《24 讲吃透分布式数据库》笔记
《24 讲吃透分布式数据库》笔记
开篇词 吃透分布式数据库,提升职场竞争力
略
导论:什么是分布式数据库?聊聊它的前世今生
分布式数据库的核心
数据分片
水平分片:按行进行数据分割,数据被切割为一个个数据组,分散到不同节点上。
垂直分片:按列进行数据切割,一个数据表的模式(Schema)被切割为多个小的模式。
数据同步
数据库同步用于帮助数据库恢复一致性。
分布式数据库发展就是一个由合到分,再到合的过程:
- 早期的关系型商业数据库的分布式能力可以满足大部分用户的场景,因此产生了如 Oracle 等几种巨无霸数据库产品;
- OLAP 领域首先寻求突破,演化出了大数据技术与 MPP 类型数据库,提供功能更强的数据分析能力;
- 去 IOE 引入数据库中间件,并结合应用平台与开源单机数据库形成新一代解决方案,让商业关系型数据库走下神坛,NoSQL 数据库更进一步打破了关系型数据库唯我独尊的江湖地位;
- 新一代分布式 OLTP 数据库正式完成了分布式领域对数据库核心特性的完整支持,它代表了分布式数据库从此走向了成熟,也表明了 OLAP 与 OLTP 分布式场景下,分别在各自领域内取得了胜利;
- HTAP 和多模式数据处理的引入,再一次将 OLAP 与 OLTP 融合,从而将分布式数据库推向如传统商业关系型数据库数十年前那般的盛况,而其产生的影响要比后者更为深远。
SQL vs NoSQL:一次搞清楚五花八门的“SQL”
略
数据分片:如何存储超大规模的数据?
数据分片概论
想提升系统对于数据的处理,有两种思路:
垂直扩展:提升硬件设备,获得更好的 CPU、更大的内存。但这种方式容易达到瓶颈。
水平扩展:采用分而治之的思想,将数据拆分成多个分区,分散到一组便宜的机器上。这种方式性价比更高,不过也会引入数据同步等复杂的问题。
分片算法
哈希分片
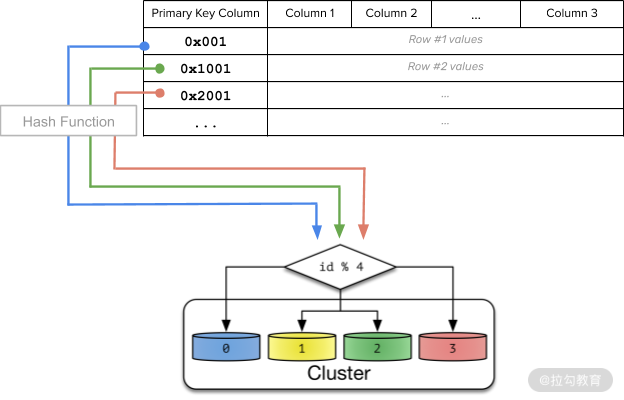
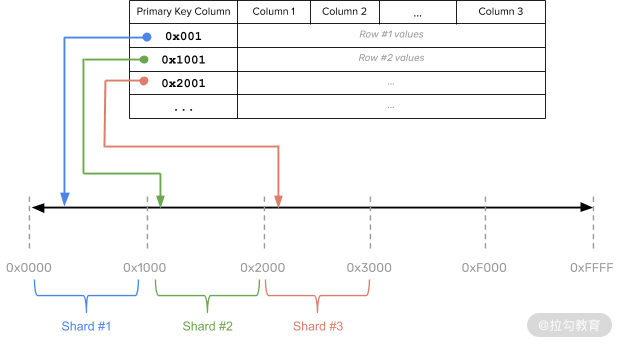
范围分片
分布式 ID
UUID:性能较差,且离散度不高
雪花算法
数据复制:如何保证数据在分布式场景下的高可用?
主从复制
- 复制同步模式
- 同步复制:如果由于从库已崩溃,存在网络故障或其他原因而没有响应,则主库也无法写入该数据。
- 半同步复制:其中部分从库进行同步复制,而其他从库进行异步复制。也就是,如果其中一个从库同步确认,主库可以写入该数据。
- 异步复制:不管从库的复制情况如何,主库可以写入该数据。而此时,如果主库失效,那么还未同步到从库的数据就会丢失。
- 复制延迟 - 提高系统的查询性能,可以通过添加从节点来实现。但是如果使用同步复制,每次写入都需要同步所有从节点,会造成一部分从节点已经有数据,但是主节点还没写入数据。而异步复制的问题是从节点的数据可能不是最新的。
- 复制与高可用性
- 从节点故障。由于每个节点都复制了从主库那里收到的数据更改日志,因此它知道在发生故障之前已处理的最后一个事务,由此可以凭借此信息从主节点或其他从节点那里恢复自己的数据。
- 主节点故障。在这种情况下,需要在从节点中选择一个成为新的主节点,此过程称为故障转移,可以手动或自动触发。其典型过程为:第一步根据超时时间确定主节点离线;第二步选择新的主节点,这里注意新的主节点通常应该与旧的主节点数据最为接近;第三步是重置系统,让它成为新的主节点。
- 复制方式
- 基于语句的复制:主库记录它所执行的每个写请求(一般以 SQL 语句形式保存),每个从库解析并执行该语句,就像从客户端收到该语句一样。但这种复制会有一些潜在问题,如语句使用了获取当前时间的函数,复制后会在不同数据节点上产生不同的值。另外如自增列、触发器、存储过程和函数都可能在复制后产生意想不到的问题。但可以通过预处理规避这些问题。使用该复制方式的分布式数据库有 VoltDB、Calvin。
- 日志(WAL)同步:WAL 是一组字节序列,其中包含对数据库的所有写操作。它的内容是一组低级操作,如向磁盘的某个页面的某个数据块写入一段二进制数据,主库通过网络将这样的数据发送给从库。这种方法避免了上面提到的语句中部分操作复制后产生的一些副作用,但要求主从的数据库引擎完全一致,最好版本也要一致。如果要升级从库版本,那么就需要计划外停机。PostgreSQL 和 Oracle 中使用了此方法。
- 行复制:它由一系列记录组成,这些记录描述了以行的粒度对数据库表进行的写操作。它与特定存储引擎解耦,并且第三方应用可以很容易解析其数据格式。
- ETL 工具:该功能一般是最灵活的方式。用户可以根据自己的业务来设计复制的范围和机制,同时在复制过程中还可以进行如过滤、转换和压缩等操作。但性能一般较低,故适合处理子数据集的场景。
一致性与 CAP 模型:为什么需要分布式一致性?
略
实践:设计一个最简单的分布式数据库
略
概要:什么是存储引擎,为什么需要了解它?
存储引擎
数据库的一般架构
- 传输层:它是接受客户端请求的一层。用来处理网络协议。同时,在分布式数据库中,它还承担着节点间互相通信的职责。
- 查询层:请求从传输层被发送到查询层。在查询层,协议被进行解析,如 SQL 解析;后进行验证与分析;最后结合访问控制来决定该请求是否要被执行。解析完成后,请求被发送到查询优化器,在这里根据预制的规则,数据分布并结合数据库内部的统计,会生成该请求的执行计划。执行计划一般是树状的,包含一系列相关的操作,用于从数据库中查询到请求希望获取的数据。
- 执行层:执行计划被发送到执行层去运行。执行层一般包含本地运行单元与远程运行单元。根据执行计划,调用不同的单元,而后将结果合并返回到传输层。执行层本地运行单元其实就是存储引擎。它一般包含如下一些功能
- 事务管理器:用来调度事务并保证数据库的内部一致性(这与模块一中讨论的分布式一致性是不同的);
- 锁管理:保证操作共享对象时候的一致性,包括事务、修改数据库参数都会使用到它;
- 存储结构:包含各种物理存储层,描述了数据与索引是如何组织在磁盘上的;
- 内存结构:主要包含缓存与缓冲管理,数据一般是批量输入磁盘的,写入之前会使用内存去缓存数据;
- 提交日志:当数据库崩溃后,可以使用提交日志恢复系统的一致性状态。
内存与磁盘
内存特点:查询快、更昂贵、持久化比较复杂
行式存储与列式存储
列式存储非常适合处理分析聚合类型的任务,如计算数据趋势、平均值,等等。因为这些数据一般需要加载一列的所有行,而不关心的列数据不会被读取,从而获得了更高的性能。
数据文件与索引文件
数据文件最传统的形式为堆组织表(Heap-Organized Table),数据的放置没有一个特别的顺序,一般是按照写入的先后顺序排布。这种数据文件需要一定额外的索引帮助来查找数据。
索引文件的分类模式一般为主键索引与二级索引两类。前者是建立在主键上的,它可能是一个字段或多个字段组成。而其他类型的索引都被称为二级索引。主键索引与数据是一对一关系,而二级索引很有可能是一对多的关系,即多个索引条目指向一条数据。
面向分布式的存储引擎特点
内存型数据库会倾向于选择分布式模式来进行构建。原因也是显而易见的,由于单机内存容量相比磁盘来说是很小的,故需要构建分布式数据库来满足业务所需要的容量。
列式存储也与分布式数据库存在天然的联系。原因是针对 OLAP 的分析数据库,一个非常大的应用场景就是要分析所有数据。
分布式索引:如何在集群中快速定位数据?
读取路径
存储引擎处理查询请求一般流程:
- 寻找分片和目标节点;
- 检查数据是否在缓存与缓冲中;
- 检查数据是否在磁盘文件中;
- 合并结果。
索引数据表
SSTable 文件是一个排序的、不可变的、持久化的键值对结构,其中键值对可以是任意字节的字符串,支持使用指定键来查找值,或通过给定键范围遍历所有的键值对。每个 SSTable 文件包含一系列的块。SSTable 文件中的块索引(这些块索引通常保存在文件尾部区域)用于定位块,这些块索引在 SSTable 文件被打开时加载到内存。在查找时首先从内存中的索引二分查找找到块,然后一次磁盘寻道即可读取到相应的块。另一种方式是将 SSTable 文件完全加载到内存,从而在查找和扫描中就不需要读取磁盘。
内存缓冲
内存中常用的快速搜索数据结构是跳表。典型代表:Redis 使用跳表实现 zset。