输入名称来标识。换句话说,一个资源 ID 可以有多个不同入口的 DefaultNode。
1 2 3 4 5 6 7 8 9 10 11 12 13 ContextUtil.enter("entrance1" , "appA" ); Entry nodeA = SphU.entry("nodeA" );if (nodeA != null ) { nodeA.exit(); } ContextUtil.exit(); ContextUtil.enter("entrance2" , "appA" ); nodeA = SphU.entry("nodeA" ); if (nodeA != null ) { nodeA.exit(); } ContextUtil.exit();
以上代码将在内存中生成以下结构:
1 2 3 4 5 6 7 machine-root / \ / \ EntranceNode1 EntranceNode2 / \ / \ DefaultNode(nodeA) DefaultNode(nodeA)
上面的结构可以通过调用 curl http://localhost:8719/tree?type=root 来显示:
1 2 3 4 5 6 7 EntranceNode: machine-root (t :0 pq :1 bq :0 tq :1 rt :0 prq :1 1 mp :0 1 mb :0 1 mt :0 ) -EntranceNode1: Entrance1 (t :0 pq :1 bq :0 tq :1 rt :0 prq :1 1 mp :0 1 mb :0 1 mt :0 ) --nodeA (t :0 pq :1 bq :0 tq :1 rt :0 prq :1 1 mp :0 1 mb :0 1 mt :0 ) -EntranceNode2: Entrance1 (t :0 pq :1 bq :0 tq :1 rt :0 prq :1 1 mp :0 1 mb :0 1 mt :0 ) --nodeA (t :0 pq :1 bq :0 tq :1 rt :0 prq :1 1 mp :0 1 mb :0 1 mt :0 ) t:threadNum pq:passQps bq:blockedQps tq:totalQps rt:averageRt prq: passRequestQps 1 mp:1 m-passed 1 mb:1 m-blocked 1 mt:1 m-total
ClusterBuilderSlot 此插槽用于构建资源的 ClusterNode 以及调用来源节点。ClusterNode 保持资源运行统计信息(响应时间、QPS、block 数目、线程数、异常数等)以及原始调用者统计信息列表。来源调用者的名字由 ContextUtil.enter(contextName,origin) 中的 origin 标记。可通过如下命令查看某个资源不同调用者的访问情况:curl http://localhost:8719/origin?id=caller:
1 2 3 4 id : nodeAidx origin threadNum passedQps blockedQps totalQps aRt 1 m-passed 1 m-blocked 1 m-total1 caller1 0 0 0 0 0 0 0 0 2 caller2 0 0 0 0 0 0 0 0
StatisticSlot StatisticSlot 是 Sentinel 的核心功能插槽之一,用于统计实时的调用数据。
clusterNode:资源唯一标识的 ClusterNode 的 runtime 统计origin:根据来自不同调用者的统计信息defaultnode: 根据上下文条目名称和资源 ID 的 runtime 统计入口的统计
Sentinel 底层采用高性能的滑动窗口数据结构 LeapArray 来统计实时的秒级指标数据,可以很好地支撑写多于读的高并发场景。
AuthoritySlot SystemSlot 这个 slot 会根据当前系统的整体情况,对入口资源的调用进行动态调配。其原理是让入口的流量和当前系统的预计容量达到一个动态平衡。
注意系统规则只对入口流量起作用(调用类型为 EntryType.IN),对出口流量无效。可通过 SphU.entry(res, entryType) 指定调用类型,如果不指定,默认是EntryType.OUT。
ParamFlowSlot FlowSlot 这个 slot 主要根据预设的资源的统计信息,按照固定的次序,依次生效。如果一个资源对应两条或者多条流控规则,则会根据如下次序依次检验,直到全部通过或者有一个规则生效为止:
指定应用生效的规则,即针对调用方限流的;
调用方为 other 的规则;
调用方为 default 的规则。
DegradeSlot 这个 slot 主要针对资源的平均响应时间(RT)以及异常比率,来决定资源是否在接下来的时间被自动熔断掉。
Sentinel 基本使用 参考:Sentinel 官方文档之快速开始
使用 Sentinel 来进行资源保护,主要分为几个步骤:
定义资源
定义规则
检验规则是否生效
Sentinel 支持 5 种定义资源方式:
主流框架的默认适配 抛出异常的方式定义资源 - SphU 包含了 try-catch 风格的 API。返回布尔值方式定义资源 - SphO 提供 if-else 风格的 API。注解方式定义资源 @SentinelResource 注解定义资源并配置 blockHandler 和 fallback 函数来进行限流之后的处理。异步调用支持 - Sentinel 支持通过 SphU.asyncEntry(xxx) 方法定义资源,并通常需要在异步的回调函数中调用 exit 方法。
Sentinel 支持以下几种规则:
流量控制规则 (FlowRule) 熔断降级规则 (DegradeRule) 系统保护规则 (SystemRule) 来源访问控制规则 (AuthorityRule) origin)限制资源是否通过,若配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过。热点参数规则 (ParamFlowRule)
Sentinel 流量控制 FlowSlot 会根据预设的规则,结合前面 NodeSelectorSlot、ClusterNodeBuilderSlot、StatistcSlot 统计出来的实时信息进行流量控制。
限流的直接表现是在执行 Entry nodeA = SphU.entry(资源名字) 的时候抛出 FlowException 异常。FlowException 是 BlockException 的子类,您可以捕捉 BlockException 来自定义被限流之后的处理逻辑。
同一个资源可以对应多条限流规则。FlowSlot 会对该资源的所有限流规则依次遍历,直到有规则触发限流或者所有规则遍历完毕。
一条限流规则主要由下面几个因素组成,我们可以组合这些元素来实现不同的限流效果:
resource - 资源名,即限流规则的作用对象count - 限流阈值grade - 限流阈值类型,QPS 或线程数strategy - 根据调用关系选择策略
基于 QPS/并发数的流量控制 流量控制主要有两种统计类型,一种是统计线程数,另外一种则是统计 QPS。
线程数限流用于保护业务线程数不被耗尽 。例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对高线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离),或者使用信号量来控制同时请求的个数(信号量隔离)。这种隔离方案虽然能够控制线程数量,但无法控制请求排队时间。当请求过多时排队也是无益的,直接拒绝能够迅速降低系统压力。Sentinel 线程数限流不负责创建和管理线程池,而是简单统计当前请求上下文的线程个数,如果超出阈值,新的请求会被立即拒绝。
当 QPS 超过某个阈值的时候,则采取措施进行流量控制。流量控制的手段包括下面 3 种,对应 FlowRule 中的 controlBehavior 字段:
直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式。该方式是默认的流量控制方式,当 QPS 超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。具体的例子参见 FlowqpsDemo 。
冷启动(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式。该方式主要用于系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过”冷启动”,让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮的情况。具体的例子参见 WarmUpFlowDemo 。
匀速器(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式。这种方式严格控制了请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。具体的例子参见 PaceFlowDemo 。
基于调用关系的流量控制 调用关系包括调用方、被调用方;方法又可能会调用其它方法,形成一个调用链路的层次关系。Sentinel 通过 NodeSelectorSlot 建立不同资源间的调用的关系,并且通过 ClusterNodeBuilderSlot 记录每个资源的实时统计信息。
有了调用链路的统计信息,我们可以衍生出多种流量控制手段。
根据调用方限流 ContextUtil.enter(resourceName, origin) 方法中的 origin 参数标明了调用方身份。这些信息会在 ClusterBuilderSlot 中被统计。
限流规则中的 limitApp 字段用于根据调用方进行流量控制。该字段的值有以下三种选项,分别对应不同的场景:
default:表示不区分调用者,来自任何调用者的请求都将进行限流统计。如果这个资源名的调用总和超过了这条规则定义的阈值,则触发限流。{some_origin_name}:表示针对特定的调用者,只有来自这个调用者的请求才会进行流量控制。例如 NodeA 配置了一条针对调用者caller1的规则,那么当且仅当来自 caller1 对 NodeA 的请求才会触发流量控制。other:表示针对除 {some_origin_name} 以外的其余调用方的流量进行流量控制。例如,资源NodeA配置了一条针对调用者 caller1 的限流规则,同时又配置了一条调用者为 other 的规则,那么任意来自非 caller1 对 NodeA 的调用,都不能超过 other 这条规则定义的阈值。
同一个资源名可以配置多条规则,规则的生效顺序为:**{some_origin_name} > other > default**
根据调用链路入口限流:链路限流 NodeSelectorSlot 中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树。这棵树的根节点是一个名字为 machine-root 的虚拟节点,调用链的入口都是这个虚节点的子节点。
一棵典型的调用树如下图所示:
1 2 3 4 5 6 7 machine-root / \ / \ Entrance1 Entrance2 / \ / \ DefaultNode(nodeA) DefaultNode(nodeA)
上图中来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA,Sentinel 允许只根据某个入口的统计信息对资源限流。比如我们可以设置 FlowRule.strategy 为 RuleConstant.CHAIN,同时设置 FlowRule.ref_identity 为 Entrance1 来表示只有从入口 Entrance1 的调用才会记录到 NodeA 的限流统计当中,而对来自 Entrance2 的调用漠不关心。
调用链的入口是通过 API 方法 ContextUtil.enter(name) 定义的。
具有关系的资源流量控制:关联流量控制 当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢,举例来说,read_db 和 write_db 这两个资源分别代表数据库读写,我们可以给 read_db 设置限流规则来达到写优先的目的:设置 FlowRule.strategy 为 RuleConstant.RELATE 同时设置 FlowRule.ref_identity 为 write_db。这样当写库操作过于频繁时,读数据的请求会被限流。
Sentinel 熔断降级 除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。
Sentinel 提供以下几种熔断策略:
慢调用比例 (SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
异常比例 (ERROR_RATIO):当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
异常数 (ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
注意异常降级仅针对业务异常 ,对 Sentinel 限流降级本身的异常(BlockException)不生效。为了统计异常比例或异常数,需要通过 Tracer.trace(ex) 记录业务异常。示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Entry entry = null ;try { entry = SphU.entry(resource); } catch (Throwable t) { if (!BlockException.isBlockException(t)) { Tracer.trace(t); } } finally { if (entry != null ) { entry.exit(); } }
开源整合模块,如 Sentinel Dubbo Adapter, Sentinel Web Servlet Filter 或 @SentinelResource 注解会自动统计业务异常,无需手动调用。
Sentinel 支持注册自定义的事件监听器监听熔断器状态变换事件(state change event)。示例:
1 2 3 4 5 6 7 8 9 10 11 EventObserverRegistry.getInstance().addStateChangeObserver("logging" , (prevState, newState, rule, snapshotValue) -> { if (newState == State.OPEN) { System.err.println(String.format("%s -> OPEN at %d, snapshotValue=%.2f" , prevState.name(), TimeUtil.currentTimeMillis(), snapshotValue)); } else { System.err.println(String.format("%s -> %s at %d" , prevState.name(), newState.name(), TimeUtil.currentTimeMillis())); } });
Sentinel 系统自适应保护 Sentinel 系统自适应保护从整体维度对应用入口流量进行控制,结合应用的 Load、总体平均 RT、入口 QPS 和线程数等几个维度的监控指标,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
Sentinel 做系统自适应保护的目的:
保证系统不被拖垮
在系统稳定的前提下,保持系统的吞吐量
Sentinel 的设计理念是,根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。Sentinel 在系统自适应保护的实际做法是,用系统负载作为启动控制流量的值,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
系统保护规则是从应用级别的入口流量进行控制,从单台机器的总体 Load、RT、入口 QPS 和线程数四个维度监控应用数据,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效 。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
系统规则支持以下的阈值类型:
Load (仅对 Linux/Unix-like 机器生效):当系统 load1 超过阈值,且系统当前的并发线程数超过系统容量时才会触发系统保护。系统容量由系统的 maxQps * minRt 计算得出。设定参考值一般是 CPU cores * 2.5。CPU usage (1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0)。RT :当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。线程数 :当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。入口 QPS :当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
注:这种系统自适应算法对于低 load 的请求,它的效果是一个“兜底”的角色。对于不是应用本身造成的 load 高的情况(如其它进程导致的不稳定的情况),效果不明显。
Sentinel 集群流量控制 集群流量控制简介 集群流控可以精确地控制整个集群的调用总量,结合单机限流兜底,可以更好地发挥流量控制的效果。
集群流控中共有两种身份:
Token Client:集群流控客户端,用于向所属 Token Server 通信请求 token。集群限流服务端会返回给客户端结果,决定是否限流。
Token Server:即集群流控服务端,处理来自 Token Client 的请求,根据配置的集群规则判断是否应该发放 token(是否允许通过)。
Sentinel 1.4.0 开始引入了集群流控模块,主要包含以下几部分:
sentinel-cluster-common-default: 公共模块,包含公共接口和实体sentinel-cluster-client-default: 默认集群流控 client 模块,使用 Netty 进行通信,提供接口方便序列化协议扩展sentinel-cluster-server-default: 默认集群流控 server 模块,使用 Netty 进行通信,提供接口方便序列化协议扩展;同时提供扩展接口对接规则判断的具体实现(TokenService),默认实现是复用 sentinel-core 的相关逻辑
集群流量控制规则 FlowRule 添加了两个字段用于集群限流相关配置:
1 2 private boolean clusterMode; private ClusterFlowConfig clusterConfig;
其中 用一个专门的 ClusterFlowConfig 代表集群限流相关配置项,以与现有规则配置项分开:
1 2 3 4 5 6 7 8 9 10 private Long flowId;private int thresholdType = ClusterRuleConstant.FLOW_THRESHOLD_AVG_LOCAL;private int strategy = ClusterRuleConstant.FLOW_CLUSTER_STRATEGY_NORMAL;private boolean fallbackToLocalWhenFail = true ;
flowId 代表全局唯一的规则 ID,Sentinel 集群限流服务端通过此 ID 来区分各个规则,因此务必保持全局唯一 。一般 flowId 由统一的管控端进行分配,或写入至 DB 时生成。thresholdType 代表集群限流阈值模式。其中单机均摊模式 下配置的阈值等同于单机能够承受的限额,token server 会根据客户端对应的 namespace(默认为 project.name 定义的应用名)下的连接数来计算总的阈值(比如独立模式下有 3 个 client 连接到了 token server,然后配的单机均摊阈值为 10,则计算出的集群总量就为 30);而全局模式下配置的阈值等同于整个集群的总阈值 。
ParamFlowRule 热点参数限流相关的集群配置与 FlowRule 相似。
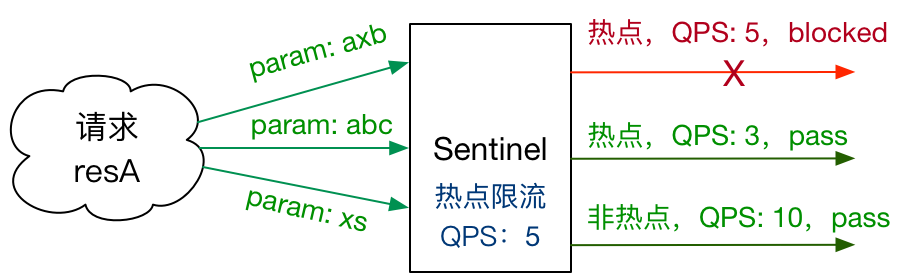
Sentinel 热点参数限流 热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。
要使用热点参数限流功能,需要引入以下依赖:
1 2 3 4 5 <dependency > <groupId > com.alibaba.csp</groupId > <artifactId > sentinel-parameter-flow-control</artifactId > <version > x.y.z</version > </dependency >
然后为对应的资源配置热点参数限流规则,并在 entry 的时候传入相应的参数,即可使热点参数限流生效。
注:若自行扩展并注册了自己实现的 SlotChainBuilder,并希望使用热点参数限流功能,则可以在 chain 里面合适的地方插入 ParamFlowSlot。
那么如何传入对应的参数以便 Sentinel 统计呢?我们可以通过 SphU 类里面几个 entry 重载方法来传入:
1 2 3 public static Entry entry (String name, EntryType type, int count, Object... args) throws BlockExceptionpublic static Entry entry (Method method, EntryType type, int count, Object... args) throws BlockException
其中最后的一串 args 就是要传入的参数,有多个就按照次序依次传入。比如要传入两个参数 paramA 和 paramB,则可以:
1 2 3 SphU.entry(resourceName, EntryType.IN, 1 , paramA, paramB);
注意 :若 entry 的时候传入了热点参数,那么 exit 的时候也一定要带上对应的参数(exit(count, args)),否则可能会有统计错误。正确的示例:
1 2 3 4 5 6 7 8 9 10 11 Entry entry = null ;try { entry = SphU.entry(resourceName, EntryType.IN, 1 , paramA, paramB); } catch (BlockException ex) { } finally { if (entry != null ) { entry.exit(1 , paramA, paramB); } }
对于 @SentinelResource 注解方式定义的资源,若注解作用的方法上有参数,Sentinel 会将它们作为参数传入 SphU.entry(res, args)。比如以下的方法里面 uid 和 type 会分别作为第一个和第二个参数传入 Sentinel API,从而可以用于热点规则判断:
1 2 3 4 @SentinelResource("myMethod") public Result doSomething (String uid, int type) { }
来源访问控制(黑白名单) 很多时候,我们需要根据调用方来限制资源是否通过,这时候可以使用 Sentinel 的黑白名单控制的功能。黑白名单根据资源的请求来源(origin)限制资源是否通过,若配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过。
调用方信息通过 ContextUtil.enter(resourceName, origin) 方法中的 origin 参数传入。
黑白名单规则(AuthorityRule)非常简单,主要有以下配置项:
resource:资源名,即限流规则的作用对象limitApp:对应的黑名单/白名单,不同 origin 用 , 分隔,如 appA,appBstrategy:限制模式,AUTHORITY_WHITE 为白名单模式,AUTHORITY_BLACK 为黑名单模式,默认为白名单模式
注解埋点支持 Sentinel 提供了 @SentinelResource 注解用于定义资源,并提供了 AspectJ 的扩展用于自动定义资源、处理 BlockException 等。使用 Sentinel Annotation AspectJ Extension 的时候需要引入以下依赖:
1 2 3 4 5 <dependency > <groupId > com.alibaba.csp</groupId > <artifactId > sentinel-annotation-aspectj</artifactId > <version > x.y.z</version > </dependency >
@SentinelResource 用于定义资源,并提供可选的异常处理和 fallback 配置项。 特别地,若 blockHandler 和 fallback 都进行了配置,则被限流降级而抛出 BlockException 时只会进入 blockHandler 处理逻辑。若未配置 blockHandler、fallback 和 defaultFallback,则被限流降级时会将 BlockException 直接抛出 。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class TestService { @SentinelResource(value = "test", blockHandler = "handleException", blockHandlerClass = {ExceptionUtil.class}) public void test () { System.out.println("Test" ); } @SentinelResource(value = "hello", blockHandler = "exceptionHandler", fallback = "helloFallback") public String hello (long s) { return String.format("Hello at %d" , s); } public String helloFallback (long s) { return String.format("Halooooo %d" , s); } public String exceptionHandler (long s, BlockException ex) { ex.printStackTrace(); return "Oops, error occurred at " + s; } }
动态规则扩展 Sentinel 提供两种方式修改规则:
通过 API 直接修改 (loadRules)
通过 DataSource 适配不同数据源修改
通过 API 修改比较直观,可以通过以下几个 API 修改不同的规则:
1 2 FlowRuleManager.loadRules(List<FlowRule> rules); DegradeRuleManager.loadRules(List<DegradeRule> rules);
手动修改规则(硬编码方式)一般仅用于测试和演示,生产上一般通过动态规则源的方式来动态管理规则。
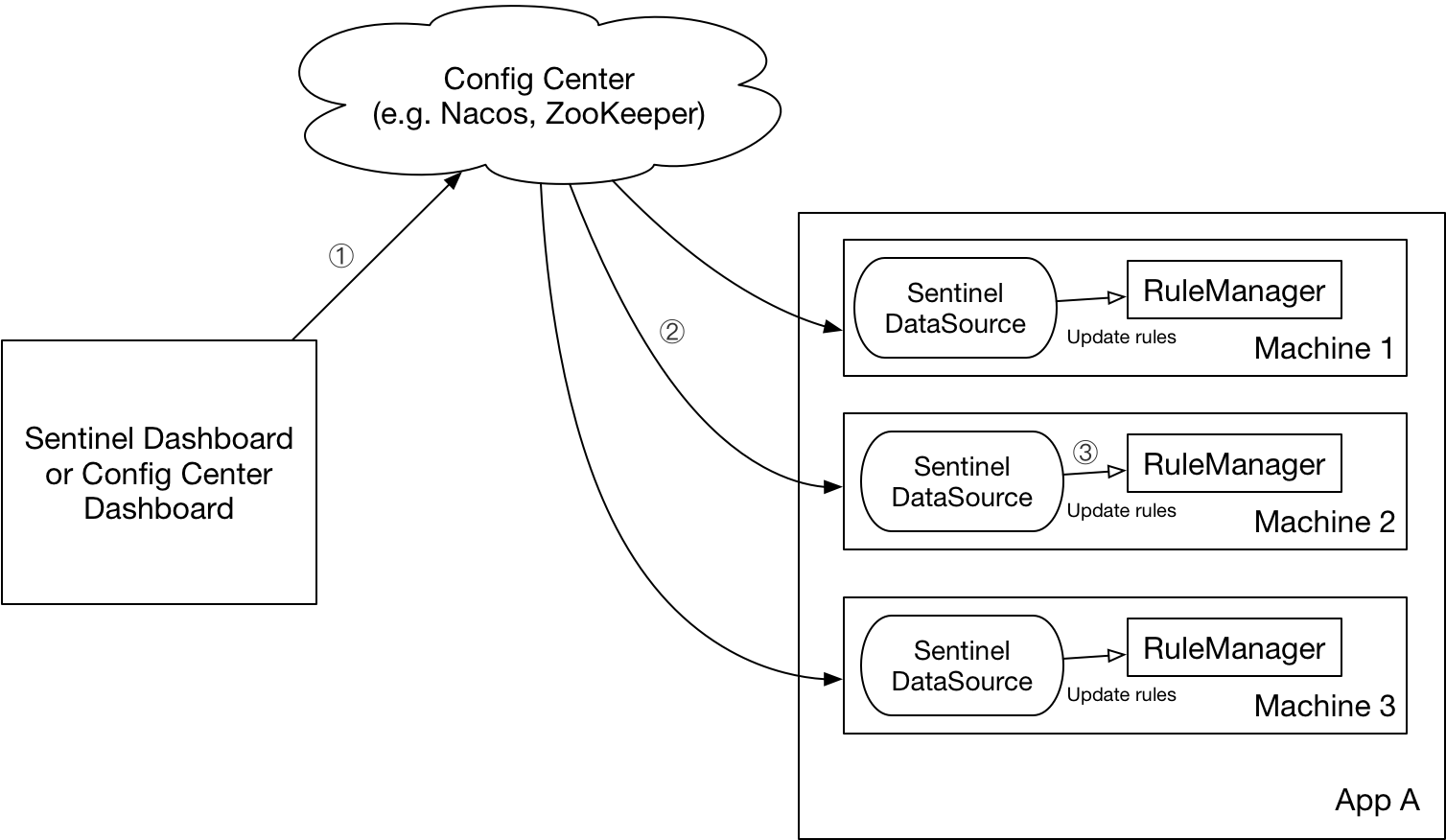
上述 loadRules() 方法只接受内存态的规则对象,但更多时候规则存储在文件、数据库或者配置中心当中。DataSource 接口给我们提供了对接任意配置源的能力。相比直接通过 API 修改规则,实现 DataSource 接口是更加可靠的做法。
我们推荐通过控制台设置规则后将规则推送到统一的规则中心,客户端实现 ReadableDataSource 接口端监听规则中心实时获取变更 ,流程如下:
DataSource 扩展常见的实现方式有:
拉模式 :客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是 RDBMS、文件,甚至是 VCS 等。这样做的方式是简单,缺点是无法及时获取变更;推模式 :规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用 Nacos 、Zookeeper 等配置中心。这种方式有更好的实时性和一致性保证。
Sentinel 目前支持以下数据源扩展:
流量治理标准数据源:OpenSergo
拉模式扩展 实现拉模式的数据源最简单的方式是继承 AutoRefreshDataSourcereadSource() 方法,在该方法里从指定数据源读取字符串格式的配置数据。比如 基于文件的数据源 。
推模式扩展 实现推模式的数据源最简单的方式是继承 AbstractDataSourcereadSource() 从指定数据源读取字符串格式的配置数据。比如 基于 Nacos 的数据源 。
注册数据源 通常需要调用以下方法将数据源注册至指定的规则管理器中:
1 2 ReadableDataSource<String, List<FlowRule>> flowRuleDataSource = new NacosDataSource <>(remoteAddress, groupId, dataId, parser); FlowRuleManager.register2Property(flowRuleDataSource.getProperty());
若不希望手动注册数据源,可以借助 Sentinel 的 InitFunc SPI 扩展接口。只需要实现自己的 InitFunc 接口,在 init 方法中编写注册数据源的逻辑。比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.test.init;public class DataSourceInitFunc implements InitFunc { @Override public void init () throws Exception { final String remoteAddress = "localhost" ; final String groupId = "Sentinel:Demo" ; final String dataId = "com.alibaba.csp.sentinel.demo.flow.rule" ; ReadableDataSource<String, List<FlowRule>> flowRuleDataSource = new NacosDataSource <>(remoteAddress, groupId, dataId, source -> JSON.parseObject(source, new TypeReference <List<FlowRule>>() {})); FlowRuleManager.register2Property(flowRuleDataSource.getProperty()); } }
接着将对应的类名添加到位于资源目录(通常是 resource 目录)下的 META-INF/services 目录下的 com.alibaba.csp.sentinel.init.InitFunc 文件中,比如:
1 com.test .init .DataSourceInitFunc
这样,当初次访问任意资源的时候,Sentinel 就可以自动去注册对应的数据源了。
常见问题 为什么有时候限流不是完全精准 滑动时间窗是在固定时间窗算法基础上增加了样本数配置,支持按需配置时间片。sentinel 默认 1 秒两个样本,即 500ms 为一个时间窗口。样本数越多,计算越精确,但性能损耗更多。选择 500ms 是一个性能与精确统计的折中值。对于限流场景来说,性能可能比统计准确更重要,所以 sentinel 不是完全精准按照配置的阈值来限流,当然也不会相差很多。这是为了保证业务服务的高性能,减少限流组件对业务服务的性能影响。
参考资料