Kafka 简介
【简单】Kafka 是什么?⭐
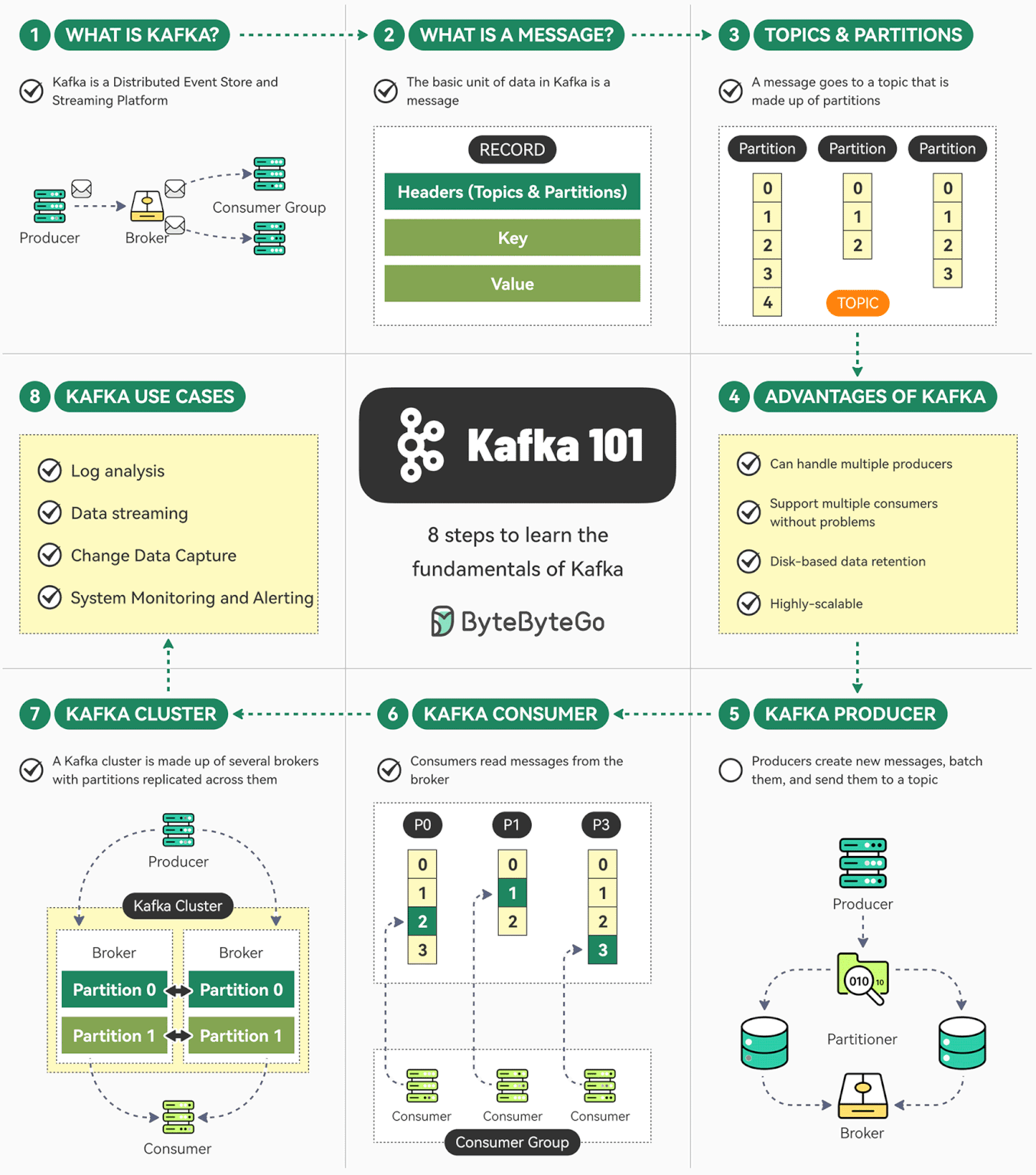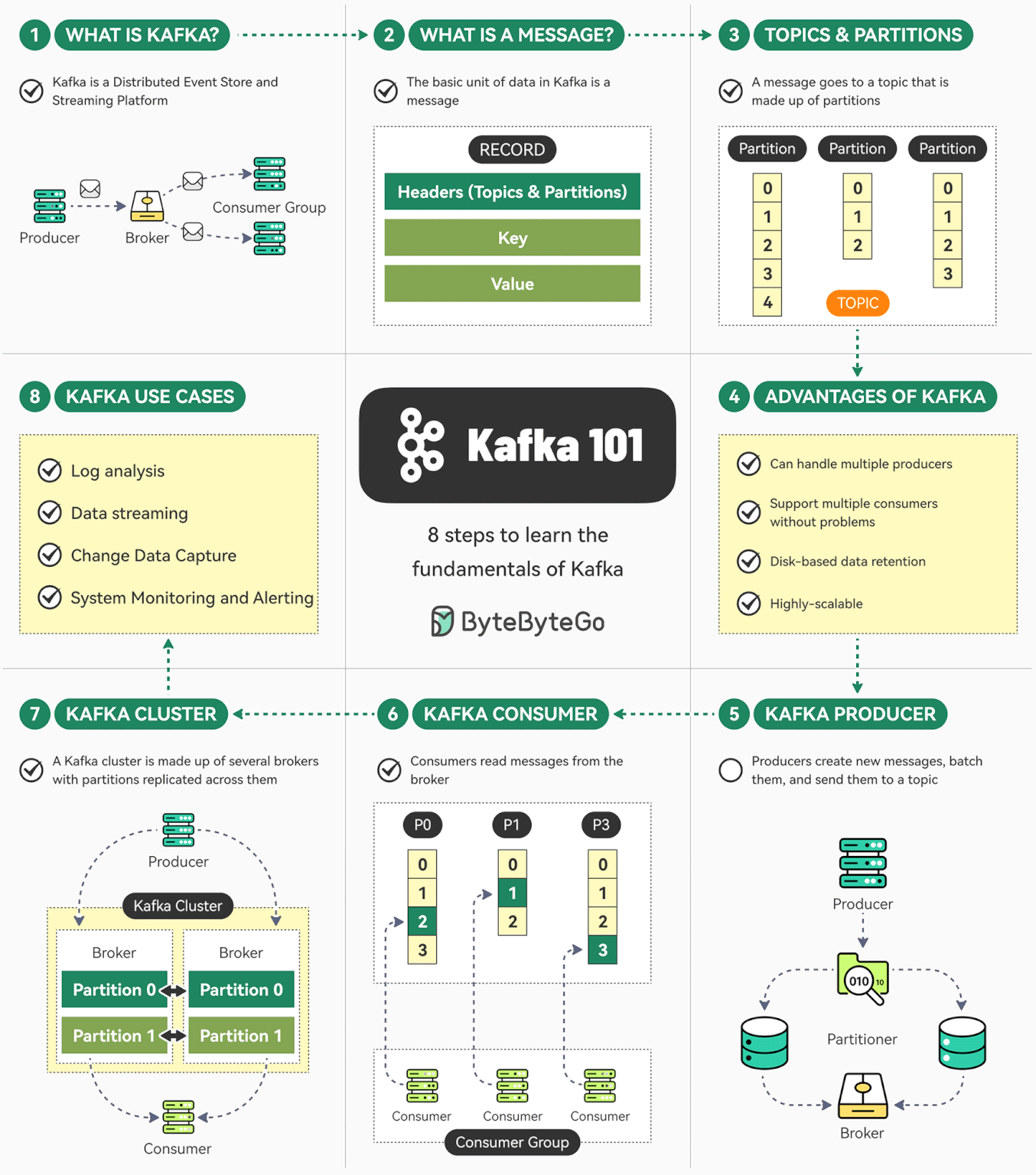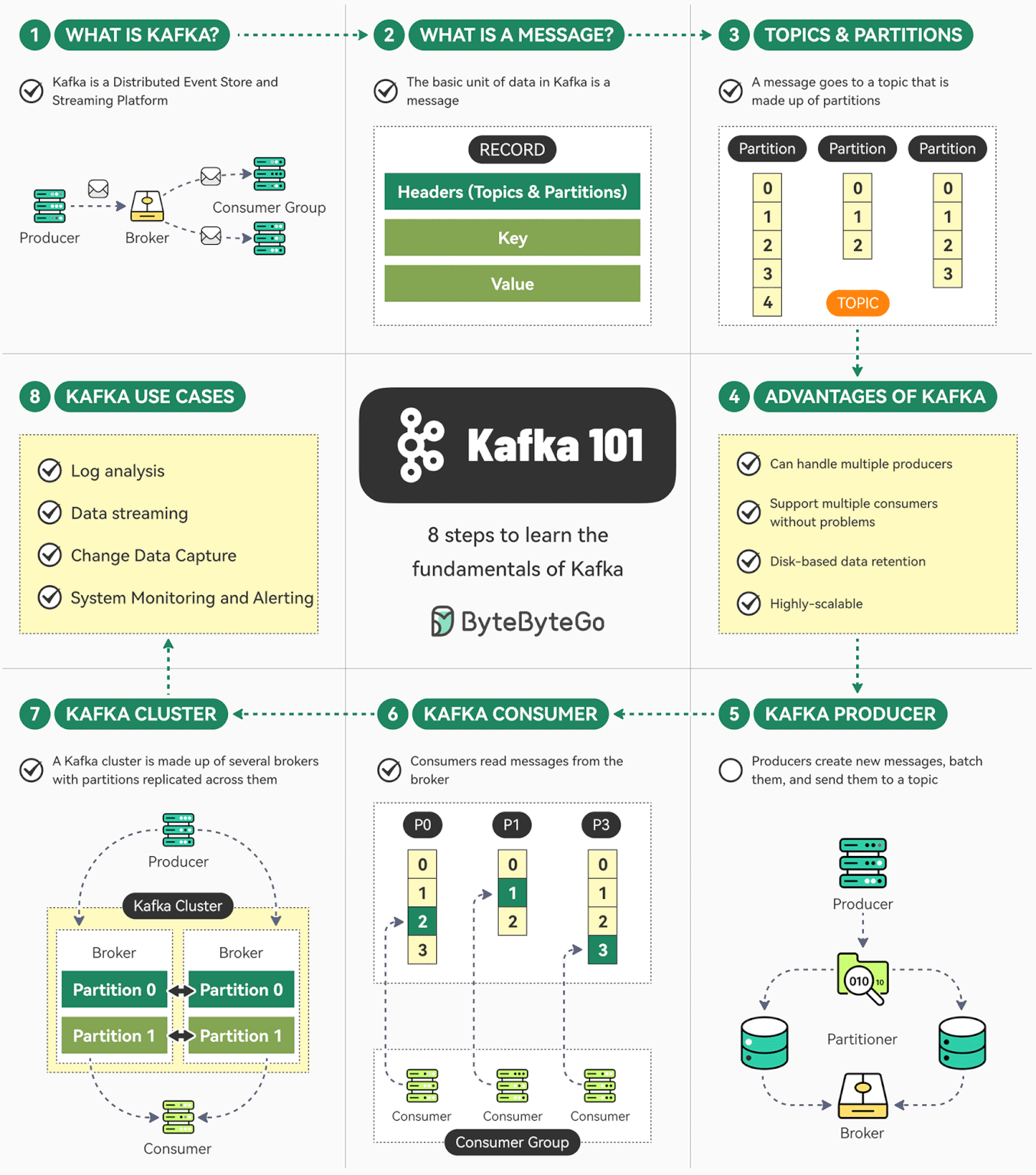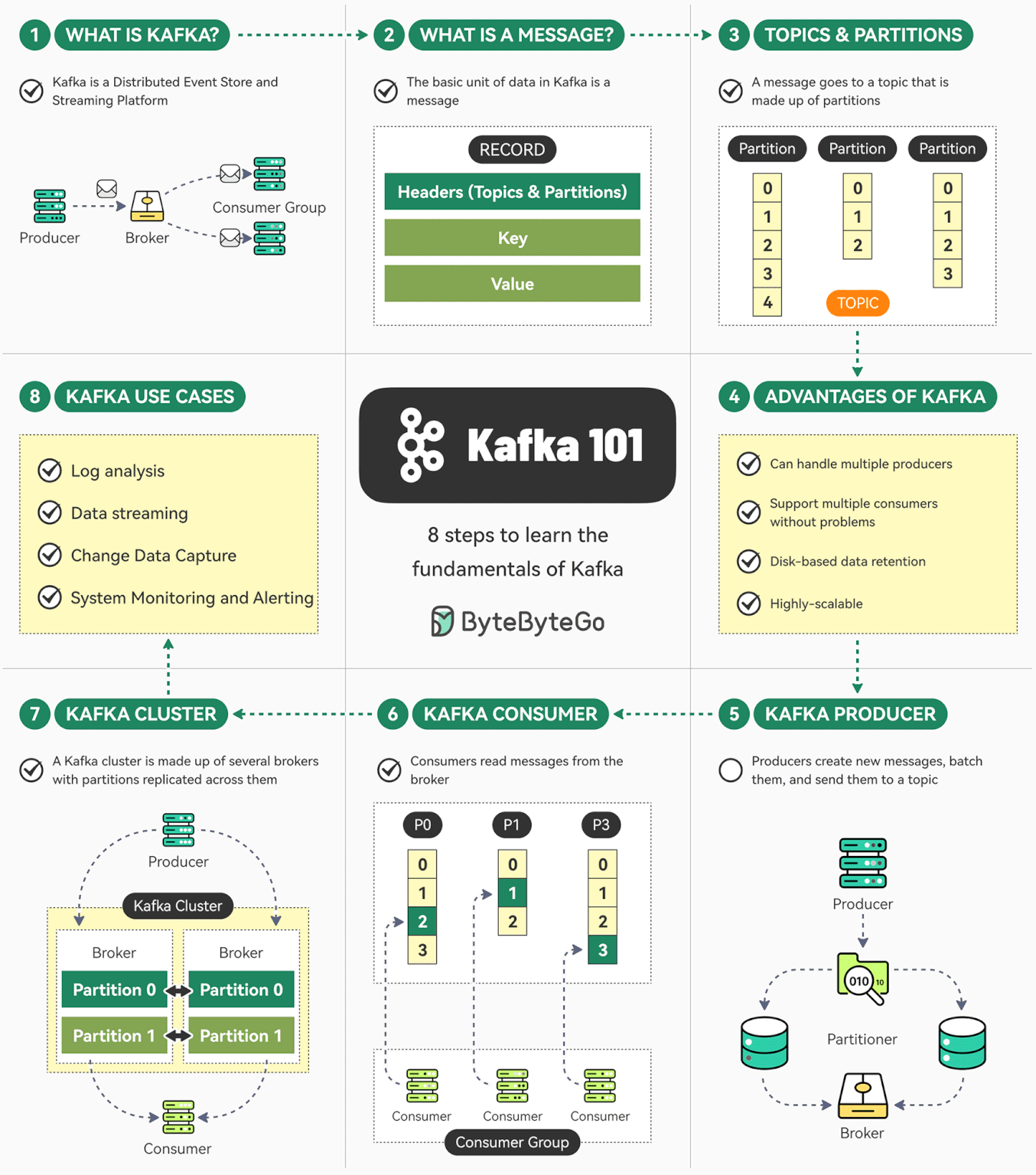
Kafka 是一个开源分布式事件流平台。最初由 LinkedIn 开发,现在是 Apache 顶级项目。
2025/2/3大约 67 分钟
Kafka 是一个开源分布式事件流平台。最初由 LinkedIn 开发,现在是 Apache 顶级项目。
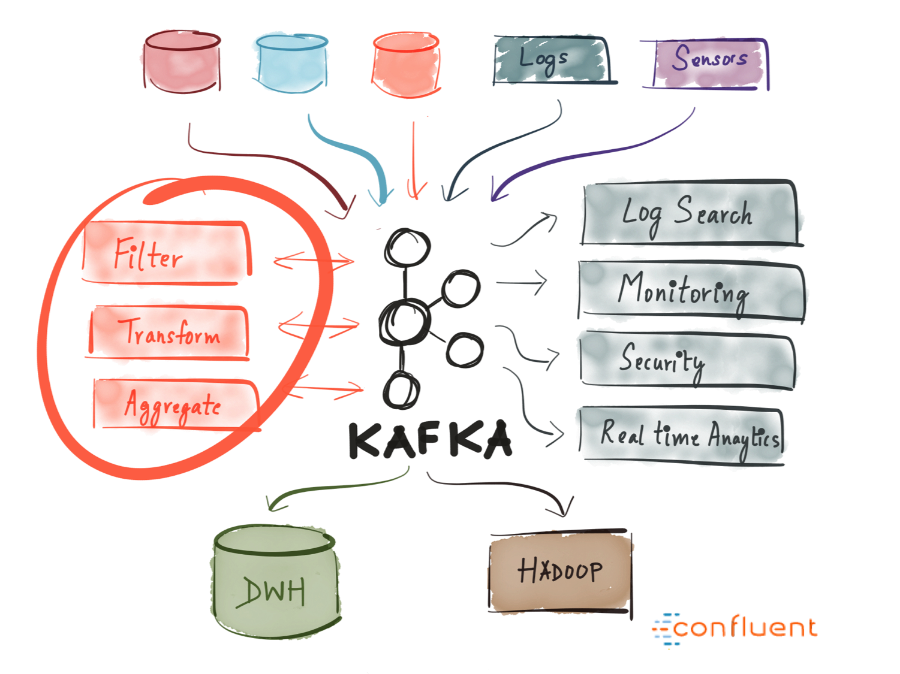
Kafka 是 Apache 的开源项目。Kafka 既可以作为一个消息队列中间件,也可以作为一个分布式流处理平台。
Kafka 用于构建实时数据管道和流应用。它具有水平可伸缩性,容错性,快速快速性。
Kafka 是一个分布式的、可水平扩展的、基于发布/订阅模式的、支持容错的消息系统。
Kafka 使用 Zookeeper 来维护集群成员的信息。每个 Broker 都有一个唯一标识符,这个标识符可以在配置文件里指定,也可以自动生成。在 Broker 启动的时候,它通过创建临时节点把自己的 ID 注册到 Zookeeper。Kafka 组件订阅 Zookeeper 的 /broker/ids 路径,当有 Broker 加入集群或退出集群时,这些组件就可以获得通知。
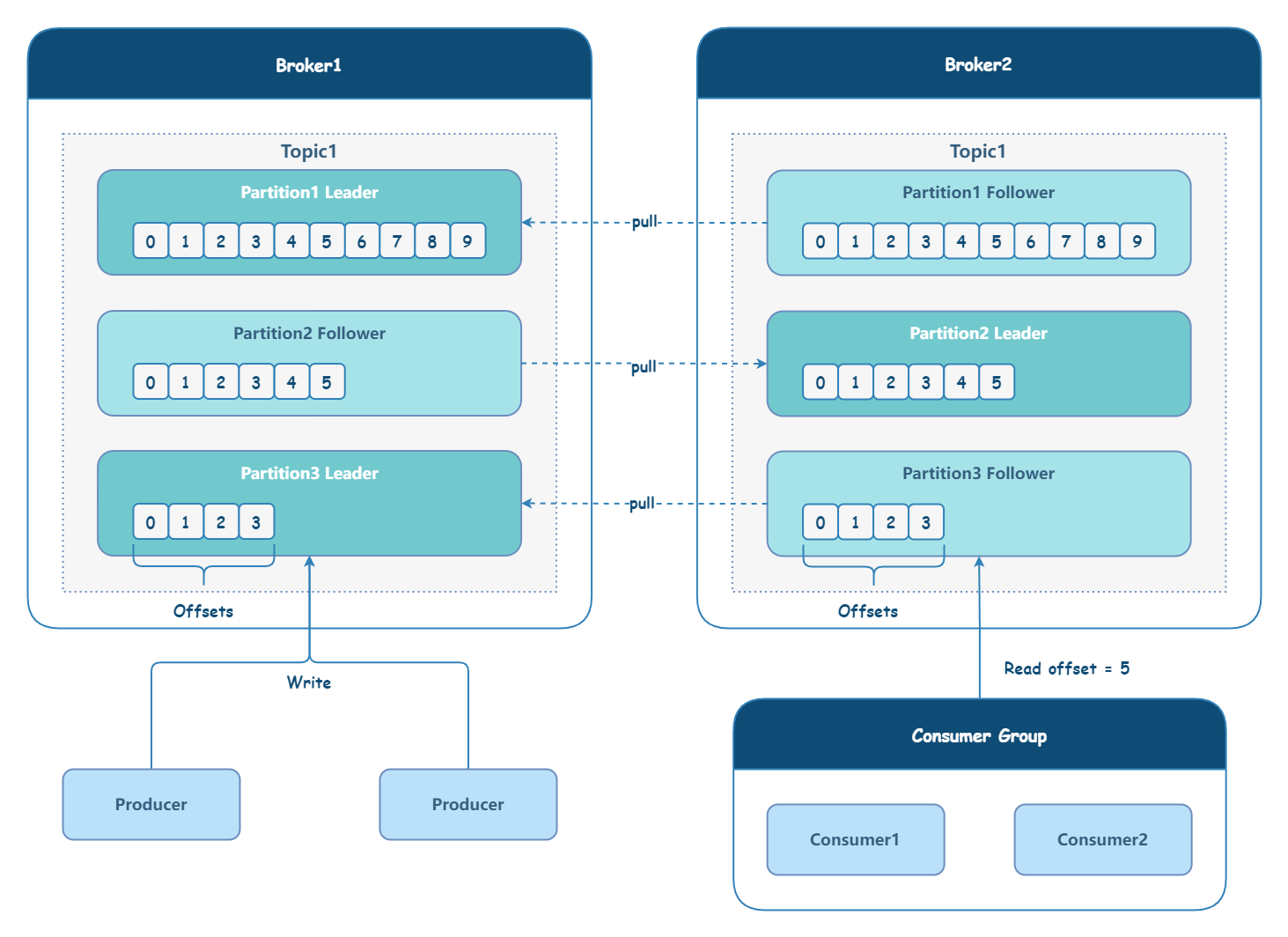
如何保证消息的可靠性传输,或者说,如何保证消息不丢失?这对于任何 MQ 都是核心问题。
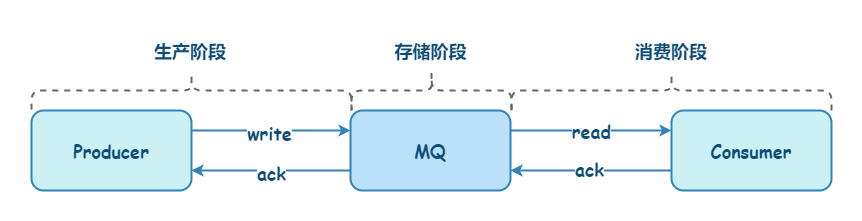
一条消息从生产到消费,可以划分三个阶段:
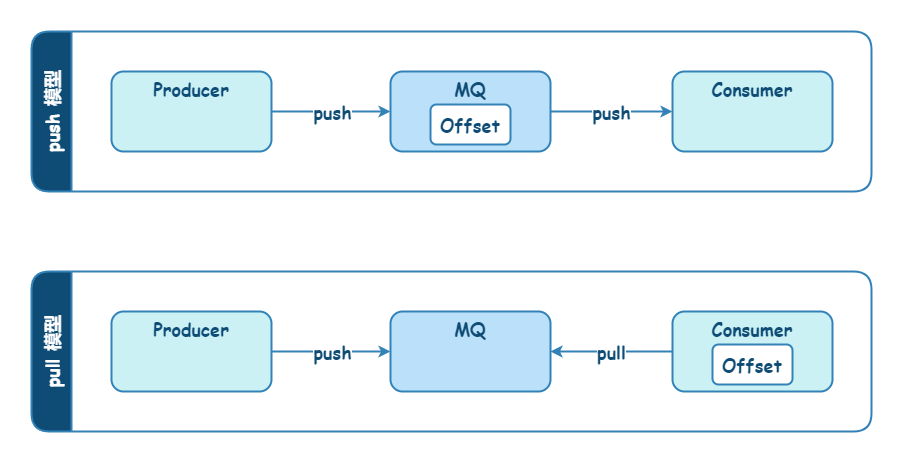
消息引擎获取消息有两种模式:
不管是把 Kafka 作为消息队列系统、还是数据存储平台,总是需要一个可以向 Kafka 写入数据的生产者和一个可以从 Kafka 读取数据的消费者,或者是一个兼具两种角色的应用程序。
使用 Kafka 的场景很多,诉求也各有不同,主要有:是否允许丢失消息?是否接受重复消息?是否有严格的延迟和吞吐量要求?
不同的场景对于 Kafka 生产者 API 的使用和配置会有直接的影响。
Kafka Producer 发送的数据对象叫做 ProducerRecord ,它有 4 个关键参数:
Kafka 是 Apache 的开源项目。Kafka 既可以作为一个消息队列中间件,也可以作为一个分布式流处理平台。
Kafka 用于构建实时数据管道和流应用。它具有水平可伸缩性,容错性,快速快速性。
数据流是无边界数据集的抽象表示。无边界意味着无限和持续增长。无边界数据集之所以是无限的,是因为随着时间的推移,新的记录会不断加入进来。
Apache Kafka 是一款开源的消息引擎系统,也是一个分布式流计算平台,此外,还可以作为数据存储。