Tomcat连接器
Tomcat 连接器
1. NioEndpoint 组件
Tomcat 的 NioEndPoint 组件利用 Java NIO 实现了 I/O 多路复用模型。
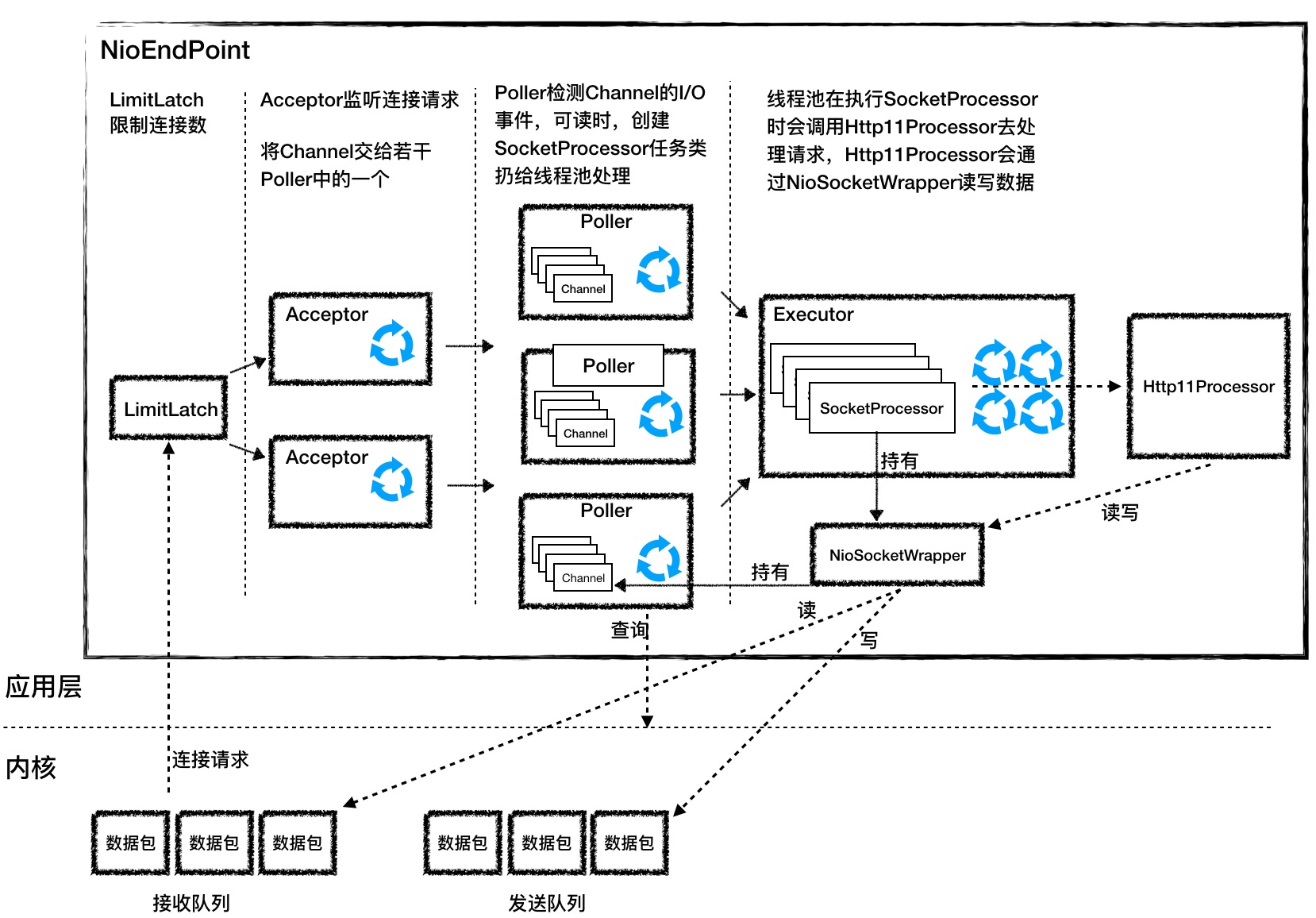
NioEndPoint 子组件功能简介:
LimitLatch是连接控制器,负责控制最大连接数。NIO 模式下默认是 10000,达到这个阈值后,连接请求被拒绝。Acceptor负责监听连接请求。Acceptor运行在一个单独的线程里,它在一个死循环里调用 accept 方法来接收新连接,一旦有新的连接请求到来,accept 方法返回一个Channel对象,接着把Channel对象交给Poller去处理。Poller的本质是一个Selector,也运行在单独线程里。Poller内部维护一个Channel数组,它在一个死循环里不断检测Channel的数据就绪状态,一旦有Channel可读,就生成一个SocketProcessor任务对象扔给Executor去处理。Executor就是线程池,负责运行SocketProcessor任务类,SocketProcessor的 run 方法会调用Http11Processor来读取和解析请求数据。我们知道,Http11Processor是应用层协议的封装,它会调用容器获得响应,再把响应通过Channel写出。
NioEndpoint 如何实现高并发的呢?
要实现高并发需要合理设计线程模型充分利用 CPU 资源,尽量不要让线程阻塞;另外,就是有多少任务,就用相应规模的线程数去处理。
NioEndpoint 要完成三件事情:接收连接、检测 I/O 事件以及处理请求,那么最核心的就是把这三件事情分开,用不同规模的线程去处理,比如用专门的线程组去跑 Acceptor,并且 Acceptor 的个数可以配置;用专门的线程组去跑 Poller,Poller 的个数也可以配置;最后具体任务的执行也由专门的线程池来处理,也可以配置线程池的大小。
1.1. LimitLatch
LimitLatch 用来控制连接个数,当连接数到达最大时阻塞线程,直到后续组件处理完一个连接后将连接数减 1。请你注意到达最大连接数后操作系统底层还是会接收客户端连接,但用户层已经不再接收。
1 | public class LimitLatch { |
LimitLatch 内步定义了内部类 Sync,而 Sync 扩展了 AQS,AQS 是 Java 并发包中的一个核心类,它在内部维护一个状态和一个线程队列,可以用来控制线程什么时候挂起,什么时候唤醒。我们可以扩展它来实现自己的同步器,实际上 Java 并发包里的锁和条件变量等等都是通过 AQS 来实现的,而这里的 LimitLatch 也不例外。
理解源码要点:
- 用户线程通过调用 LimitLatch 的 countUpOrAwait 方法来拿到锁,如果暂时无法获取,这个线程会被阻塞到 AQS 的队列中。那 AQS 怎么知道是阻塞还是不阻塞用户线程呢?其实这是由 AQS 的使用者来决定的,也就是内部类 Sync 来决定的,因为 Sync 类重写了 AQS 的tryAcquireShared() 方法。它的实现逻辑是如果当前连接数 count 小于 limit,线程能获取锁,返回 1,否则返回 -1。
- 如何用户线程被阻塞到了 AQS 的队列,那什么时候唤醒呢?同样是由 Sync 内部类决定,Sync 重写了 AQS 的releaseShared() 方法,其实就是当一个连接请求处理完了,这时又可以接收一个新连接了,这样前面阻塞的线程将会被唤醒。
1.2. Acceptor
Acceptor 实现了 Runnable 接口,因此可以跑在单独线程里。一个端口号只能对应一个 ServerSocketChannel,因此这个 ServerSocketChannel 是在多个 Acceptor 线程之间共享的,它是 Endpoint 的属性,由 Endpoint 完成初始化和端口绑定。
1 | serverSock = ServerSocketChannel.open(); |
- bind 方法的第二个参数表示操作系统的等待队列长度,我在上面提到,当应用层面的连接数到达最大值时,操作系统可以继续接收连接,那么操作系统能继续接收的最大连接数就是这个队列长度,可以通过 acceptCount 参数配置,默认是 100。
- ServerSocketChannel 被设置成阻塞模式,也就是说它是以阻塞的方式接收连接的。ServerSocketChannel 通过 accept() 接受新的连接,accept() 方法返回获得 SocketChannel 对象,然后将 SocketChannel 对象封装在一个 PollerEvent 对象中,并将 PollerEvent 对象压入 Poller 的 Queue 里,这是个典型的生产者 - 消费者模式,Acceptor 与 Poller 线程之间通过 Queue 通信。
1.3. Poller
Poller 本质是一个 Selector,它内部维护一个 Queue。
1 | private final SynchronizedQueue<PollerEvent> events = new SynchronizedQueue<>(); |
SynchronizedQueue 的核心方法都使用了 Synchronized 关键字进行修饰,用来保证同一时刻只有一个线程进行读写。
使用 SynchronizedQueue,意味着同一时刻只有一个 Acceptor 线程对队列进行读写;同时有多个 Poller 线程在运行,每个 Poller 线程都有自己的队列。每个 Poller 线程可能同时被多个 Acceptor 线程调用来注册 PollerEvent。同样 Poller 的个数可以通过 pollers 参数配置。
Poller 不断的通过内部的 Selector 对象向内核查询 Channel 的状态,一旦可读就生成任务类 SocketProcessor 交给 Executor 去处理。Poller 的另一个重要任务是循环遍历检查自己所管理的 SocketChannel 是否已经超时,如果有超时就关闭这个 SocketChannel。
1.4. SocketProcessor
我们知道,Poller 会创建 SocketProcessor 任务类交给线程池处理,而 SocketProcessor 实现了 Runnable 接口,用来定义 Executor 中线程所执行的任务,主要就是调用 Http11Processor 组件来处理请求。Http11Processor 读取 Channel 的数据来生成 ServletRequest 对象,这里请你注意:
Http11Processor 并不是直接读取 Channel 的。这是因为 Tomcat 支持同步非阻塞 I/O 模型和异步 I/O 模型,在 Java API 中,相应的 Channel 类也是不一样的,比如有 AsynchronousSocketChannel 和 SocketChannel,为了对 Http11Processor 屏蔽这些差异,Tomcat 设计了一个包装类叫作 SocketWrapper,Http11Processor 只调用 SocketWrapper 的方法去读写数据。
2. Nio2Endpoint 组件
Nio2Endpoint 工作流程跟 NioEndpoint 较为相似。
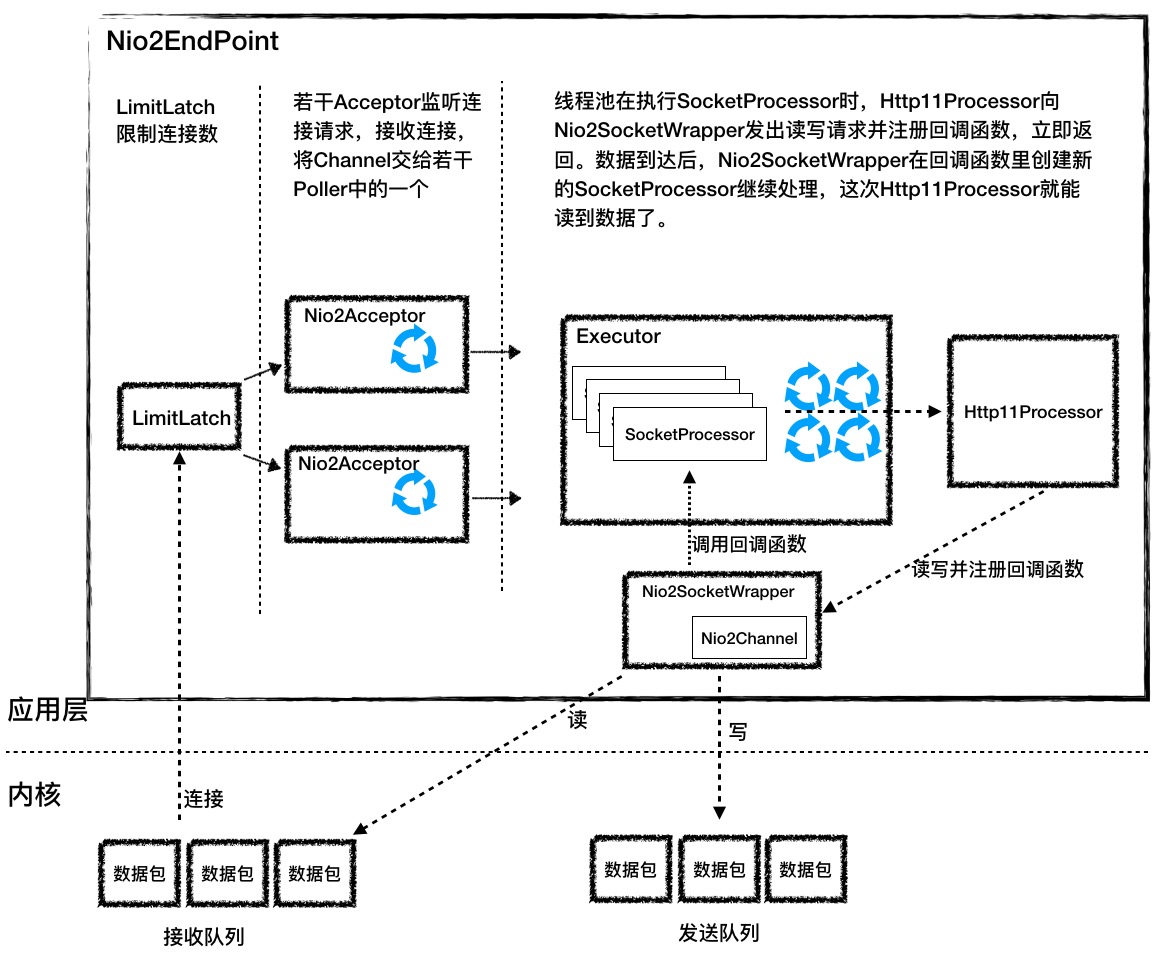
Nio2Endpoint 子组件功能说明:
LimitLatch是连接控制器,它负责控制最大连接数。Nio2Acceptor扩展了Acceptor,用异步 I/O 的方式来接收连接,跑在一个单独的线程里,也是一个线程组。Nio2Acceptor接收新的连接后,得到一个AsynchronousSocketChannel,Nio2Acceptor把AsynchronousSocketChannel封装成一个Nio2SocketWrapper,并创建一个SocketProcessor任务类交给线程池处理,并且SocketProcessor持有Nio2SocketWrapper对象。Executor在执行SocketProcessor时,SocketProcessor的 run 方法会调用Http11Processor来处理请求,Http11Processor会通过Nio2SocketWrapper读取和解析请求数据,请求经过容器处理后,再把响应通过Nio2SocketWrapper写出。
Nio2Endpoint 跟 NioEndpoint 的一个明显不同点是,Nio2Endpoint 中没有 Poller 组件,也就是没有 Selector。这是为什么呢?因为在异步 I/O 模式下,Selector 的工作交给内核来做了。
2.1. Nio2Acceptor
和 NioEndpint 一样,Nio2Endpoint 的基本思路是用 LimitLatch 组件来控制连接数。
但是 Nio2Acceptor 的监听连接的过程不是在一个死循环里不断的调 accept 方法,而是通过回调函数来完成的。我们来看看它的连接监听方法:
1 | serverSock.accept(null, this); |
其实就是调用了 accept 方法,注意它的第二个参数是 this,表明 Nio2Acceptor 自己就是处理连接的回调类,因此 Nio2Acceptor 实现了 CompletionHandler 接口。那么它是如何实现 CompletionHandler 接口的呢?
1 | protected class Nio2Acceptor extends Acceptor<AsynchronousSocketChannel> |
可以看到 CompletionHandler 的两个模板参数分别是 AsynchronousServerSocketChannel 和 Void,我在前面说过第一个参数就是 accept 方法的返回值,第二个参数是附件类,由用户自己决定,这里为 Void。completed 方法的处理逻辑比较简单:
- 如果没有连接限制,继续在本线程中调用
accept方法接收新的连接。 - 如果有连接限制,就在线程池里跑
run方法去接收新的连接。那为什么要跑run方法呢,因为在run方法里会检查连接数,当连接达到最大数时,线程可能会被LimitLatch阻塞。为什么要放在线程池里跑呢?这是因为如果放在当前线程里执行,completed方法可能被阻塞,会导致这个回调方法一直不返回。
接着 completed 方法会调用 setSocketOptions 方法,在这个方法里,会创建 Nio2SocketWrapper 和 SocketProcessor,并交给线程池处理。
2.2. Nio2SocketWrapper
Nio2SocketWrapper 的主要作用是封装 Channel,并提供接口给 Http11Processor 读写数据。讲到这里你是不是有个疑问:Http11Processor 是不能阻塞等待数据的,按照异步 I/O 的套路,Http11Processor 在调用 Nio2SocketWrapper 的 read 方法时需要注册回调类,read 调用会立即返回,问题是立即返回后 Http11Processor 还没有读到数据, 怎么办呢?这个请求的处理不就失败了吗?
为了解决这个问题,Http11Processor 是通过 2 次 read 调用来完成数据读取操作的。
- 第一次 read 调用:连接刚刚建立好后,
Acceptor创建SocketProcessor任务类交给线程池去处理,Http11Processor在处理请求的过程中,会调用Nio2SocketWrapper的 read 方法发出第一次读请求,同时注册了回调类readCompletionHandler,因为数据没读到,Http11Processor把当前的Nio2SocketWrapper标记为数据不完整。接着SocketProcessor线程被回收,Http11Processor并没有阻塞等待数据。这里请注意,Http11Processor维护了一个Nio2SocketWrapper列表,也就是维护了连接的状态。 - 第二次 read 调用:当数据到达后,内核已经把数据拷贝到
Http11Processor指定的 Buffer 里,同时回调类readCompletionHandler被调用,在这个回调处理方法里会重新创建一个新的SocketProcessor任务来继续处理这个连接,而这个新的SocketProcessor任务类持有原来那个Nio2SocketWrapper,这一次Http11Processor可以通过Nio2SocketWrapper读取数据了,因为数据已经到了应用层的 Buffer。
这个回调类 readCompletionHandler 的源码如下,最关键的一点是,**Nio2SocketWrapper 是作为附件类来传递的**,这样在回调函数里能拿到所有的上下文。
1 | this.readCompletionHandler = new CompletionHandler<Integer, SocketWrapperBase<Nio2Channel>>() { |
3. AprEndpoint 组件
我们在使用 Tomcat 时,可能会在启动日志里看到这样的提示信息:
The APR based Apache Tomcat Native library which allows optimal performance in production environments was not found on the java.library.path: ***
这句话的意思就是推荐你去安装 APR 库,可以提高系统性能。
APR(Apache Portable Runtime Libraries)是 Apache 可移植运行时库,它是用 C 语言实现的,其目的是向上层应用程序提供一个跨平台的操作系统接口库。Tomcat 可以用它来处理包括文件和网络 I/O,从而提升性能。Tomcat 支持的连接器有 NIO、NIO.2 和 APR。跟 NioEndpoint 一样,AprEndpoint 也实现了非阻塞 I/O,它们的区别是:NioEndpoint 通过调用 Java 的 NIO API 来实现非阻塞 I/O,而 AprEndpoint 是通过 JNI 调用 APR 本地库而实现非阻塞 I/O 的。
同样是非阻塞 I/O,为什么 Tomcat 会提示使用 APR 本地库的性能会更好呢?这是因为在某些场景下,比如需要频繁与操作系统进行交互,Socket 网络通信就是这样一个场景,特别是如果你的 Web 应用使用了 TLS 来加密传输,我们知道 TLS 协议在握手过程中有多次网络交互,在这种情况下 Java 跟 C 语言程序相比还是有一定的差距,而这正是 APR 的强项。
Tomcat 本身是 Java 编写的,为了调用 C 语言编写的 APR,需要通过 JNI 方式来调用。JNI(Java Native Interface) 是 JDK 提供的一个编程接口,它允许 Java 程序调用其他语言编写的程序或者代码库,其实 JDK 本身的实现也大量用到 JNI 技术来调用本地 C 程序库。
3.1. AprEndpoint 工作流程
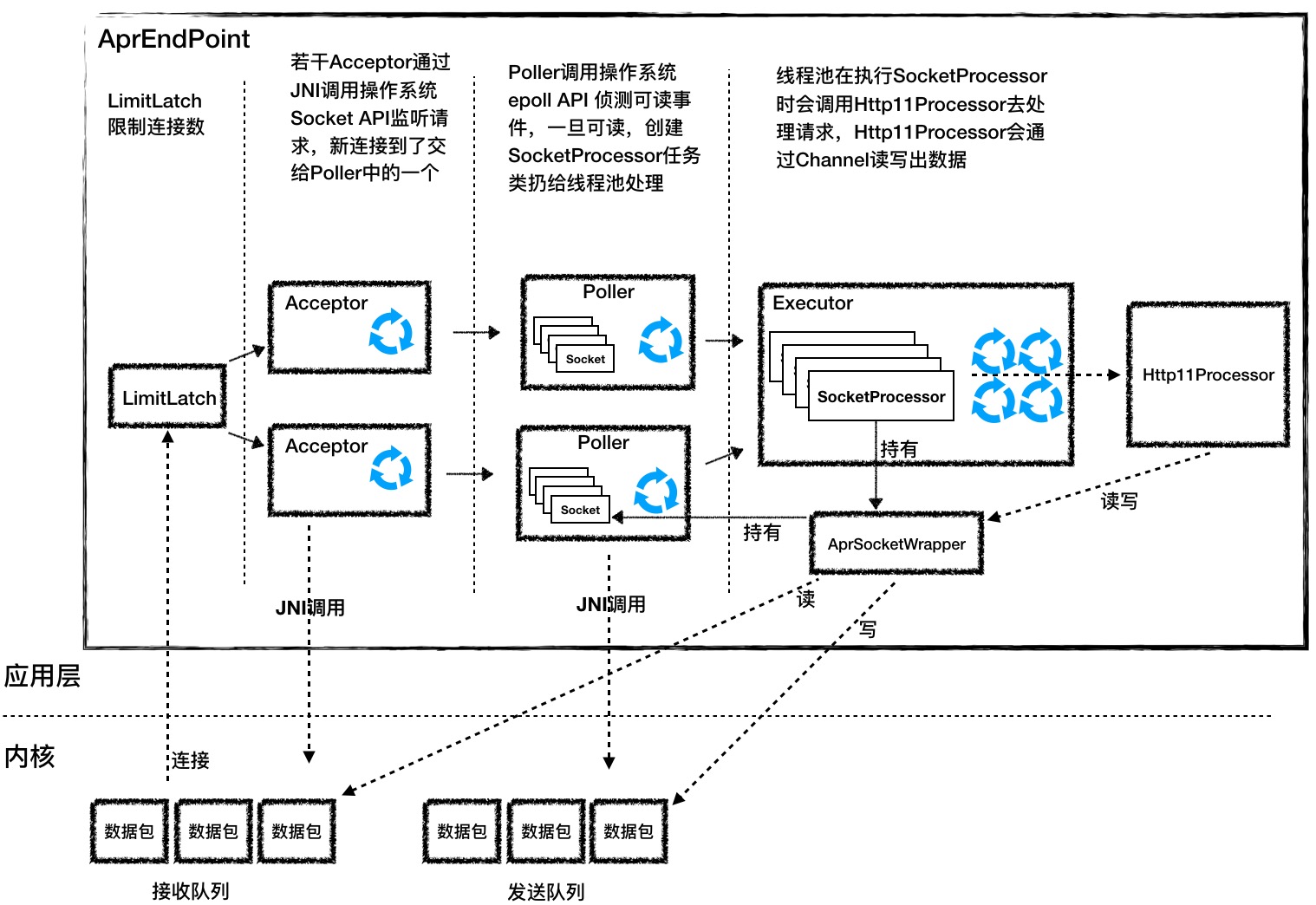
3.1.1. Acceptor
Accpetor 的功能就是监听连接,接收并建立连接。它的本质就是调用了四个操作系统 API:socket、bind、listen 和 accept。那 Java 语言如何直接调用 C 语言 API 呢?答案就是通过 JNI。具体来说就是两步:先封装一个 Java 类,在里面定义一堆用native 关键字修饰的方法,像下面这样。
1 | public class Socket { |
接着用 C 代码实现这些方法,比如 bind 函数就是这样实现的:
1 | // 注意函数的名字要符合 JNI 规范的要求 |
专栏里我就不展开 JNI 的细节了,你可以扩展阅读获得更多信息和例子。我们要注意的是函数名字要符合 JNI 的规范,以及 Java 和 C 语言如何互相传递参数,比如在 C 语言有指针,Java 没有指针的概念,所以在 Java 中用 long 类型来表示指针。AprEndpoint 的 Acceptor 组件就是调用了 APR 实现的四个 API。
3.1.2. Poller
Acceptor 接收到一个新的 Socket 连接后,按照 NioEndpoint 的实现,它会把这个 Socket 交给 Poller 去查询 I/O 事件。AprEndpoint 也是这样做的,不过 AprEndpoint 的 Poller 并不是调用 Java NIO 里的 Selector 来查询 Socket 的状态,而是通过 JNI 调用 APR 中的 poll 方法,而 APR 又是调用了操作系统的 epoll API 来实现的。
这里有个特别的地方是在 AprEndpoint 中,我们可以配置一个叫deferAccept的参数,它对应的是 TCP 协议中的TCP_DEFER_ACCEPT,设置这个参数后,当 TCP 客户端有新的连接请求到达时,TCP 服务端先不建立连接,而是再等等,直到客户端有请求数据发过来时再建立连接。这样的好处是服务端不需要用 Selector 去反复查询请求数据是否就绪。
这是一种 TCP 协议层的优化,不是每个操作系统内核都支持,因为 Java 作为一种跨平台语言,需要屏蔽各种操作系统的差异,因此并没有把这个参数提供给用户;但是对于 APR 来说,它的目的就是尽可能提升性能,因此它向用户暴露了这个参数。
3.2. APR 提升性能的秘密
APR 连接器之所以能提高 Tomcat 的性能,除了 APR 本身是 C 程序库之外,还有哪些提速的秘密呢?
JVM 堆 VS 本地内存
我们知道 Java 的类实例一般在 JVM 堆上分配,而 Java 是通过 JNI 调用 C 代码来实现 Socket 通信的,那么 C 代码在运行过程中需要的内存又是从哪里分配的呢?C 代码能否直接操作 Java 堆?
为了回答这些问题,我先来说说 JVM 和用户进程的关系。如果你想运行一个 Java 类文件,可以用下面的 Java 命令来执行。
1 | java my.class |
这个命令行中的java其实是一个可执行程序,这个程序会创建 JVM 来加载和运行你的 Java 类。操作系统会创建一个进程来执行这个java可执行程序,而每个进程都有自己的虚拟地址空间,JVM 用到的内存(包括堆、栈和方法区)就是从进程的虚拟地址空间上分配的。请你注意的是,JVM 内存只是进程空间的一部分,除此之外进程空间内还有代码段、数据段、内存映射区、内核空间等。从 JVM 的角度看,JVM 内存之外的部分叫作本地内存,C 程序代码在运行过程中用到的内存就是本地内存中分配的。下面我们通过一张图来理解一下。
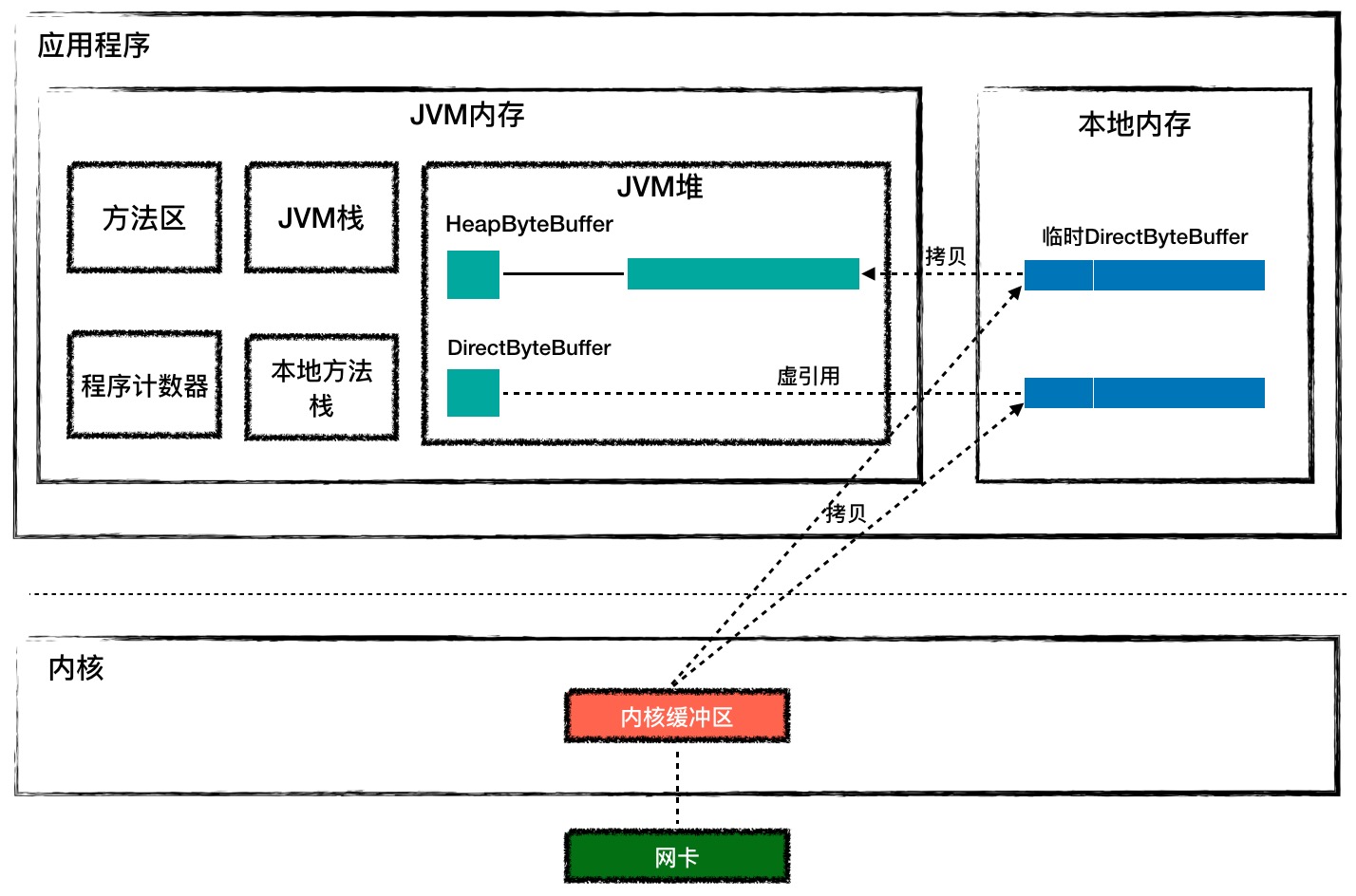
Tomcat 的 Endpoint 组件在接收网络数据时需要预先分配好一块 Buffer,所谓的 Buffer 就是字节数组byte[],Java 通过 JNI 调用把这块 Buffer 的地址传给 C 代码,C 代码通过操作系统 API 读取 Socket 并把数据填充到这块 Buffer。Java NIO API 提供了两种 Buffer 来接收数据:HeapByteBuffer 和 DirectByteBuffer,下面的代码演示了如何创建两种 Buffer。
1 | // 分配 HeapByteBuffer |
创建好 Buffer 后直接传给 Channel 的 read 或者 write 函数,最终这块 Buffer 会通过 JNI 调用传递给 C 程序。
1 | // 将 buf 作为 read 函数的参数 |
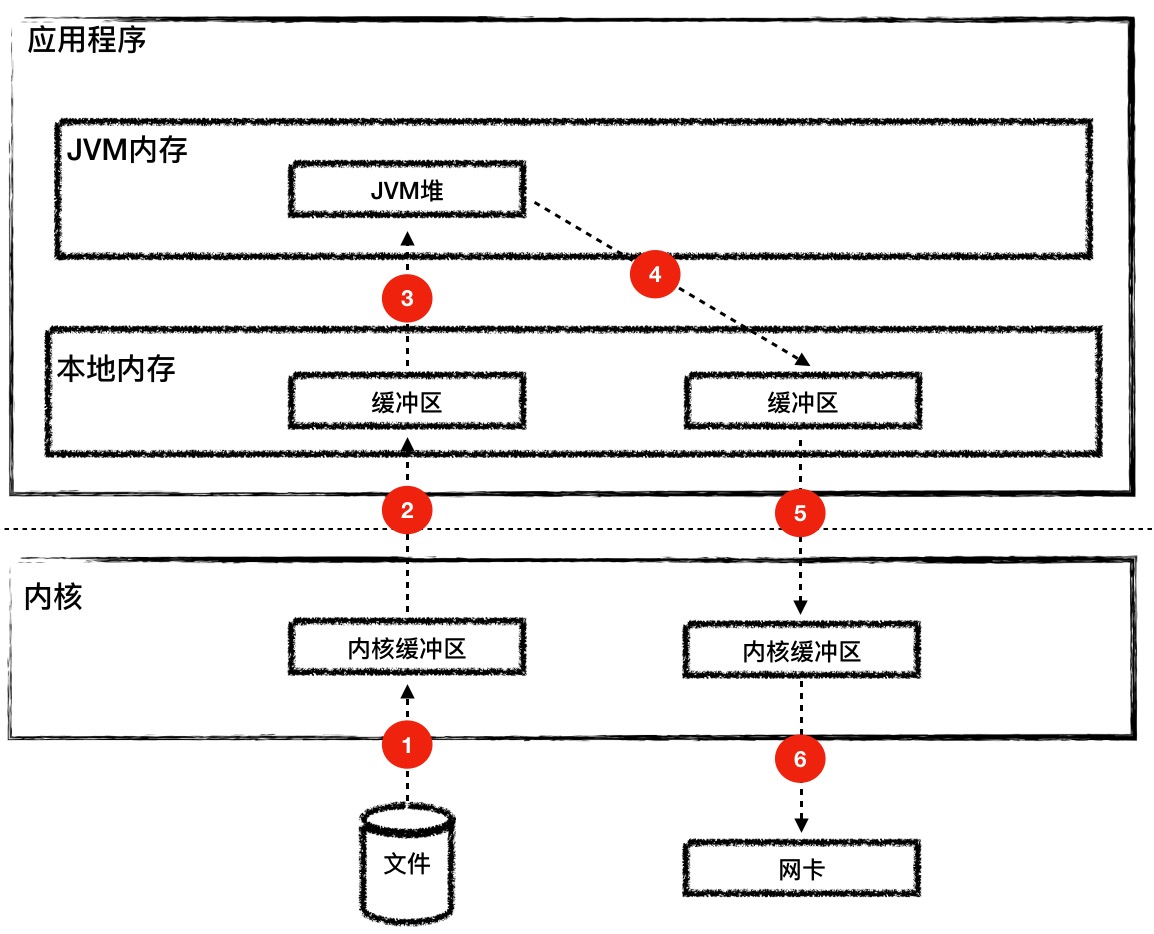
那 HeapByteBuffer 和 DirectByteBuffer 有什么区别呢?HeapByteBuffer 对象本身在 JVM 堆上分配,并且它持有的字节数组byte[]也是在 JVM 堆上分配。但是如果用HeapByteBuffer来接收网络数据,需要把数据从内核先拷贝到一个临时的本地内存,再从临时本地内存拷贝到 JVM 堆,而不是直接从内核拷贝到 JVM 堆上。这是为什么呢?这是因为数据从内核拷贝到 JVM 堆的过程中,JVM 可能会发生 GC,GC 过程中对象可能会被移动,也就是说 JVM 堆上的字节数组可能会被移动,这样的话 Buffer 地址就失效了。如果这中间经过本地内存中转,从本地内存到 JVM 堆的拷贝过程中 JVM 可以保证不做 GC。
如果使用 HeapByteBuffer,你会发现 JVM 堆和内核之间多了一层中转,而 DirectByteBuffer 用来解决这个问题,DirectByteBuffer 对象本身在 JVM 堆上,但是它持有的字节数组不是从 JVM 堆上分配的,而是从本地内存分配的。DirectByteBuffer 对象中有个 long 类型字段 address,记录着本地内存的地址,这样在接收数据的时候,直接把这个本地内存地址传递给 C 程序,C 程序会将网络数据从内核拷贝到这个本地内存,JVM 可以直接读取这个本地内存,这种方式比 HeapByteBuffer 少了一次拷贝,因此一般来说它的速度会比 HeapByteBuffer 快好几倍。你可以通过上面的图加深理解。
Tomcat 中的 AprEndpoint 就是通过 DirectByteBuffer 来接收数据的,而 NioEndpoint 和 Nio2Endpoint 是通过 HeapByteBuffer 来接收数据的。你可能会问,NioEndpoint 和 Nio2Endpoint 为什么不用 DirectByteBuffer 呢?这是因为本地内存不好管理,发生内存泄漏难以定位,从稳定性考虑,NioEndpoint 和 Nio2Endpoint 没有去冒这个险。
3.2.1. sendfile
我们再来考虑另一个网络通信的场景,也就是静态文件的处理。浏览器通过 Tomcat 来获取一个 HTML 文件,而 Tomcat 的处理逻辑无非是两步:
- 从磁盘读取 HTML 到内存。
- 将这段内存的内容通过 Socket 发送出去。
但是在传统方式下,有很多次的内存拷贝:
- 读取文件时,首先是内核把文件内容读取到内核缓冲区。
- 如果使用 HeapByteBuffer,文件数据从内核到 JVM 堆内存需要经过本地内存中转。
- 同样在将文件内容推入网络时,从 JVM 堆到内核缓冲区需要经过本地内存中转。
- 最后还需要把文件从内核缓冲区拷贝到网卡缓冲区。
从下面的图你会发现这个过程有 6 次内存拷贝,并且 read 和 write 等系统调用将导致进程从用户态到内核态的切换,会耗费大量的 CPU 和内存资源。
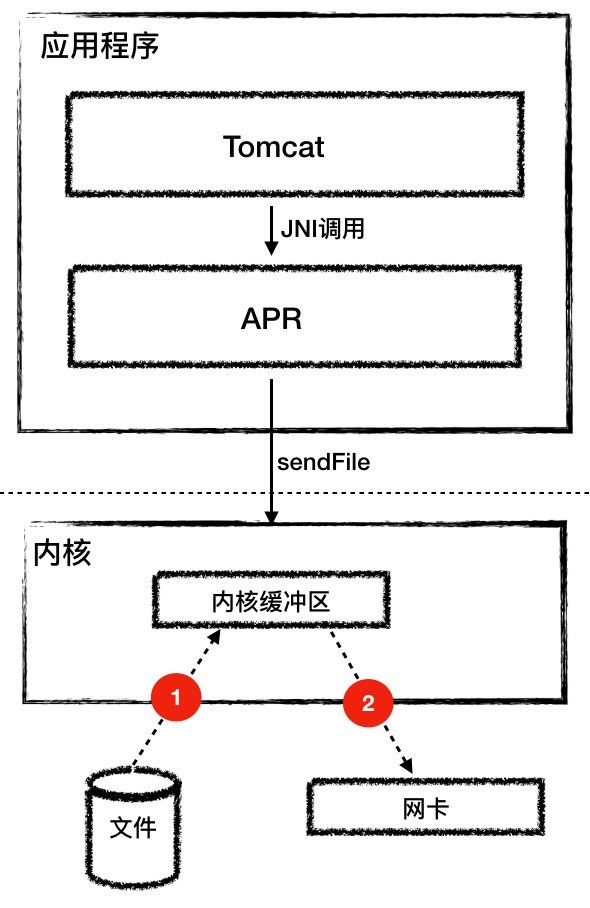
而 Tomcat 的 AprEndpoint 通过操作系统层面的 sendfile 特性解决了这个问题,sendfile 系统调用方式非常简洁。
1 | sendfile(socket, file, len); |
它带有两个关键参数:Socket 和文件句柄。将文件从磁盘写入 Socket 的过程只有两步:
第一步:将文件内容读取到内核缓冲区。
第二步:数据并没有从内核缓冲区复制到 Socket 关联的缓冲区,只有记录数据位置和长度的描述符被添加到 Socket 缓冲区中;接着把数据直接从内核缓冲区传递给网卡。这个过程你可以看下面的图。
4. Executor 组件
为了提高处理能力和并发度,Web 容器一般会把处理请求的工作放到线程池里来执行,Tomcat 扩展了原生的 Java 线程池,来满足 Web 容器高并发的需求。
4.1. Tomcat 定制线程池
Tomcat 的线程池也是一个定制版的 ThreadPoolExecutor。Tomcat 传入的参数是这样的:
1 | // 定制版的任务队列 |
其中的两个关键点:
- Tomcat 有自己的定制版任务队列和线程工厂,并且可以限制任务队列的长度,它的最大长度是 maxQueueSize。
- Tomcat 对线程数也有限制,设置了核心线程数(minSpareThreads)和最大线程池数(maxThreads)。
除了资源限制以外,Tomcat 线程池还定制自己的任务处理流程。我们知道 Java 原生线程池的任务处理逻辑比较简单:
- 前 corePoolSize 个任务时,来一个任务就创建一个新线程。
- 后面再来任务,就把任务添加到任务队列里让所有的线程去抢,如果队列满了就创建临时线程。
- 如果总线程数达到 maximumPoolSize,执行拒绝策略。
Tomcat 线程池扩展了原生的 ThreadPoolExecutor,通过重写 execute 方法实现了自己的任务处理逻辑:
- 前 corePoolSize 个任务时,来一个任务就创建一个新线程。
- 再来任务的话,就把任务添加到任务队列里让所有的线程去抢,如果队列满了就创建临时线程。
- 如果总线程数达到 maximumPoolSize,则继续尝试把任务添加到任务队列中去。
- 如果缓冲队列也满了,插入失败,执行拒绝策略。
观察 Tomcat 线程池和 Java 原生线程池的区别,其实就是在第 3 步,Tomcat 在线程总数达到最大数时,不是立即执行拒绝策略,而是再尝试向任务队列添加任务,添加失败后再执行拒绝策略。那具体如何实现呢,其实很简单,我们来看一下 Tomcat 线程池的 execute 方法的核心代码。
1 | public class ThreadPoolExecutor extends java.util.concurrent.ThreadPoolExecutor { |
从这个方法你可以看到,Tomcat 线程池的 execute 方法会调用 Java 原生线程池的 execute 去执行任务,如果总线程数达到 maximumPoolSize,Java 原生线程池的 execute 方法会抛出 RejectedExecutionException 异常,但是这个异常会被 Tomcat 线程池的 execute 方法捕获到,并继续尝试把这个任务放到任务队列中去;如果任务队列也满了,再执行拒绝策略。
4.2. Tomcat 定制任务队列
细心的你有没有发现,在 Tomcat 线程池的 execute 方法最开始有这么一行:
1 | submittedCount.incrementAndGet(); |
这行代码的意思把 submittedCount 这个原子变量加一,并且在任务执行失败,抛出拒绝异常时,将这个原子变量减一:
1 | submittedCount.decrementAndGet(); |
其实 Tomcat 线程池是用这个变量 submittedCount 来维护已经提交到了线程池,但是还没有执行完的任务个数。Tomcat 为什么要维护这个变量呢?这跟 Tomcat 的定制版的任务队列有关。Tomcat 的任务队列 TaskQueue 扩展了 Java 中的 LinkedBlockingQueue,我们知道 LinkedBlockingQueue 默认情况下长度是没有限制的,除非给它一个 capacity。因此 Tomcat 给了它一个 capacity,TaskQueue 的构造函数中有个整型的参数 capacity,TaskQueue 将 capacity 传给父类 LinkedBlockingQueue 的构造函数。
1 | public class TaskQueue extends LinkedBlockingQueue<Runnable> { |
这个 capacity 参数是通过 Tomcat 的 maxQueueSize 参数来设置的,但问题是默认情况下 maxQueueSize 的值是Integer.MAX_VALUE,等于没有限制,这样就带来一个问题:当前线程数达到核心线程数之后,再来任务的话线程池会把任务添加到任务队列,并且总是会成功,这样永远不会有机会创建新线程了。
为了解决这个问题,TaskQueue 重写了 LinkedBlockingQueue 的 offer 方法,在合适的时机返回 false,返回 false 表示任务添加失败,这时线程池会创建新的线程。那什么是合适的时机呢?请看下面 offer 方法的核心源码:
1 | public class TaskQueue extends LinkedBlockingQueue<Runnable> { |
从上面的代码我们看到,只有当前线程数大于核心线程数、小于最大线程数,并且已提交的任务个数大于当前线程数时,也就是说线程不够用了,但是线程数又没达到极限,才会去创建新的线程。这就是为什么 Tomcat 需要维护已提交任务数这个变量,它的目的就是在任务队列的长度无限制的情况下,让线程池有机会创建新的线程。
当然默认情况下 Tomcat 的任务队列是没有限制的,你可以通过设置 maxQueueSize 参数来限制任务队列的长度。
5. WebSocket 组件
HTTP 协议是“请求 - 响应”模式,浏览器必须先发请求给服务器,服务器才会响应这个请求。也就是说,服务器不会主动发送数据给浏览器。
对于实时性要求比较的高的应用,比如在线游戏、股票基金实时报价和在线协同编辑等,浏览器需要实时显示服务器上最新的数据,因此出现了 Ajax 和 Comet 技术。Ajax 本质上还是轮询,而 Comet 是在 HTTP 长连接的基础上做了一些 hack,但是它们的实时性不高,另外频繁的请求会给服务器带来压力,也会浪费网络流量和带宽。于是 HTML5 推出了 WebSocket 标准,使得浏览器和服务器之间任何一方都可以主动发消息给对方,这样服务器有新数据时可以主动推送给浏览器。
Tomcat 如何支持 WebSocket?简单来说,Tomcat 做了两件事:
- Endpoint 加载
- WebSocket 请求处理
5.1. WebSocket 加载
Tomcat 的 WebSocket 加载是通过 SCI 机制完成的。SCI 全称 ServletContainerInitializer,是 Servlet 3.0 规范中定义的用来接收 Web 应用启动事件的接口。那为什么要监听 Servlet 容器的启动事件呢?因为这样我们有机会在 Web 应用启动时做一些初始化工作,比如 WebSocket 需要扫描和加载 Endpoint 类。SCI 的使用也比较简单,将实现 ServletContainerInitializer 接口的类增加 HandlesTypes 注解,并且在注解内指定的一系列类和接口集合。比如 Tomcat 为了扫描和加载 Endpoint 而定义的 SCI 类如下:
1 | @HandlesTypes({ServerEndpoint.class, ServerApplicationConfig.class, Endpoint.class}) |
一旦定义好了 SCI,Tomcat 在启动阶段扫描类时,会将 HandlesTypes 注解中指定的类都扫描出来,作为 SCI 的 onStartup 方法的参数,并调用 SCI 的 onStartup 方法。注意到 WsSci 的 HandlesTypes 注解中定义了ServerEndpoint.class、ServerApplicationConfig.class和Endpoint.class,因此在 Tomcat 的启动阶段会将这些类的类实例(注意不是对象实例)传递给 WsSci 的 onStartup 方法。那么 WsSci 的 onStartup 方法又做了什么事呢?
它会构造一个 WebSocketContainer 实例,你可以把 WebSocketContainer 理解成一个专门处理 WebSocket 请求的Endpoint 容器。也就是说 Tomcat 会把扫描到的 Endpoint 子类和添加了注解@ServerEndpoint的类注册到这个容器中,并且这个容器还维护了 URL 到 Endpoint 的映射关系,这样通过请求 URL 就能找到具体的 Endpoint 来处理 WebSocket 请求。
5.2. WebSocket 请求处理
Tomcat 用 ProtocolHandler 组件屏蔽应用层协议的差异,其中 ProtocolHandler 中有两个关键组件:Endpoint 和 Processor。需要注意,这里的 Endpoint 跟上文提到的 WebSocket 中的 Endpoint 完全是两回事,连接器中的 Endpoint 组件用来处理 I/O 通信。WebSocket 本质就是一个应用层协议,因此不能用 HttpProcessor 来处理 WebSocket 请求,而要用专门 Processor 来处理,而在 Tomcat 中这样的 Processor 叫作 UpgradeProcessor。
为什么叫 Upgrade Processor 呢?这是因为 Tomcat 是将 HTTP 协议升级成 WebSocket 协议的。
WebSocket 是通过 HTTP 协议来进行握手的,因此当 WebSocket 的握手请求到来时,HttpProtocolHandler 首先接收到这个请求,在处理这个 HTTP 请求时,Tomcat 通过一个特殊的 Filter 判断该当前 HTTP 请求是否是一个 WebSocket Upgrade 请求(即包含Upgrade: websocket的 HTTP 头信息),如果是,则在 HTTP 响应里添加 WebSocket 相关的响应头信息,并进行协议升级。具体来说就是用 UpgradeProtocolHandler 替换当前的 HttpProtocolHandler,相应的,把当前 Socket 的 Processor 替换成 UpgradeProcessor,同时 Tomcat 会创建 WebSocket Session 实例和 Endpoint 实例,并跟当前的 WebSocket 连接一一对应起来。这个 WebSocket 连接不会立即关闭,并且在请求处理中,不再使用原有的 HttpProcessor,而是用专门的 UpgradeProcessor,UpgradeProcessor 最终会调用相应的 Endpoint 实例来处理请求。
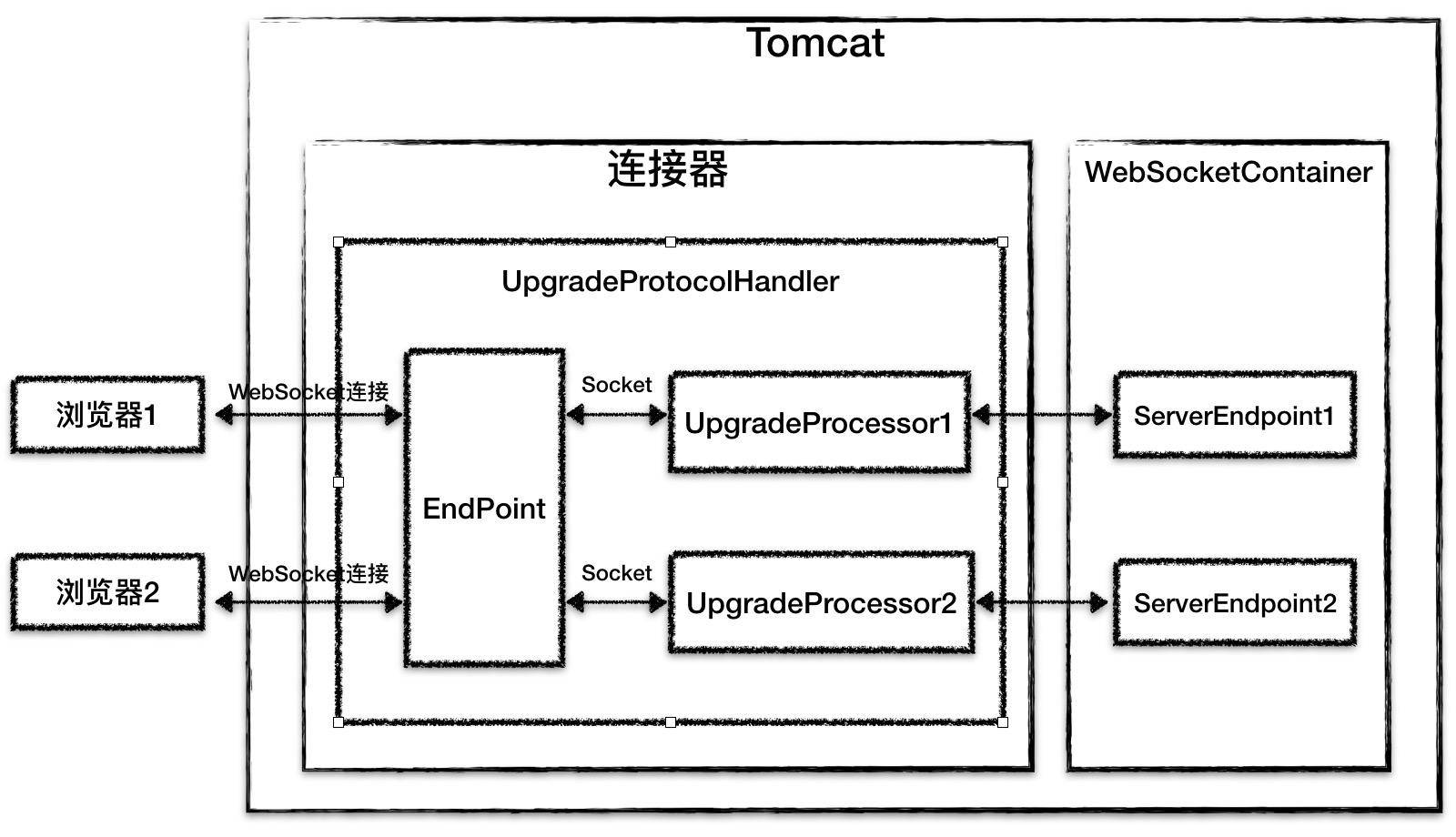
你可以看到,Tomcat 对 WebSocket 请求的处理没有经过 Servlet 容器,而是通过 UpgradeProcessor 组件直接把请求发到 ServerEndpoint 实例,并且 Tomcat 的 WebSocket 实现不需要关注具体 I/O 模型的细节,从而实现了与具体 I/O 方式的解耦。