《后端存储实战课》笔记
《后端存储实战课》笔记
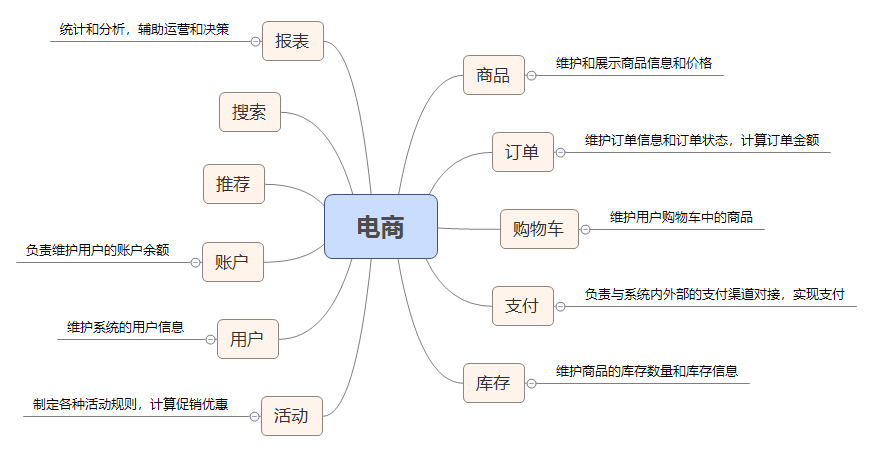
课前加餐丨电商系统是如何设计的?
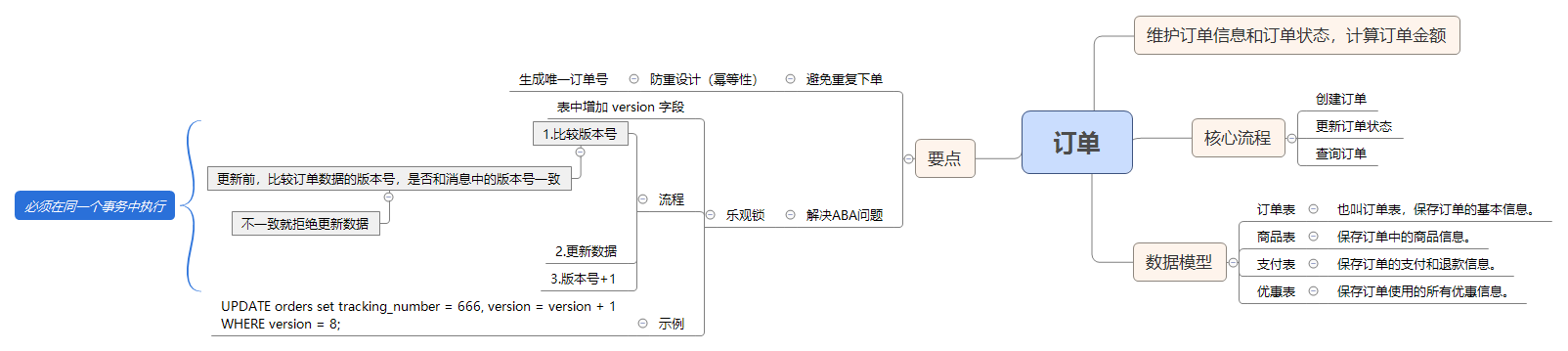
创建和更新订单时,如何保证数据准确无误?
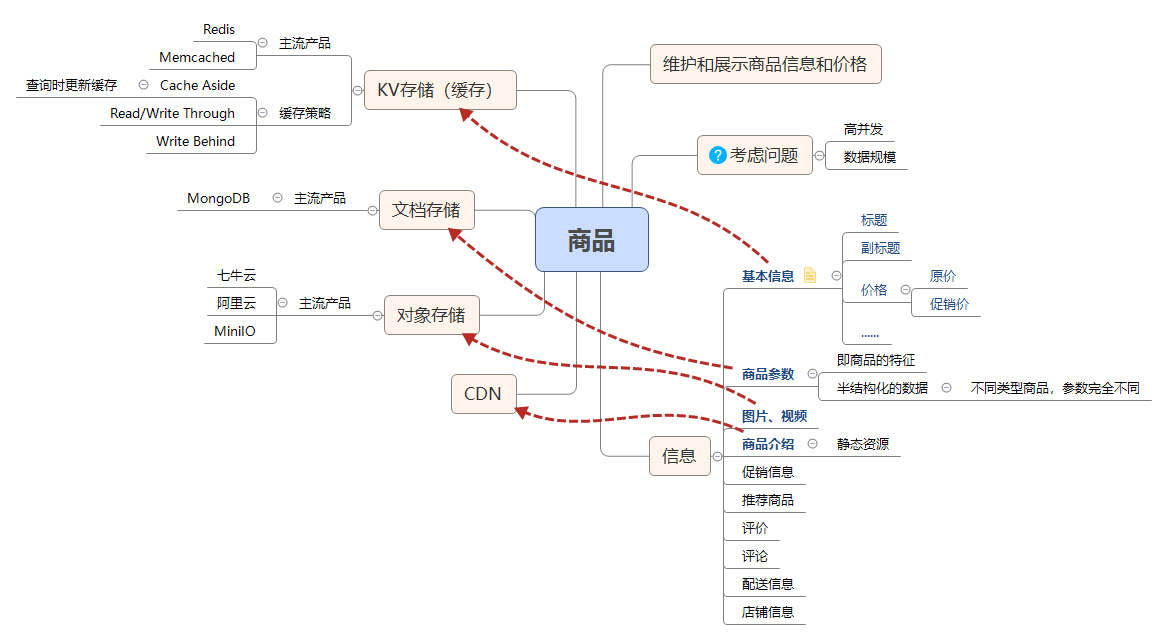
流量大、数据多的商品详情页系统该如何设计?
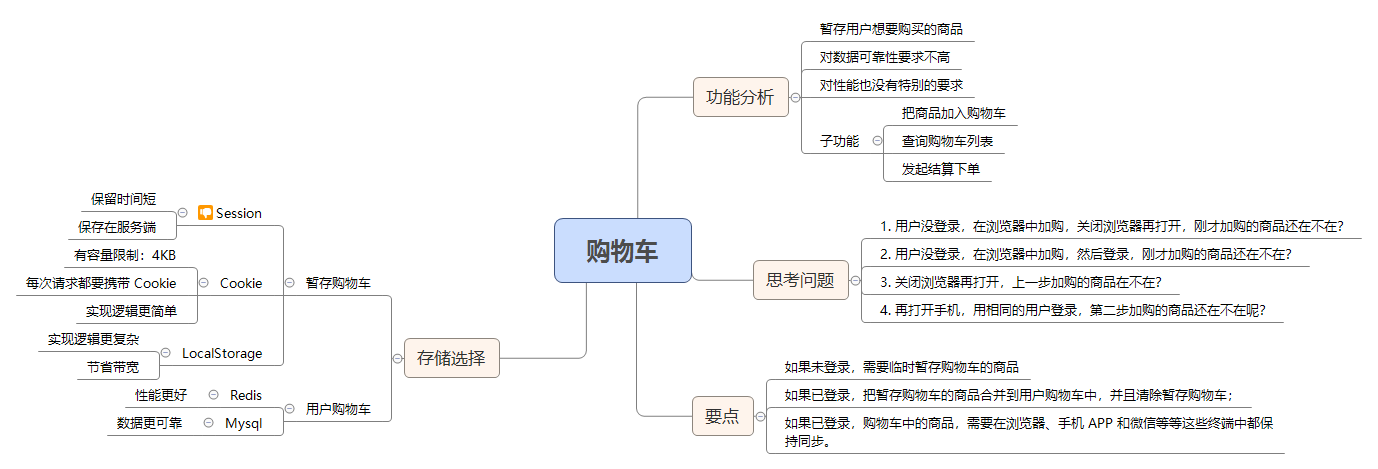
复杂而又重要的购物车系统,应该如何设计?
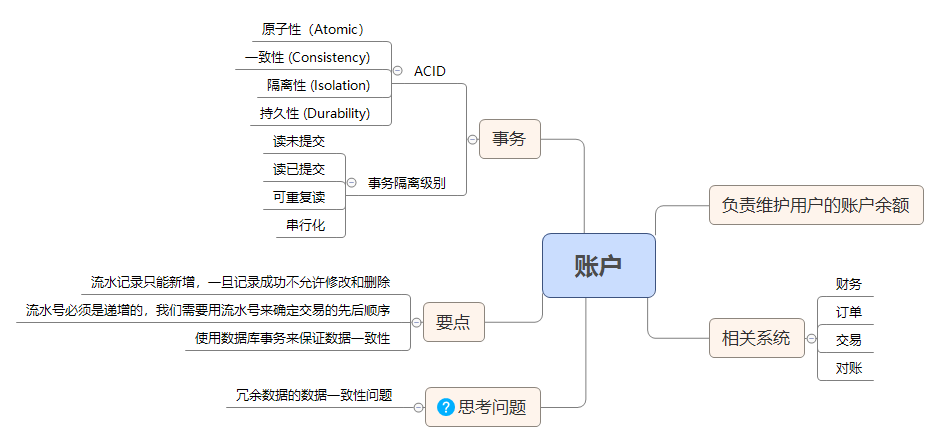
事务:账户余额总是对不上账,怎么办?
分布式事务:如何保证多个系统间的数据是一致的?
分布式事务常见解决方案:
- 2PC
- 3PC
- TCC
- Saga
- 本地消息表
个人以前总结:分布式事务
如何用 Elasticsearch 构建商品搜索系统?
搜索领域的核心问题是进行全文匹配。一般的关系型数据库,如 Mysql 的索引(InnoDB 为 B 树索引)不适用于全文检索,导致查询时只能全表扫描,性能很差。
搜索引擎(典型代表:Elasticsearch)通过倒排索引技术,很好的支持了全文检索。但是,倒排索引的写入和更新性能相较于 B 树索引较差,因此不适用于更新频繁的数据。
MySQL HA:如何将“删库跑路”的损失降到最低?
Mysql 复制(略)
一个几乎每个系统必踩的坑儿:访问数据库超时
数据库超时分析经验:
- 根据故障时段在系统忙时,推断出故障是跟支持用户访问的功能有关。
- 根据系统能在流量峰值过后自动恢复这一现象,排除后台服务被大量请求打死的可能性。
- 根据 CPU 利用率的变化曲线,如果满足一定的周期性波动,可推断出大概率和定时任务有关。这些定时任务负责刷新数据缓存。如果确实是因为刷新缓存定时任务导致的,需要针对性优化。
- 如果 Mysql CPU 过高,大概率是慢 SQL 导致的,优先排查慢 SQL 日志,找出查询特别慢的表。看看该表是不是需要加缓存。
避免访问数据库超时的注意点:
- 开发时,考虑 SQL 相关表的数据规模,查询性能,是否匹配索引等等,避免出现慢 SQL
- 设计上,考虑减少查询次数,如使用缓存
- 系统支持自动杀慢 SQL
- 支持熔断、降级,减少故障影响范围
怎么能避免写出慢 SQL?
数据表不宜过大,一般不要超过千万条数据。
根据实际情况,尽量设计好索引,以提高查询、排序效率。
如果出现慢 SQL,需要改造索引时,可以通过执行计划进行分析。
走进黑盒:SQL 是如何在数据库中执行的?
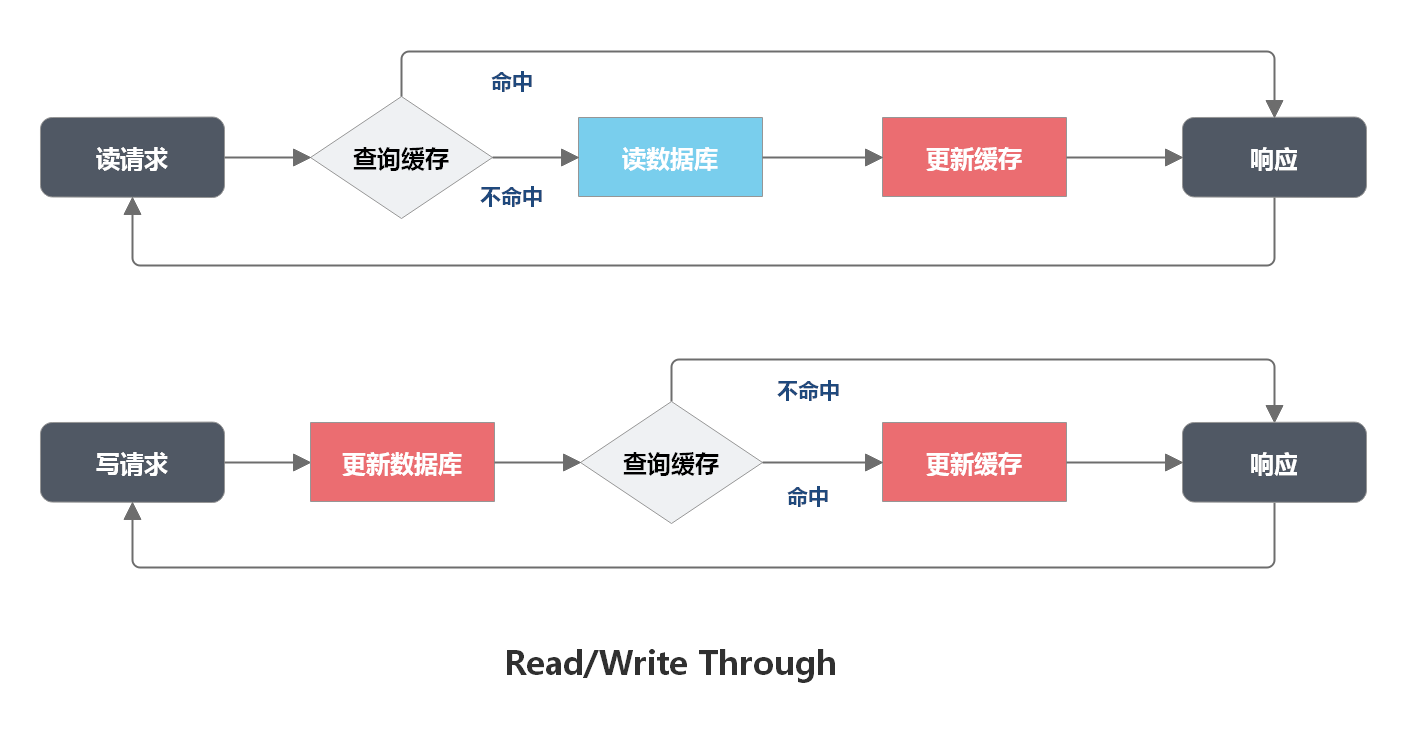
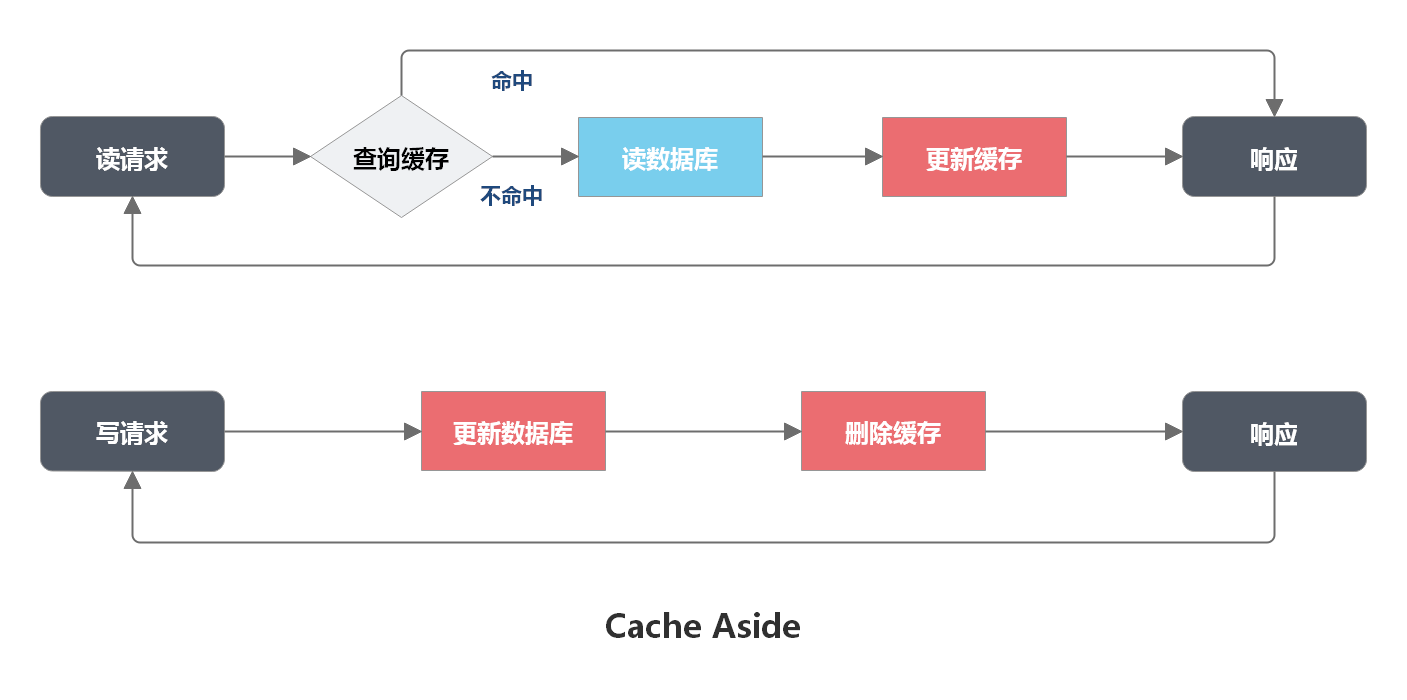
MySQL 如何应对高并发(一):使用缓存保护 MySQL
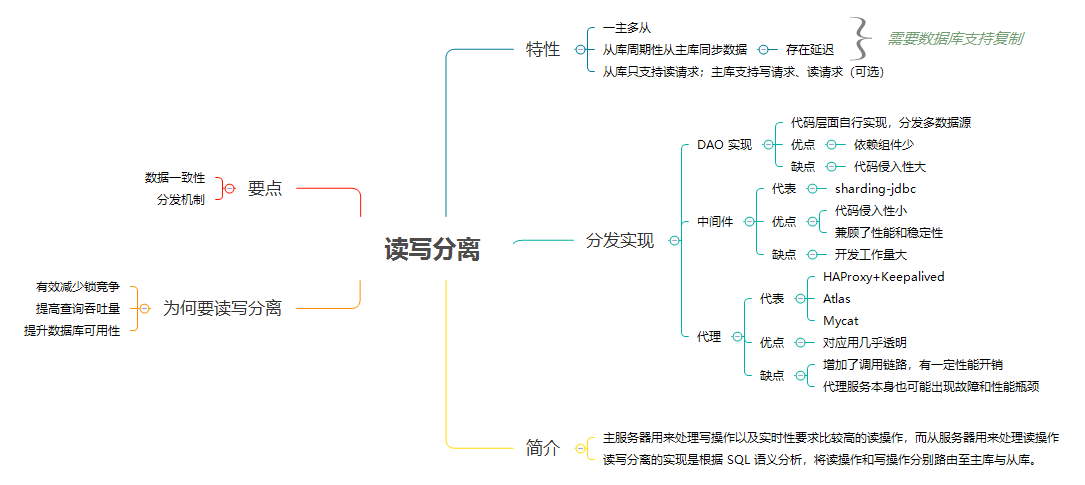
MySQL 如何应对高并发(二):读写分离
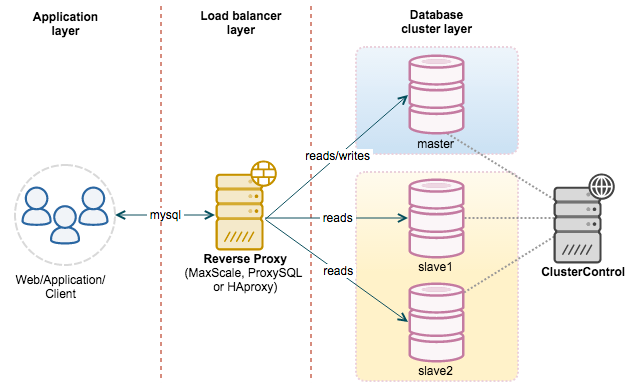
MySQL 主从数据库同步是如何实现的?
基于 binlog 进行数据同步
订单数据越来越多,数据库越来越慢该怎么办?
针对大表,为了优化其查询性能,可以将历史数据归档。一般可以考虑归档到列式数据库,如:Hive
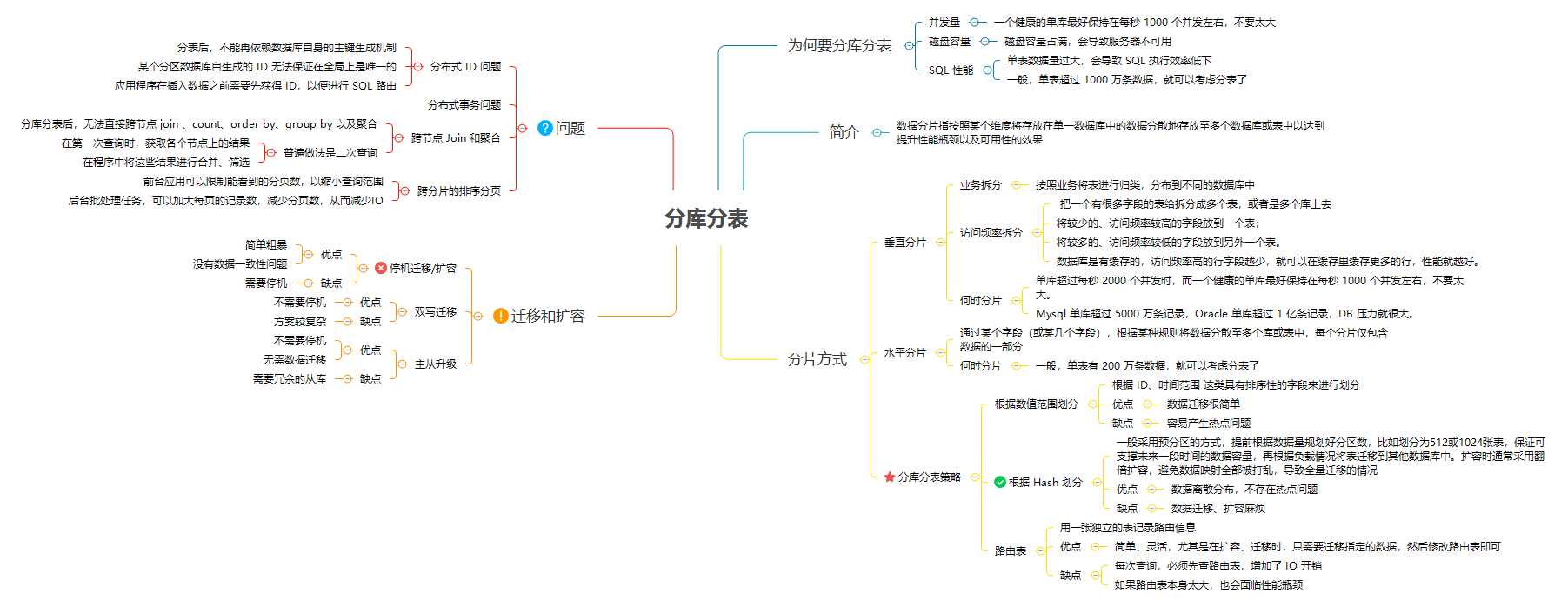
MySQL 存储海量数据的最后一招:分库分表
分库分表
用 Redis 构建缓存集群的最佳实践有哪些
Redis 3.0 后,官方提供 Redis Cluster 来解决数据量大、高可用和高并发问题。
相关文章:Redis 集群
大厂都是怎么做 MySQL to Redis 同步的?
缓存穿透:把全量数据都放在 Redis 集群,服务通过接受 MQ 消息,去触发更新缓存数据。
使用 Binlog 实时更新 Redis 缓存,如 Canal
分布式存储:你知道对象存储是如何保存图片文件的吗?
保存图片、音频、视频这种相对较大的文件,一般使用对象存储。如:HDFS 等。
元数据管理:ZooKeeper、etcd、Nacos
对象如何拆分和保存:将大文件分块(block),提升 IO 效率并方便维护。
跨系统实时同步数据,分布式事务是唯一的解决方案吗?
跨系统实时同步数据:
- 早期方案:使用 ETL 定时同步数据,在 T+1 时刻去同步上一周期的数据,然后进行计算和分析。
- 使用 Binlog 和 MQ 构建实时数据同步系统
如何保证数据同步的实时性
- 为了能够支撑众多下游数据库实时同步的需求,可以通过 MQ 解耦上下游,Binlog 先发送到 MQ 中,下游各业务方可以消费 MQ 中的消息再写入各自的数据库。
- 如果下游处理能力不能满足要求,可以增加 MQ 中的分区数量实现并发同步,但需要结合同步的业务数据特点,把具有因果关系的数据哈希到相同分区上,才能避免因为并发乱序而出现数据同步错误的问题。
如何在不停机的情况下,安全地更换数据库?
- 停机迁移/扩容
- 优点:简单粗暴;没有数据一致性问题
- 缺点:需要停机
- 双写迁移
- 优点:不需要停机
- 缺点:方案较复杂
- 主从升级
- 优点:不需要停机;无需数据迁移
- 缺点:需要冗余的从库
类似“点击流”这样的海量数据应该如何存储?
使用 Kafka 暂存海量原始数据,然后再使用大数据计算框架(Spark、Flink)进行计算。
其他方案:
分布式流数据存储,如:Pravega、Pulsar 的存储引擎 BookKeeper
时序数据库,如:InfluxDB、OpenTSDB 等。
面对海量数据,如何才能查得更快
实时计算:Flink、Storm
批处理计算:Map-Reduce、Spark
海量数据存储:
- 列式数据库(在正确使用的前提下,10GB 量级的数据查询基本上可以做到秒级返回):HBase、Cassandra
- 搜索引擎(对于 TB 量级以下的数据,如果可以接受相对比较贵的硬件成本):Elasticsearch
MySQL 经常遇到的高可用、分片问题,NewSQL 是如何解决的?
安利 CockroachDB、RocksDB、OceanBase
RocksDB:不丢数据的高性能 KV 存储、
越来越多的新生代数据库,都选择 RocksDB 作为它们的存储引擎。
Redis 是一个内存数据库,所以它很快。
RocksDB 是一个持久化的 KV 存储,它需要保证每条数据都要安全地写到磁盘上。磁盘的读写性能和内
存读写性能差着一两个数量级,读写磁盘的 RocksDB,能和读写内存的 Redis 做到相近的性能,这就是 RocksDB 的价值所在了。
RocksDB 性能好,是由于使用了 LSM 树结构。
LSM-Tree 的全称是:The Log-Structured Merge-Tree,是一种非常复杂的复合数据结构,它包含了 WAL(Write Ahead Log)、跳表(SkipList)和一个分层的有序表(SSTable,Sorted String Table)。
参考资料
- 后端存储实战课 - 极客教程【入门】:讲解存储在电商领域的种种应用和一些基本特性