Dubbo 面试
Dubbo 面试
Dubbo 的实现过程?
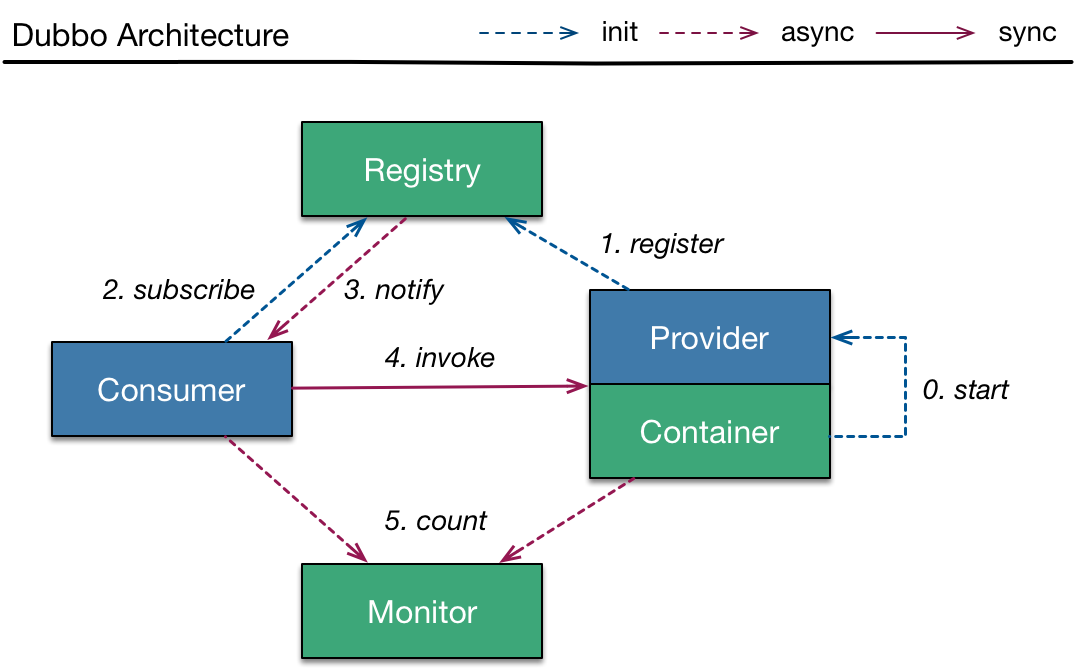
节点角色:
| 节点 | 角色说明 |
|---|---|
| Provider | 暴露服务的服务提供方 |
| Consumer | 调用远程服务的服务消费方 |
| Registry | 服务注册与发现的注册中心 |
| Monitor | 统计服务的调用次数和调用时间的监控中心 |
| Container | 服务运行容器 |
调用关系:
- 务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo 负载均衡策略有哪些?
Random
- 随机,按权重设置随机概率。
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
RoundRobin
- 轮循,按公约后的权重设置轮循比率。
- 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive
- 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash
- 一致性 Hash,相同参数的请求总是发到同一提供者。
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
- 算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
- 缺省只对第一个参数 Hash,如果要修改,请配置
<dubbo:parameter key="hash.arguments" value="0,1" /> - 缺省用 160 份虚拟节点,如果要修改,请配置
<dubbo:parameter key="hash.nodes" value="320" />
Dubbo 集群容错策略 ?
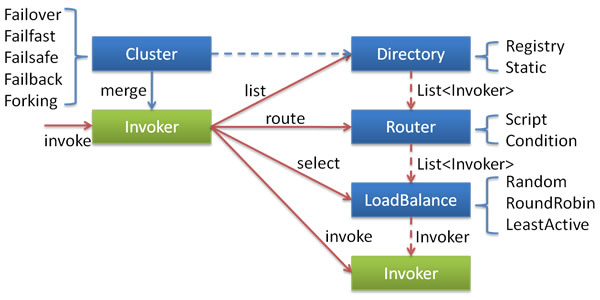
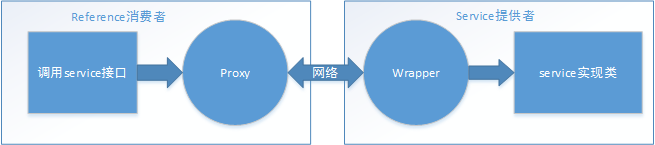
动态代理策略?
Dubbo 作为 RPC 框架,首先要完成的就是跨系统,跨网络的服务调用。消费方与提供方遵循统一的接口定义,消费方调用接口时,Dubbo 将其转换成统一格式的数据结构,通过网络传输,提供方根据规则找到接口实现,通过反射完成调用。也就是说,消费方获取的是对远程服务的一个代理(Proxy),而提供方因为要支持不同的接口实现,需要一个包装层(Wrapper)。调用的过程大概是这样:
@SPI("javassist")
public interface ProxyFactory {
@Adaptive({Constants.PROXY_KEY})
<T> T getProxy(Invoker<T> invoker) throws RpcException;
@Adaptive({Constants.PROXY_KEY})
<T> Invoker<T> getInvoker(T proxy, Class<T> type, URL url) throws RpcException;
}
ProxyFactory 有两种实现方式,一种是基于 JDK 的代理实现,一种是基于 javassist 的实现。ProxyFactory 接口上定义了@SPI("javassist"),默认为 javassist 的实现。
Dubbo 支持哪些序列化协议?Hessian?Hessian 的数据结构?
- dubbo 序列化,阿里尚不成熟的 java 序列化实现。
- hessian2 序列化:hessian 是一种跨语言的高效二进制的序列化方式,但这里实际不是原生的 hessian2 序列化,而是阿里修改过的 hessian lite,它是 dubbo RPC 默认启用的序列化方式。
- json 序列化:目前有两种实现,一种是采用的阿里的 fastjson 库,另一种是采用 dubbo 中自已实现的简单 json 库,一般情况下,json 这种文本序列化性能不如二进制序列化。
- java 序列化:主要是采用 JDK 自带的 java 序列化实现,性能很不理想。
- Kryo 和 FST:Kryo 和 FST 的性能依然普遍优于 hessian 和 dubbo 序列化。
Hessian 序列化与 Java 默认的序列化区别?
Hessian 是一个轻量级的 remoting on http 工具,采用的是 Binary RPC 协议,所以它很适合于发送二进制数据,同时又具有防火墙穿透能力。
- Hessian 支持跨语言串行
- 比 java 序列化具有更好的性能和易用性
- 支持的语言比较多
Protoco Buffer 是什么?
Protocol Buffer 是 Google 出品的一种轻量 & 高效的结构化数据存储格式,性能比 Json、XML 真的强!太!多!
Protocol Buffer 的序列化 & 反序列化简单 & 速度快的原因是:
- 编码 / 解码 方式简单(只需要简单的数学运算 = 位移等等)
- 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成
Protocol Buffer 的数据压缩效果好(即序列化后的数据量体积小)的原因是:
- 采用了独特的编码方式,如 Varint、Zigzag 编码方式等等
- 采用 T - L - V 的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑
注册中心挂了可以继续通信吗?
可以。Dubbo 消费者在应用启动时会从注册中心拉取已注册的生产者的地址接口,并缓存在本地。每次调用时,按照本地存储的地址进行调用。
ZooKeeper 原理是什么?ZooKeeper 有什么用?
ZooKeeper 是一个分布式应用协调系统,已经用到了许多分布式项目中,用来完成统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等工作。

- 每个 Server 在内存中存储了一份数据;
- Zookeeper 启动时,将从实例中选举一个 leader(Paxos 协议);
- Leader 负责处理数据更新等操作(Zab 协议);
- 一个更新操作成功,当且仅当大多数 Server 在内存中成功修改数据。
Netty 有什么用?NIO/BIO/AIO 有什么用?有什么区别?
Netty 是一个“网络通讯框架”。
Netty 进行事件处理的流程。Channel是连接的通道,是 ChannelEvent 的产生者,而ChannelPipeline可以理解为 ChannelHandler 的集合。
IO 的方式通常分为几种:
- 同步阻塞的 BIO
- 同步非阻塞的 NIO
- 异步非阻塞的 AIO
在使用同步 I/O 的网络应用中,如果要同时处理多个客户端请求,或是在客户端要同时和多个服务器进行通讯,就必须使用多线程来处理。
NIO 基于 Reactor,当 socket 有流可读或可写入 socket 时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。
与 NIO 不同,当进行读写操作时,只须直接调用 API 的 read 或 write 方法即可。这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入 read 方法的缓冲区,并通知应用程序;对于写操作而言,当操作系统将 write 方法传递的流写入完毕时,操作系统主动通知应用程序。 即可以理解为,read/write 方法都是异步的,完成后会主动调用回调函数。
为什么要进行系统拆分?拆分不用 Dubbo 可以吗?
系统拆分从资源角度分为:应用拆分和数据库拆分。
从采用的先后顺序可分为:水平扩展、垂直拆分、业务拆分、水平拆分。

当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键。
Dubbo 和 Thrift 有什么区别?
- Thrift 是跨语言的 RPC 框架。
- Dubbo 支持服务治理,而 Thrift 不支持。
分布式锁基本原理
分布式锁有几种实现方式?实现的要点是什么?
分布式锁各方案有什么利弊?如何选择方案?为什么?
Redis 分布式锁如何保证可重入性?
详细内容请参考:分布式锁
【答题思路】
实现方式一般有:
- 基于数据库实现:
- 建一张表(t_dlock),关键字段有:
id、method_name、time。 - 向表中插入记录成功,即为获取锁成功。需要注意的是,获取锁一般是通过自旋方式,并设置尝试次数,超过最大尝试次数,才判定获取锁失败。
- 删除记录,即为释放锁。
- 因为数据库没有淘汰机制,为了避免获取锁永不释放,应用需要自身实现定期检查,删除过期记录(根据 time 判断)。
- 建一张表(t_dlock),关键字段有:
- 基于 Redis 实现
- 生成一个分布式 ID 作为 key,通过
setnx写入 - 写入成功,即为获取锁成功。需要注意的是,获取锁一般是通过自旋方式,并设置尝试次数,超过最大尝试次数,才判定获取锁失败。
- 删除 key,即为获取锁失败。
- Redis 自身有内存淘汰策略,所以只要设置 expire,就可以让 key 自动过期。
- 生成一个分布式 ID 作为 key,通过
- 基于 ZooKeeper 实现
- 创建一个节点,所有节点都 Watch 此节点。
- 任意节点的任意线程只要向这个节点创建临时子节点成功,即为获取锁成功。
- 由于创建临时子节点是原子性的,不存在竞态,不需要自旋尝试,性能很好。
- 因为 ZooKeeper 只要和节点断开会话,就会自动删除临时节点。即为删除锁。所以无需过期机制。
从实现方式可以看出,三种方案的对比:
- Mysql 方案性能最差,并且影响 Mysql 吞吐量。而且还要程序保证容错处理。不建议采用这种方案。
- Redis 方案需要不断自旋尝试获取锁,应用会消耗一些性能开销。而且为了保证分布式锁的可重入性,需要设置对于所有节点、所有线程都唯一的分布式 ID,生成 ID 也需要一定的 CPU 开销。
- ZooKeeper 方案实现最简单,最稳定。是推荐的方案。但是它也有一个问题:ZooKeeper 的主从架构,所有写都由 Master 节点负责,所以 ZooKeeper 自身有一定的性能瓶颈。