分布式分区
分布式分区
在不同系统中,分区有着不同的称呼,例如它对应于 MongoDB, Elasticsearch 和 SolrCloud 中的 shard, HBase 的 region, Bigtable 中的
tablet, Cassandra 和 Riak 中的 vnode ,以及 Couch base 中的 vBucket。总体而言,分区是最普遍的术语。分区通常是这样定义的,即每一条数据(或者每条记录,每行或每个文档)只属于某个特定分区。实际上,每个分区都可以视为一个完整的小型数据库,虽然数据库可能存在一些跨分区的操作。
采用数据分区的主要目的是提高可扩展性。不同的分区可以放在一个无共享集群的不同节点上,这样一个大数据集可以分散在更多的磁盘上,查询负载也随之分布到更多的处理器上。
对单个分区进行查询时,每个节点对自己所在分区可以独立执行查询操作,因此添加更多的节点可以提高查询吞吐量。超大而复杂的查询尽管比较困难,但也可能做到跨节点的并行处理。
数据分区与数据复制
分区通常与复制结合使用,即每个分区在多个节点都存有副本。这意味着某条记录属于特定的分区,而同样的内容会保存在不同的节点上以提高系统的容错性。
一个节点上可能存储了多个分区。每个分区都有自己的主副本,例如被分配给某节点,而从副本则分配在其他一些节点。一个节点可能既是某些分区的主副本,同时又是其他分区的从副本。
键-值数据的分区
分区的主要目标是将数据和查询负载均匀分布在所有节点上。如果节点平均分担负载,那么理论上 10 个节点应该能够处理 10 倍的数据量和 10 倍于单个节点的读写吞吐量(忽略复制) 。
而如果分区不均匀,则会出现某些分区节点比其他分区承担更多的数据量或查询负载,称之为倾斜。倾斜会导致分区效率严重下降,在极端情况下,所有的负载可能会集中在一个分区节点上,这就意味着 10 个节点 9 个空闲,系统的瓶颈在最繁忙的那个节点上。这种负载严重不成比例的分区即成为系统热点。
基于关键字区间分区
一种分区方式是为每个分区分配一段连续的关键字或者关键宇区间范围(以最小值和最大值来指示)。
关键字的区间段不一定非要均匀分布,这主要是因为数据本身可能就不均匀。
每个分区内可以按照关键字排序保存(参阅第 3 章的“ SSTables 和 LSM Trees ”)。这样可以轻松支持区间查询,即将关键字作为一个拼接起来的索引项从而一次查询得到多个相关记录。
然而,基于关键字的区间分区的缺点是某些访问模式会导致热点。如果关键字是时间戳,则分区对应于一个时间范围,所有的写入操作都集中在同一个分区(即当天的分区),这会导致该分区在写入时负载过高,而其他分区始终处于空闲状态。为了避免上述问题,需要使用时间戳以外的其他内容作为关键字的第一项。
基于关键字晗希值分区
一且找到合适的关键宇 H 合希函数,就可以为每个分区分配一个哈希范围(而不是直接作用于关键宇范围),关键字根据其哈希值的范围划分到不同的分区中。

这种方总可以很好地将关键字均匀地分配到多个分区中。分区边界可以是均匀间隔,也可以是伪随机选择( 在这种情况下,该技术有时被称为一致性哈希) 。
然而,通过关键宇 II 合希进行分区,我们丧失了良好的区间查询特性。即使关键字相邻,但经过哈希之后会分散在不同的分区中,区间查询就失去了原有的有序相邻的特性。
负载倾斜与热点
基于哈希的分区方能可以减轻热点,但无住做到完全避免。一个极端情况是,所有的读/写操作都是针对同一个关键字,则最终所有请求都将被路由到同一个分区。
一个简单的技术就是在关键字的开头或结尾处添加一个随机数。只需一个两位数的十进制随机数就可以将关键字的写操作分布到 100 个不同的关键字上,从而分配到不同的分区上。但是,随之而来的问题是,之后的任何读取都需要些额外的工作,必须从所有 100 个关键字中读取数据然后进行合井。因此通常只对少量的热点关键字附加随机数才有意义。
分区与二级索引
二级索引通常不能唯一标识一条记录,而是用来加速特定值的查询。
二级索引带来的主要挑战是它们不能规整的地映射到分区中。有两种主要的方法来支持对二级索引进行分区:基于文档的分区和基于词条的分区。
基于文档分区的二级索引
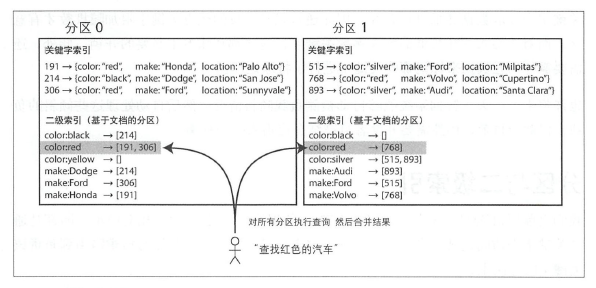
在这种索引方法中,每个分区完全独立,各自维护自己的二级索引,且只负责自己分区内的文档而不关心其他分区中数据。每当需要写数据库时,包括添加,删除或更新文档等,只需要处理包含目标文档 ID 的那一个分区。因此文档分区索引也被称为本地索引,而不是全局索引。
这种查询分区数据库的方陆有时也称为分散/聚集,显然这种二级索引的查询代价高昂。即使采用了并行查询,也容易导致读延迟显著放大。尽管如此,它还是广泛用于实践: MongoDB 、Riak、Cassandra、Elasticsearch 、SolrCloud 和 VoltDB 都支持基于文档分区二级索引。
基于词条的二级索引分区
可以对所有的数据构建全局索引,而不是每个分区维护自己的本地索引。
为避免成为瓶颈,不能将全局索引存储在一个节点上,否则就破坏了设计分区均衡的目标。所以,全局索引也必须进行分区,且可以与数据关键字采用不同的分区策略。
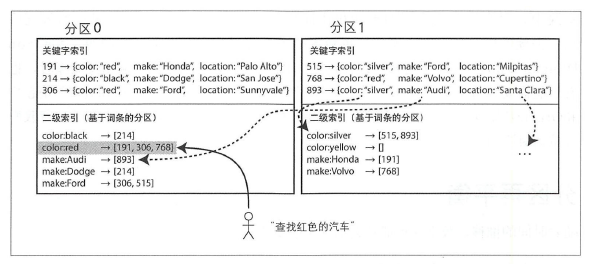
可以直接通过关键词来全局划分索引,或者对其取哈希值。直接分区的好处是可以支持高效的区间查询;而采用哈希的方式则可以更均句的划分分区。
这种全局的词条分区相比于文档分区索引的主要优点是,它的读取更为高效,即它不需要采用 scatter/gather 对所有的分区都执行一遍查询。
然而全局索引的不利之处在于, 写入速度较慢且非常复杂,主要因为单个文档的更新时,里面可能会涉及多个二级索引,而二级索引的分区又可能完全不同甚至在不同的节点上,由此势必引人显著的写放大。
理想情况下,索引应该时刻保持最新,即写入的数据要立即反映在最新的索引上。但是,对于词条分区来讲,这需要一个跨多个相关分区的分布式事务支持,写入速度会受到极大的影响,所以现有的数据库都不支持同步更新二级索引。
分区再均衡
随着时间的推移,数据库可能总会出现某些变化:
- 查询压力增加,因此需要更多的 C PU 来处理负载。
- 数据规模增加,因此需要更多的磁盘和内存来存储数据。
- 节点可能出现故障,因此需要其他机器来接管失效的节点。
所有这些变化都要求数据和请求可以从一个节点转移到另一个节点。这样一个迁移负载的过程称为再平衡(或者动态平衡)。无论对于哪种分区方案, 分区再平衡通常至少要满足:
- 平衡之后,负载、数据存储、读写请求等应该在集群范围更均匀地分布。
- 再平衡执行过程中,数据库应该可以继续正常提供读写服务。
- 避免不必要的负载迁移,以加快动态再平衡,井尽量减少网络和磁盘 I/O 影响。
动态再平衡的策略
为什么不用取模?
最好将哈希值划分为不同的区间范围,然后将每个区间分配给一个分区。
为什么不直接使用 mod,对节点数取模方怯的问题是,如果节点数 N 发生了变化,会导致很多关键字需要从现有的节点迁移到另一个节点。
固定数量的分区
创建远超实际节点数的分区数,然后为每个节点分配多个分区。
接下来, 如果集群中添加了一个新节点,该新节点可以从每个现有的节点上匀走几个分区,直到分区再次达到全局平衡。
动态分区
对于采用关键宇区间分区的数据库,如果边界设置有问题,最终可能会出现所有数据都挤在一个分区而其他分区基本为空,那么设定固定边界、固定数量的分区将非常不便:而手动去重新配置分区边界又非常繁琐。
因此, 一些数据库如 HBas e 和 RethinkDB 等采用了动态创建分区。当分区的数据增长超过一个可配的参数阔值( HBase 上默认值是 lOGB ),它就拆分为两个分区,每个承担一半的数据量[26]。相反,如果大量数据被删除,并且分区缩小到某个阑值以下,则将其与相邻分区进行合井。
每个分区总是分配给一个节点,而每个节点可以承载多个分区,这点与固定数量的分区一样。当一个大的分区发生分裂之后,可以将其中的一半转移到其他某节点以平衡负载。
但是,需要注意的是,对于一个空的数据库, 因为没有任何先验知识可以帮助确定分区的边界,所以会从一个分区开始。可能数据集很小,但直到达到第一个分裂点之前,所有的写入操作都必须由单个节点来处理, 而其他节点则处于空闲状态。
按节点比例分区
采用动态分区策略,拆分和合并操作使每个分区的大小维持在设定的最小值和最大值之间,因此分区的数量与数据集的大小成正比关系。另一方面,对于固定数量的分区方式,其每个分区的大小也与数据集的大小成正比。两种情况,分区的数量都与节点数无关。
Cassandra 和 Ketama 则采用了第三种方式,使分区数与集群节点数成正比关系。换句话说,每个节点具有固定数量的分区。此时, 当节点数不变时,每个分区的大小与数据集大小保持正比的增长关系; 当节点数增加时,分区则会调整变得更小。较大的数据量通常需要大量的节点来存储,因此这种方陆也使每个分区大小保持稳定。当一个
新节点加入集群时,它随机选择固定数量的现有分区进行分裂,然后拿走这些分区的一半数据量,将另一半数据留在原节点。随机选择分区边界的前提要求采用基于哈希分区(可以从哈希函数产生的数字范围里设置边界)
自动与手动再平衡操作
全自动式再平衡会更加方便,它在正常维护之外所增加的操作很少。但是,也有可能出现结果难以预测的情况。再平衡总体讲是个比较昂贵的操作,它需要重新路由请求井将大量数据从一个节点迁移到另一个节点。万一执行过程中间出现异常,会使网络或节点的负载过重,井影响其他请求的性能。
将自动平衡与自动故障检测相结合也可能存在一些风险。例如,假设某个节点负载过重,对请求的响应暂时受到影响,而其他节点可能会得到结论:该节点已经失效;接下来激活自动平衡来转移其负载。客观上这会加重该节点、其他节点以及网络的负荷,可能会使总体情况变得更槽,甚至导致级联式的失效扩散。
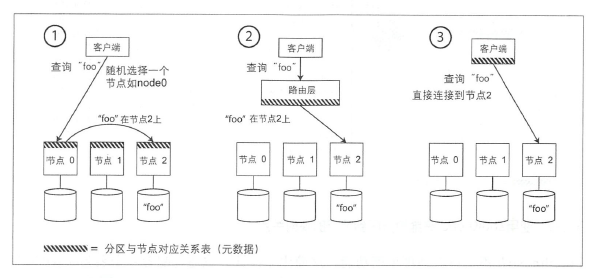
请求路由
处理策略
- 允许客户端链接任意的节点(例如,采用循环式的负载均衡器)。如果某节点恰好拥有所请求的分区,贝 lj 直接处理该请求:否则,将请求转发到下一个合适的节点,接收答复,并将答复返回给客户端。
- 将所有客户端的请求都发送到一个路由层,由后者负责将请求转发到对应的分区节点上。路由层本身不处理任何请求,它仅充一个分区感知的负载均衡器。
- 客户端感知分区和节点分配关系。此时,客户端可以直接连接到目标节点,而不需要任何中介。
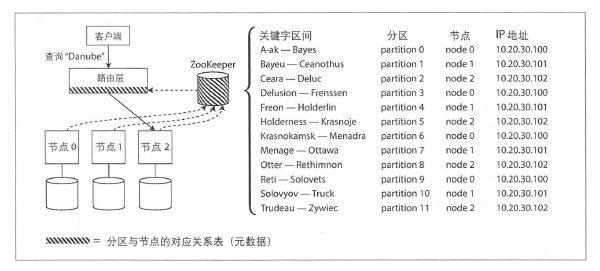
许多分布式数据系统依靠独立的协调服务(如 ZooKeeper )跟踪集群范围内的元数据。每个节点都向 ZooKeeper 中注册自己, ZooKeeper 维护了分区到节点的最终映射关系。其他参与者(如路由层或分区感知的客户端)可以向 ZooKeeper 订阅此信息。一旦分区发生了改变,或者添加、删除节点, ZooKeeper 就会主动通知路由层,这样使路由信息保持最新状态。
参考资料
- 《数据密集型应用系统设计》 - 这可能是目前最好的分布式存储书籍,强力推荐【进阶】