JVM 命令行工具
JVM 命令行工具
Java 程序员免不了故障排查工作,所以经常需要使用一些 JVM 工具。
JDK 自带了一些实用的命令行工具来监控、分析 JVM 信息,掌握它们,非常有助于 TroubleShooting。
以下是较常用的 JDK 命令行工具:
| 名称 | 描述 |
|---|---|
jps | JVM 进程状态工具。显示系统内的所有 JVM 进程。 |
jstat | JVM 统计监控工具。监控虚拟机运行时状态信息,它可以显示出 JVM 进程中的类装载、内存、GC、JIT 编译等运行数据。 |
jmap | JVM 堆内存分析工具。用于打印 JVM 进程对象直方图、类加载统计。并且可以生成堆转储快照(一般称为 heapdump 或 dump 文件)。 |
jstack | JVM 栈查看工具。用于打印 JVM 进程的线程和锁的情况。并且可以生成线程快照(一般称为 threaddump 或 javacore 文件)。 |
jhat | 用来分析 jmap 生成的 dump 文件。 |
jinfo | JVM 信息查看工具。用于实时查看和调整 JVM 进程参数。 |
jcmd | JVM 命令行调试 工具。用于向 JVM 进程发送调试命令。 |
jps
jps(JVM Process Status Tool) 是虚拟机进程状态工具。它可以显示指定系统内所有的 HotSpot 虚拟机进程状态信息。jps 通过 RMI 协议查询开启了 RMI 服务的远程虚拟机进程状态。
jps 命令用法
jps [option] [hostid]
jps [-help]
如果不指定 hostid 就默认为当前主机或服务器。
常用参数:
option- 选项参数-m- 输出 JVM 启动时传递给 main() 的参数。-l- 输出主类的全名,如果进程执行的是 jar 包,输出 jar 路径。-v- 显示传递给 JVM 的参数。-q- 仅输出本地 JVM 进程 ID。-V- 仅输出本地 JVM 标识符。
hostid- RMI 注册表中注册的主机名。如果不指定 hostid 就默认为当前主机或服务器。
其中 option、hostid 参数也可以不写。
jps 使用示例
【示例】列出本地 Java 进程
$ jps
18027 Java2Demo.JAR
18032 jps
18005 jstat
【示例】列出本地 Java 进程 ID
$ jps -q
8841
1292
5398
【示例】列出本地 Java 进程 ID,并输出主类的全名,如果进程执行的是 jar 包,输出 jar 路径
$ jps -l remote.domain
3002 /opt/jdk1.7.0/demo/jfc/Java2D/Java2Demo.JAR
2857 sun.tools.jstatd.jstatd
jstat
jstat(JVM statistics Monitoring),是虚拟机统计信息监视工具。jstat 用于监视虚拟机运行时状态信息,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT 编译等运行数据。
jstat 命令用法
命令格式:
jstat [option] VMID [interval] [count]
常用参数:
option- 选项参数,用于指定用户需要查询的虚拟机信息-class- 监视类装载、卸载数量、总空间以及类装载所耗费的时间-compiler:显示 JIT 编译的相关信息;-gc:监视 Java 堆状况,包括 Eden 区、两个 survivor 区、老年代、永久代等区的容量、已用空间、GC 时间合计等信息。-gccapacity:显示各个代的容量以及使用情况;-gcmetacapacity:显示 Metaspace 的大小;-gcnew:显示新生代信息;-gcnewcapacity:显示新生代大小和使用情况;-gcold:显示老年代和永久代的信息;-gcoldcapacity:显示老年代的大小;-gcutil:显示垃圾回收统计信息;-gccause:显示垃圾回收的相关信息(通 -gcutil),同时显示最后一次或当前正在发生的垃圾回收的诱因;-printcompilation:输出 JIT 编译的方法信息。
VMID- 如果是本地虚拟机进程,则 VMID 与 LVMID 是一致的;如果是远程虚拟机进程,那 VMID 的格式应当是:[protocol:][//]lvmid[@hostname[:port]/servername]interval- 查询间隔count- 查询次数
【参考】更详细说明可以参考:jstat 命令查看 jvm 的 GC 情况
jstat 使用示例
类加载统计
使用 jstat -class pid 命令可以查看编译统计信息。
【参数】
- Loaded - 加载 class 的数量
- Bytes - 所占用空间大小
- Unloaded - 未加载数量
- Bytes - 未加载占用空间
- Time - 时间
【示例】查看类加载信息
$ jstat -class 7129
Loaded Bytes Unloaded Bytes Time
26749 50405.3 873 1216.8 19.75
编译统计
使用 jstat -compiler pid 命令可以查看编译统计信息。
【示例】
$ jstat -compiler 7129
Compiled Failed Invalid Time FailedType FailedMethod
42030 2 0 302.53 1 org/apache/felix/framework/BundleWiringImpl$BundleClassLoader findClass
【参数】
- Compiled - 编译数量
- Failed - 失败数量
- Invalid - 不可用数量
- Time - 时间
- FailedType - 失败类型
- FailedMethod - 失败的方法
GC 统计
使用 jstat -gc pid time 命令可以查看 GC 统计信息。
【示例】以 250 毫秒的间隔进行 7 个采样,并显示-gcutil 选项指定的输出。
$ jstat -gcutil 21891 250 7
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 97.02 70.31 66.80 95.52 89.14 7 0.300 0 0.000 0.300
0.00 97.02 86.23 66.80 95.52 89.14 7 0.300 0 0.000 0.300
0.00 97.02 96.53 66.80 95.52 89.14 7 0.300 0 0.000 0.300
91.03 0.00 1.98 68.19 95.89 91.24 8 0.378 0 0.000 0.378
91.03 0.00 15.82 68.19 95.89 91.24 8 0.378 0 0.000 0.378
91.03 0.00 17.80 68.19 95.89 91.24 8 0.378 0 0.000 0.378
91.03 0.00 17.80 68.19 95.89 91.24 8 0.378 0 0.000 0.378
【示例】以 1 秒的间隔进行 4 个采样,并显示-gc 选项指定的输出。
$ jstat -gc 25196 1s 4
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
20928.0 20928.0 0.0 0.0 167936.0 8880.5 838912.0 80291.2 106668.0 100032.1 12772.0 11602.2 760 14.332 580 656.218 670.550
20928.0 20928.0 0.0 0.0 167936.0 8880.5 838912.0 80291.2 106668.0 100032.1 12772.0 11602.2 760 14.332 580 656.218 670.550
20928.0 20928.0 0.0 0.0 167936.0 8880.5 838912.0 80291.2 106668.0 100032.1 12772.0 11602.2 760 14.332 580 656.218 670.550
20928.0 20928.0 0.0 0.0 167936.0 8880.5 838912.0 80291.2 106668.0 100032.1 12772.0 11602.2 760 14.332 580 656.218 670.550
参数说明:
S0C:年轻代中 To Survivor 的容量(单位 KB);S1C:年轻代中 From Survivor 的容量(单位 KB);S0U:年轻代中 To Survivor 目前已使用空间(单位 KB);S1U:年轻代中 From Survivor 目前已使用空间(单位 KB);EC:年轻代中 Eden 的容量(单位 KB);EU:年轻代中 Eden 目前已使用空间(单位 KB);OC:Old 代的容量(单位 KB);OU:Old 代目前已使用空间(单位 KB);MC:Metaspace 的容量(单位 KB);MU:Metaspace 目前已使用空间(单位 KB);YGC:从应用程序启动到采样时年轻代中 gc 次数;YGCT:从应用程序启动到采样时年轻代中 gc 所用时间 (s);FGC:从应用程序启动到采样时 old 代(全 gc)gc 次数;FGCT:从应用程序启动到采样时 old 代(全 gc)gc 所用时间 (s);GCT:从应用程序启动到采样时 gc 用的总时间 (s)。
注:更详细的参数含义可以参考官方文档:http://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html
jmap
jmap(JVM Memory Map) 是 Java 内存映像工具。jmap 用于生成堆转储快照(一般称为 heapdump 或 dump 文件)。jmap 不仅能生成 dump 文件,还可以查询
finalize执行队列、Java 堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。如果不使用这个命令,还可以使用
-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现 OOM 的时候,自动生成 dump 文件。
jmap 命令用法
命令格式:
jmap [option] pid
option 选项参数:
-dump- 生成堆转储快照。-dump:live只保存堆中的存活对象。-finalizerinfo- 显示在 F-Queue 队列等待执行finalizer方法的对象-heap- 显示 Java 堆详细信息。-histo- 显示堆中对象的统计信息,包括类、实例数量、合计容量。-histo:live只统计堆中的存活对象。-permstat- to print permanent generation statistics-F- 当-dump 没有响应时,强制生成 dump 快照
jstat 使用示例
生成 heapdump 快照
dump 堆到文件,format 指定输出格式,live 指明是活着的对象,file 指定文件名
$ jmap -dump:live,format=b,file=dump.hprof 28920
Dumping heap to /home/xxx/dump.hprof ...
Heap dump file created
dump.hprof 这个后缀是为了后续可以直接用 MAT(Memory Anlysis Tool)等工具打开。
查看实例数最多的类
$ jmap -histo 29527 | head -n 6
num #instances #bytes class name
----------------------------------------------
1: 13673280 1438961864 [C
2: 1207166 411277184 [I
3: 7382322 347307096 [Ljava.lang.Object;
查看指定进程的堆信息
注意:使用 CMS GC 情况下,jmap -heap PID 的执行有可能会导致 java 进程挂起。
$ jmap -heap 12379
Attaching to process ID 12379, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 17.0-b16
using thread-local object allocation.
Parallel GC with 6 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 83886080 (80.0MB)
NewSize = 1310720 (1.25MB)
MaxNewSize = 17592186044415 MB
OldSize = 5439488 (5.1875MB)
NewRatio = 2
SurvivorRatio = 8
PermSize = 20971520 (20.0MB)
MaxPermSize = 88080384 (84.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 9306112 (8.875MB)
used = 5375360 (5.1263427734375MB)
free = 3930752 (3.7486572265625MB)
57.761608714788736% used
From Space:
capacity = 9306112 (8.875MB)
used = 3425240 (3.2665634155273438MB)
free = 5880872 (5.608436584472656MB)
36.80634834397007% used
To Space:
capacity = 9306112 (8.875MB)
used = 0 (0.0MB)
free = 9306112 (8.875MB)
0.0% used
PS Old Generation
capacity = 55967744 (53.375MB)
used = 48354640 (46.11457824707031MB)
free = 7613104 (7.2604217529296875MB)
86.39733629427693% used
PS Perm Generation
capacity = 62062592 (59.1875MB)
used = 60243112 (57.452308654785156MB)
free = 1819480 (1.7351913452148438MB)
97.06831451706046% used
jstack
jstack(Stack Trace for java) 是 Java 堆栈跟踪工具。jstack 用来打印目标 Java 进程中各个线程的栈轨迹,以及这些线程所持有的锁,并可以生成 java 虚拟机当前时刻的线程快照(一般称为 threaddump 或 javacore 文件)。
线程快照是当前虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
jstack 通常会结合 top -Hp pid 或 pidstat -p pid -t 一起查看具体线程的状态,也经常用来排查一些死锁的异常。
线程出现停顿的时候通过 jstack 来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。 如果 java 程序崩溃生成 core 文件,jstack 工具可以用来获得 core 文件的 java stack 和 native stack 的信息,从而可以轻松地知道 java 程序是如何崩溃和在程序何处发生问题。另外,jstack 工具还可以附属到正在运行的 java 程序中,看到当时运行的 java 程序的 java stack 和 native stack 的信息, 如果现在运行的 java 程序呈现 hung 的状态,jstack 是非常有用的。
jstack 命令用法
命令格式:
jstack [option] pid
option 选项参数
-F- 当正常输出请求不被响应时,强制输出线程堆栈-l- 除堆栈外,显示关于锁的附加信息-m- 打印 java 和 jni 框架的所有栈信息
thread dump 文件

一个 Thread Dump 文件大致可以分为五个部分。
第一部分:Full thread dump identifier
这一部分是内容最开始的部分,展示了快照文件的生成时间和 JVM 的版本信息。
2017-10-19 10:46:44
Full thread dump Java HotSpot(TM) 64-Bit Server VM (24.79-b02 mixed mode):
第二部分:Java EE middleware, third party & custom application Threads
这是整个文件的核心部分,里面展示了 JavaEE 容器(如 tomcat、resin 等)、自己的程序中所使用的线程信息。
"resin-22129" daemon prio=10 tid=0x00007fbe5c34e000 nid=0x4cb1 waiting on condition [0x00007fbe4ff7c000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:315)
at com.caucho.env.thread2.ResinThread2.park(ResinThread2.java:196)
at com.caucho.env.thread2.ResinThread2.runTasks(ResinThread2.java:147)
at com.caucho.env.thread2.ResinThread2.run(ResinThread2.java:118)
参数说明:
"resin-22129"**线程名称:**如果使用 java.lang.Thread 类生成一个线程的时候,线程名称为 Thread-(数字) 的形式,这里是 resin 生成的线程;daemon**线程类型:**线程分为守护线程 (daemon) 和非守护线程 (non-daemon) 两种,通常都是守护线程;prio=10**线程优先级:**默认为 5,数字越大优先级越高;tid=0x00007fbe5c34e000**JVM 线程的 id:**JVM 内部线程的唯一标识,通过 java.lang.Thread.getId()获取,通常用自增的方式实现;nid=0x4cb1**系统线程 id:**对应的系统线程 id(Native Thread ID),可以通过 top 命令进行查看,现场 id 是十六进制的形式;waiting on condition**系统线程状态:**这里是系统的线程状态;[0x00007fbe4ff7c000]**起始栈地址:**线程堆栈调用的其实内存地址;java.lang.Thread.State: WAITING (parking)**JVM 线程状态:**这里标明了线程在代码级别的状态。- **线程调用栈信息:**下面就是当前线程调用的详细栈信息,用于代码的分析。堆栈信息应该从下向上解读,因为程序调用的顺序是从下向上的。
第三部分:HotSpot VM Thread
这一部分展示了 JVM 内部线程的信息,用于执行内部的原生操作。下面常见的集中内置线程:
"Attach Listener"
该线程负责接收外部命令,执行该命令并把结果返回给调用者,此种类型的线程通常在桌面程序中出现。
"Attach Listener" daemon prio=5 tid=0x00007fc6b6800800 nid=0x3b07 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"DestroyJavaVM"
执行 main() 的线程在执行完之后调用 JNI 中的 jni_DestroyJavaVM() 方法会唤起 DestroyJavaVM 线程,处于等待状态,等待其它线程(java 线程和 native 线程)退出时通知它卸载 JVM。
"DestroyJavaVM" prio=5 tid=0x00007fc6b3001000 nid=0x1903 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Service Thread"
用于启动服务的线程
"Service Thread" daemon prio=10 tid=0x00007fbea81b3000 nid=0x5f2 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"CompilerThread"
用来调用 JITing,实时编译装卸类。通常 JVM 会启动多个线程来处理这部分工作,线程名称后面的数字也会累加,比如 CompilerThread1。
"C2 CompilerThread1" daemon prio=10 tid=0x00007fbea814b000 nid=0x5f1 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread0" daemon prio=10 tid=0x00007fbea8142000 nid=0x5f0 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Signal Dispatcher"
Attach Listener 线程的职责是接收外部 jvm 命令,当命令接收成功后,会交给 signal dispather 线程去进行分发到各个不同的模块处理命令,并且返回处理结果。
signal dispather 线程也是在第一次接收外部 jvm 命令时,进行初始化工作。
"Signal Dispatcher" daemon prio=10 tid=0x00007fbea81bf800 nid=0x5ef runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Finalizer"
这个线程也是在 main 线程之后创建的,其优先级为 10,主要用于在垃圾收集前,调用对象的 finalize() 方法;关于 Finalizer 线程的几点:
- 只有当开始一轮垃圾收集时,才会开始调用 finalize()方法;因此并不是所有对象的 finalize()方法都会被执行;
- 该线程也是 daemon 线程,因此如果虚拟机中没有其他非 daemon 线程,不管该线程有没有执行完 finalize()方法,JVM 也会退出;
- JVM 在垃圾收集时会将失去引用的对象包装成 Finalizer 对象(Reference 的实现),并放入 ReferenceQueue,由 Finalizer 线程来处理;最后将该 Finalizer 对象的引用置为 null,由垃圾收集器来回收;
JVM 为什么要单独用一个线程来执行 finalize() 方法呢?
如果 JVM 的垃圾收集线程自己来做,很有可能由于在 finalize()方法中误操作导致 GC 线程停止或不可控,这对 GC 线程来说是一种灾难。
"Finalizer" daemon prio=10 tid=0x00007fbea80da000 nid=0x5eb in Object.wait() [0x00007fbeac044000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:135)
- locked <0x00000006d173c1a8> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:151)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)
"Reference Handler"
JVM 在创建 main 线程后就创建 Reference Handler 线程,其优先级最高,为 10,它主要用于处理引用对象本身(软引用、弱引用、虚引用)的垃圾回收问题 。
"Reference Handler" daemon prio=10 tid=0x00007fbea80d8000 nid=0x5ea in Object.wait() [0x00007fbeac085000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:503)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:133)
- locked <0x00000006d173c1f0> (a java.lang.ref.Reference$Lock)
"VM Thread"
JVM 中线程的母体,根据 HotSpot 源码中关于 vmThread.hpp 里面的注释,它是一个单例的对象(最原始的线程)会产生或触发所有其他的线程,这个单例的 VM 线程是会被其他线程所使用来做一些 VM 操作(如清扫垃圾等)。
在 VM Thread 的结构体里有一个 VMOperationQueue 列队,所有的 VM 线程操作(vm_operation)都会被保存到这个列队当中,VMThread 本身就是一个线程,它的线程负责执行一个自轮询的 loop 函数(具体可以参考:VMThread.cpp 里面的 void VMThread::loop()) ,该 loop 函数从 VMOperationQueue 列队中按照优先级取出当前需要执行的操作对象(VM_Operation),并且调用 VM_Operation->evaluate 函数去执行该操作类型本身的业务逻辑。
VM 操作类型被定义在 vm_operations.hpp 文件内,列举几个:ThreadStop、ThreadDump、PrintThreads、GenCollectFull、GenCollectFullConcurrent、CMS_Initial_Mark、CMS_Final_Remark….. 有兴趣的同学,可以自己去查看源文件。
"VM Thread" prio=10 tid=0x00007fbea80d3800 nid=0x5e9 runnable
第四部分:HotSpot GC Thread
JVM 中用于进行资源回收的线程,包括以下几种类型的线程:
"VM Periodic Task Thread"
该线程是 JVM 周期性任务调度的线程,它由 WatcherThread 创建,是一个单例对象。该线程在 JVM 内使用得比较频繁,比如:定期的内存监控、JVM 运行状况监控。
"VM Periodic Task Thread" prio=10 tid=0x00007fbea82ae800 nid=0x5fa waiting on condition
可以使用 jstat 命令查看 GC 的情况,比如查看某个进程没有存活必要的引用可以使用命令 jstat -gcutil 250 7 参数中 pid 是进程 id,后面的 250 和 7 表示每 250 毫秒打印一次,总共打印 7 次。
这对于防止因为应用代码中直接使用 native 库或者第三方的一些监控工具的内存泄漏有非常大的帮助。
"GC task thread#0 (ParallelGC)"
垃圾回收线程,该线程会负责进行垃圾回收。通常 JVM 会启动多个线程来处理这个工作,线程名称中#后面的数字也会累加。
"GC task thread#0 (ParallelGC)" prio=5 tid=0x00007fc6b480d000 nid=0x2503 runnable
"GC task thread#1 (ParallelGC)" prio=5 tid=0x00007fc6b2812000 nid=0x2703 runnable
"GC task thread#2 (ParallelGC)" prio=5 tid=0x00007fc6b2812800 nid=0x2903 runnable
"GC task thread#3 (ParallelGC)" prio=5 tid=0x00007fc6b2813000 nid=0x2b03 runnable
如果在 JVM 中增加了 -XX:+UseConcMarkSweepGC 参数将会启用 CMS (Concurrent Mark-Sweep)GC Thread 方式,以下是该模式下的线程类型:
"Gang worker#0 (Parallel GC Threads)"
原来垃圾回收线程 GC task thread#0 (ParallelGC) 被替换为 Gang worker#0 (Parallel GC Threads)。Gang worker 是 JVM 用于年轻代垃圾回收(minor gc)的线程。
"Gang worker#0 (Parallel GC Threads)" prio=10 tid=0x00007fbea801b800 nid=0x5e4 runnable
"Gang worker#1 (Parallel GC Threads)" prio=10 tid=0x00007fbea801d800 nid=0x5e7 runnable
"Concurrent Mark-Sweep GC Thread"
并发标记清除垃圾回收器(就是通常所说的 CMS GC)线程, 该线程主要针对于年老代垃圾回收。
"Concurrent Mark-Sweep GC Thread" prio=10 tid=0x00007fbea8073800 nid=0x5e8 runnable
"Surrogate Locker Thread (Concurrent GC)"
此线程主要配合 CMS 垃圾回收器来使用,是一个守护线程,主要负责处理 GC 过程中 Java 层的 Reference(指软引用、弱引用等等)与 jvm 内部层面的对象状态同步。
"Surrogate Locker Thread (Concurrent GC)" daemon prio=10 tid=0x00007fbea8158800 nid=0x5ee waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
这里以 WeakHashMap 为例进行说明,首先是一个关键点:
- WeakHashMap 和 HashMap 一样,内部有一个 Entry[]数组;
- WeakHashMap 的 Entry 比较特殊,它的继承体系结构为 Entry->WeakReference->Reference;
- Reference 里面有一个全局锁对象:Lock,它也被称为 pending_lock,注意:它是静态对象;
- Reference 里面有一个静态变量:pending;
- Reference 里面有一个静态内部类:ReferenceHandler 的线程,它在 static 块里面被初始化并且启动,启动完成后处于 wait 状态,它在一个 Lock 同步锁模块中等待;
- WeakHashMap 里面还实例化了一个 ReferenceQueue 列队
假设,WeakHashMap 对象里面已经保存了很多对象的引用,JVM 在进行 CMS GC 的时候会创建一个 ConcurrentMarkSweepThread(简称 CMST)线程去进行 GC。ConcurrentMarkSweepThread 线程被创建的同时会创建一个 SurrogateLockerThread(简称 SLT)线程并且启动它,SLT 启动之后,处于等待阶段。
CMST 开始 GC 时,会发一个消息给 SLT 让它去获取 Java 层 Reference 对象的全局锁:Lock。直到 CMS GC 完毕之后,JVM 会将 WeakHashMap 中所有被回收的对象所属的 WeakReference 容器对象放入到 Reference 的 pending 属性当中(每次 GC 完毕之后,pending 属性基本上都不会为 null 了),然后通知 SLT 释放并且 notify 全局锁:Lock。此时激活了 ReferenceHandler 线程的 run 方法,使其脱离 wait 状态,开始工作了。
ReferenceHandler 这个线程会将 pending 中的所有 WeakReference 对象都移动到它们各自的列队当中,比如当前这个 WeakReference 属于某个 WeakHashMap 对象,那么它就会被放入相应的 ReferenceQueue 列队里面(该列队是链表结构)。 当我们下次从 WeakHashMap 对象里面 get、put 数据或者调用 size 方法的时候,WeakHashMap 就会将 ReferenceQueue 列队中的 WeakReference 依依 poll 出来去和 Entry[]数据做比较,如果发现相同的,则说明这个 Entry 所保存的对象已经被 GC 掉了,那么将 Entry[]内的 Entry 对象剔除掉。
第五部分:JNI global references count
这一部分主要回收那些在 native 代码上被引用,但在 java 代码中却没有存活必要的引用,对于防止因为应用代码中直接使用 native 库或第三方的一些监控工具的内存泄漏有非常大的帮助。
JNI global references: 830
下一篇文章将要讲述一个直接找出 CPU 100% 线程的例子。
系统线程状态
系统线程有如下状态:
deadlock
死锁线程,一般指多个线程调用期间进入了相互资源占用,导致一直等待无法释放的情况。
【示例】deadlock 示例
"DEADLOCK_TEST-1" daemon prio=6 tid=0x000000000690f800 nid=0x1820 waiting for monitor entry [0x000000000805f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197)
- waiting to lock <0x00000007d58f5e60> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182)
- locked <0x00000007d58f5e48> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
Locked ownable synchronizers:
- None
"DEADLOCK_TEST-2" daemon prio=6 tid=0x0000000006858800 nid=0x17b8 waiting for monitor entry [0x000000000815f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197)
- waiting to lock <0x00000007d58f5e78> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182)
- locked <0x00000007d58f5e60> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
Locked ownable synchronizers:
- None
"DEADLOCK_TEST-3" daemon prio=6 tid=0x0000000006859000 nid=0x25dc waiting for monitor entry [0x000000000825f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197)
- waiting to lock <0x00000007d58f5e48> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182)
- locked <0x00000007d58f5e78> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
Locked ownable synchronizers:
- None
runnable
一般指该线程正在执行状态中,该线程占用了资源,正在处理某个操作,如通过 SQL 语句查询数据库、对某个文件进行写入等。
blocked
线程正处于阻塞状态,指当前线程执行过程中,所需要的资源长时间等待却一直未能获取到,被容器的线程管理器标识为阻塞状态,可以理解为等待资源超时的线程。
【示例】blocked 示例
"BLOCKED_TEST pool-1-thread-2" prio=6 tid=0x0000000007673800 nid=0x260c waiting for monitor entry [0x0000000008abf000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadBlockedState.monitorLock(ThreadBlockedState.java:43)
- waiting to lock <0x0000000780a000b0> (a com.nbp.theplatform.threaddump.ThreadBlockedState)
at com.nbp.theplatform.threaddump.ThreadBlockedState$2.run(ThreadBlockedState.java:26)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:662)
Locked ownable synchronizers:
- <0x0000000780b0c6a0> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
"BLOCKED_TEST pool-1-thread-3" prio=6 tid=0x00000000074f5800 nid=0x1994 waiting for monitor entry [0x0000000008bbf000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadBlockedState.monitorLock(ThreadBlockedState.java:42)
- waiting to lock <0x0000000780a000b0> (a com.nbp.theplatform.threaddump.ThreadBlockedState)
at com.nbp.theplatform.threaddump.ThreadBlockedState$3.run(ThreadBlockedState.java:34)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:662)
Locked ownable synchronizers:
- <0x0000000780b0e1b8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
waiting on condition
线程正处于等待资源或等待某个条件的发生,具体的原因需要结合下面堆栈信息进行分析。
(1)如果堆栈信息明确是应用代码,则证明该线程正在等待资源,一般是大量读取某种资源且该资源采用了资源锁的情况下,线程进入等待状态,等待资源的读取,或者正在等待其他线程的执行等。
(2)如果发现有大量的线程都正处于这种状态,并且堆栈信息中得知正等待网络读写,这是因为网络阻塞导致线程无法执行,很有可能是一个网络瓶颈的征兆:
网络非常繁忙,几乎消耗了所有的带宽,仍然有大量数据等待网络读写;
网络可能是空闲的,但由于路由或防火墙等原因,导致包无法正常到达;
所以一定要结合系统的一些性能观察工具进行综合分析,比如 netstat 统计单位时间的发送包的数量,看是否很明显超过了所在网络带宽的限制;观察 CPU 的利用率,看系统态的 CPU 时间是否明显大于用户态的 CPU 时间。这些都指向由于网络带宽所限导致的网络瓶颈。
(3)还有一种常见的情况是该线程在 sleep,等待 sleep 的时间到了,将被唤醒。
【示例】等待状态样例
"IoWaitThread" prio=6 tid=0x0000000007334800 nid=0x2b3c waiting on condition [0x000000000893f000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007d5c45850> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:156)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1987)
at java.util.concurrent.LinkedBlockingDeque.takeFirst(LinkedBlockingDeque.java:440)
at java.util.concurrent.LinkedBlockingDeque.take(LinkedBlockingDeque.java:629)
at com.nbp.theplatform.threaddump.ThreadIoWaitState$IoWaitHandler2.run(ThreadIoWaitState.java:89)
at java.lang.Thread.run(Thread.java:662)
waiting for monitor entry 或 in Object.wait()
Moniter 是 Java 中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者 class 的锁,每个对象都有,也仅有一个 Monitor。
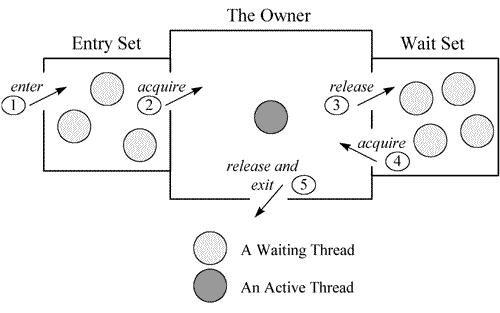
从上图可以看出,每个 Monitor 在某个时刻只能被一个线程拥有,该线程就是 "Active Thread",而其他线程都是 "Waiting Thread",分别在两个队列 "Entry Set"和"Waint Set"里面等待。其中在 "Entry Set" 中等待的线程状态是 waiting for monitor entry,在 "Wait Set" 中等待的线程状态是 in Object.wait()。
(1)"Entry Set"里面的线程。
我们称被 synchronized 保护起来的代码段为临界区,对应的代码如下:
synchronized(obj) {
}
当一个线程申请进入临界区时,它就进入了 "Entry Set" 队列中,这时候有两种可能性:
- 该 Monitor 不被其他线程拥有,"Entry Set"里面也没有其他等待的线程。本线程即成为相应类或者对象的 Monitor 的 Owner,执行临界区里面的代码;此时在 Thread Dump 中显示线程处于 "Runnable" 状态。
- 该 Monitor 被其他线程拥有,本线程在 "Entry Set" 队列中等待。此时在 Thread Dump 中显示线程处于 "waiting for monity entry" 状态。
临界区的设置是为了保证其内部的代码执行的原子性和完整性,但因为临界区在任何时间只允许线程串行通过,这和我们使用多线程的初衷是相反的。如果在多线程程序中大量使用 synchronized,或者不适当的使用它,会造成大量线程在临界区的入口等待,造成系统的性能大幅下降。如果在 Thread Dump 中发现这个情况,应该审视源码并对其进行改进。
(2)"Wait Set"里面的线程
当线程获得了 Monitor,进入了临界区之后,如果发现线程继续运行的条件没有满足,它则调用对象(通常是被 synchronized 的对象)的 wait()方法,放弃 Monitor,进入 "Wait Set"队列。只有当别的线程在该对象上调用了 notify()或者 notifyAll()方法,"Wait Set"队列中的线程才得到机会去竞争,但是只有一个线程获得对象的 Monitor,恢复到运行态。"Wait Set"中的线程在 Thread Dump 中显示的状态为 in Object.wait()。通常来说,当 CPU 很忙的时候关注 Runnable 状态的线程,反之则关注 waiting for monitor entry 状态的线程。
jstack 使用示例
找出某 Java 进程中最耗费 CPU 的 Java 线程
(1)找出 Java 进程
假设应用名称为 myapp:
$ jps | grep myapp
29527 myapp.jar
得到进程 ID 为 21711
(2)找出该进程内最耗费 CPU 的线程,可以使用 ps -Lfp pid 或者 ps -mp pid -o THREAD, tid, time 或者 top -Hp pid
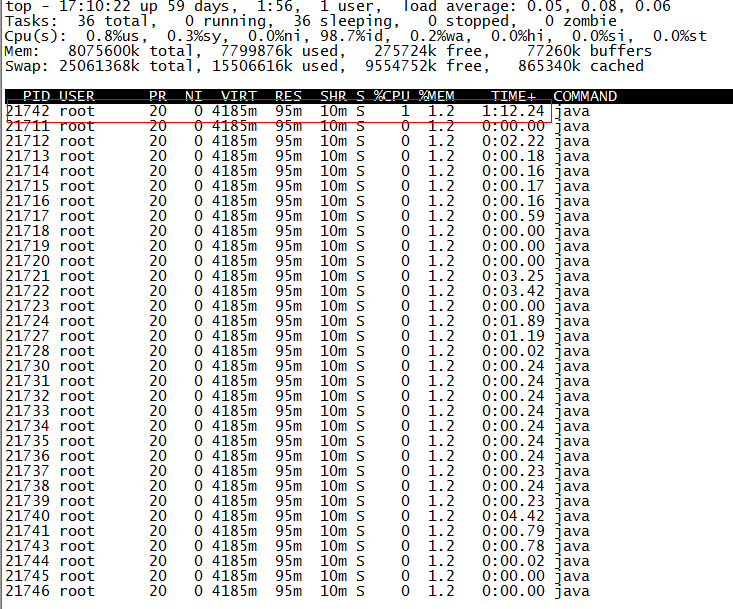
TIME 列就是各个 Java 线程耗费的 CPU 时间,CPU 时间最长的是线程 ID 为 21742 的线程,用
printf "%x\n" 21742
得到 21742 的十六进制值为 54ee,下面会用到。
(3)使用 jstack 打印线程堆栈信息
下一步终于轮到 jstack 上场了,它用来输出进程 21711 的堆栈信息,然后根据线程 ID 的十六进制值 grep,如下:
$ jstack 21711 | grep 54ee
"PollIntervalRetrySchedulerThread" prio=10 tid=0x00007f950043e000 nid=0x54ee in Object.wait() [0x00007f94c6eda000]
可以看到 CPU 消耗在 PollIntervalRetrySchedulerThread 这个类的 Object.wait()。
注:上面的例子中,默认只显示了一行信息,但很多时候我们希望查看更详细的调用栈。可以通过指定
-A <num>的方式来显示行数。例如:jstack -l <pid> | grep <thread-hex-id> -A 10
(4)分析代码
我找了下我的代码,定位到下面的代码:
// Idle wait
getLog().info("Thread [" + getName() + "] is idle waiting...");
schedulerThreadState = PollTaskSchedulerThreadState.IdleWaiting;
long now = System.currentTimeMillis();
long waitTime = now + getIdleWaitTime();
long timeUntilContinue = waitTime - now;
synchronized(sigLock) {
try {
if(!halted.get()) {
sigLock.wait(timeUntilContinue);
}
}
catch (InterruptedException ignore) {
}
}
它是轮询任务的空闲等待代码,上面的 sigLock.wait(timeUntilContinue) 就对应了前面的 Object.wait()。
生成 threaddump 文件
可以使用 jstack -l <pid> > <file-path> 命令生成 threaddump 文件
【示例】生成进程 ID 为 8841 的 Java 进程的 threaddump 文件。
jstack -l 8841 > /home/threaddump.txt
jinfo
jinfo(JVM Configuration info),是 Java 配置信息工具。jinfo 用于实时查看和调整虚拟机运行参数。如传递给 Java 虚拟机的
-X(即输出中的 jvm_args)、-XX参数(即输出中的 VM Flags),以及可在 Java 层面通过System.getProperty获取的-D参数(即输出中的 System Properties)。
之前的 jps -v 口令只能查看到显示指定的参数,如果想要查看未被显示指定的参数的值就要使用 jinfo 口令。
jinfo 命令格式:
jinfo [option] pid
option 选项参数:
-flag- 输出指定 args 参数的值-sysprops- 输出系统属性,等同于System.getProperties()
【示例】jinfo 使用示例
$ jinfo -sysprops 29527
Attaching to process ID 29527, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.222-b10
...
jhat
jhat(JVM Heap Analysis Tool),是虚拟机堆转储快照分析工具。jhat 与 jmap 搭配使用,用来分析 jmap 生成的 dump 文件。jhat 内置了一个微型的 HTTP/HTML 服务器,生成 dump 的分析结果后,可以在浏览器中查看。
注意:一般不会直接在服务器上进行分析,因为 jhat 是一个耗时并且耗费硬件资源的过程,一般把服务器生成的 dump 文件,用 jvisualvm 、Eclipse Memory Analyzer、IBM HeapAnalyzer 等工具来分析。
命令格式:
jhat [dumpfile]