RabbitMQ 面试
RabbitMQ 简介
【简单】RabbitMQ 是什么?⭐
RabbitMQ 是一个开源的消息队列中间件,基于 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)标准实现。
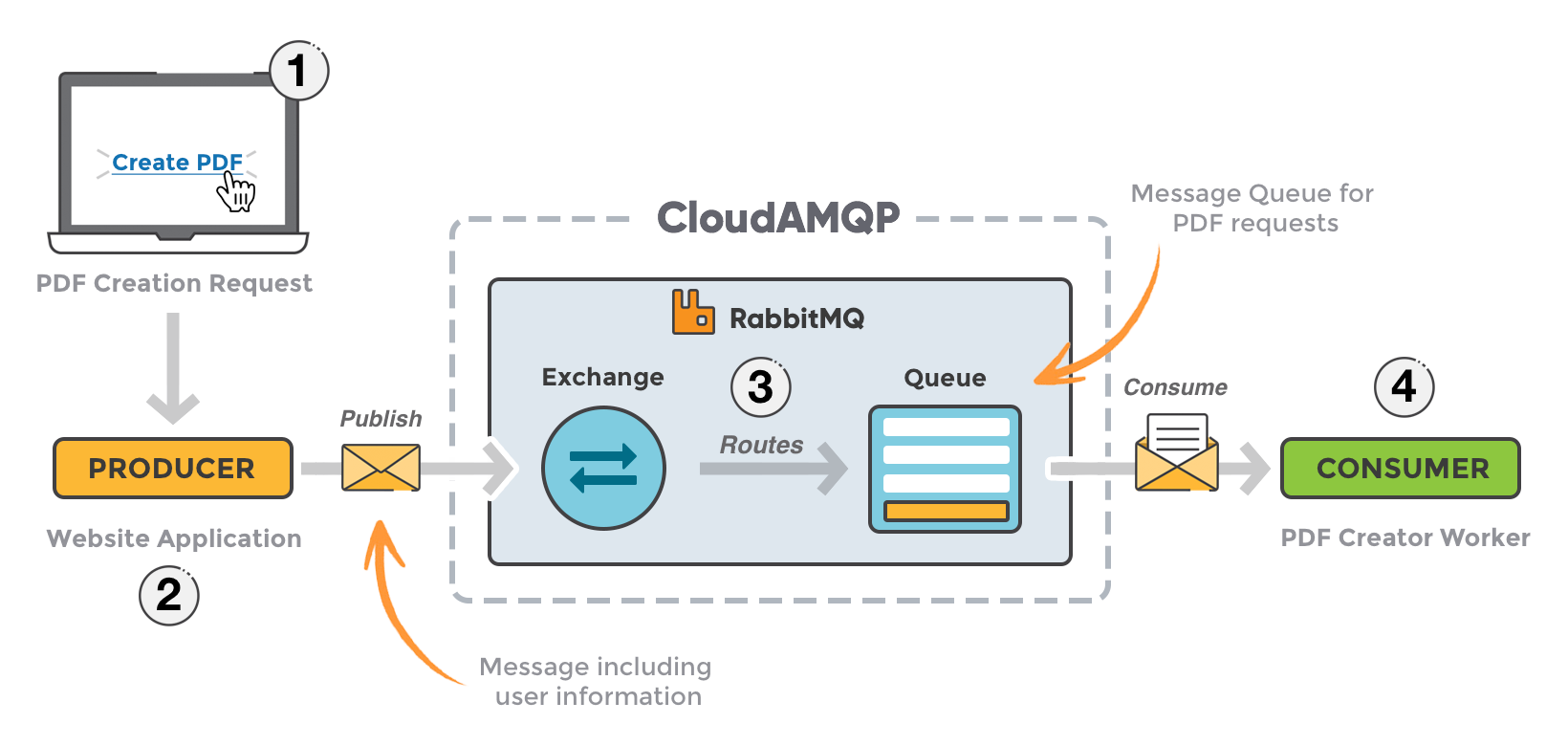
RabbitMQ 的核心概念
- 生产者(Producer):发送消息的应用。
- 消费者(Consumer):接收和处理消息的应用。
- 消息代理(Broker):负责接收、路由和存储消息。
- 交换机(Exchange):消息路由中心,根据规则将消息发到不同队列。
- 队列(Queue):存储消息的缓冲区。
- 绑定(Binding):定义交换机与队列的映射关系(含路由键规则)。
- 路由键(Routing Key):生产者发送时指定的关键字,用于交换机匹配队列。
- 虚拟主机(VHost):逻辑隔离单元(类似命名空间),不同 VHost 的队列/交换机互不可见。
- 死信队列(DLX):用于存放处理失败或过期消息的“垃圾回收站”或“隔离分析区”。
- AMQP:RabbitMQ 的核心通信协议,定义消息格式与交互规则。
【简单】RabbitMQ 有哪些核心组件?⭐
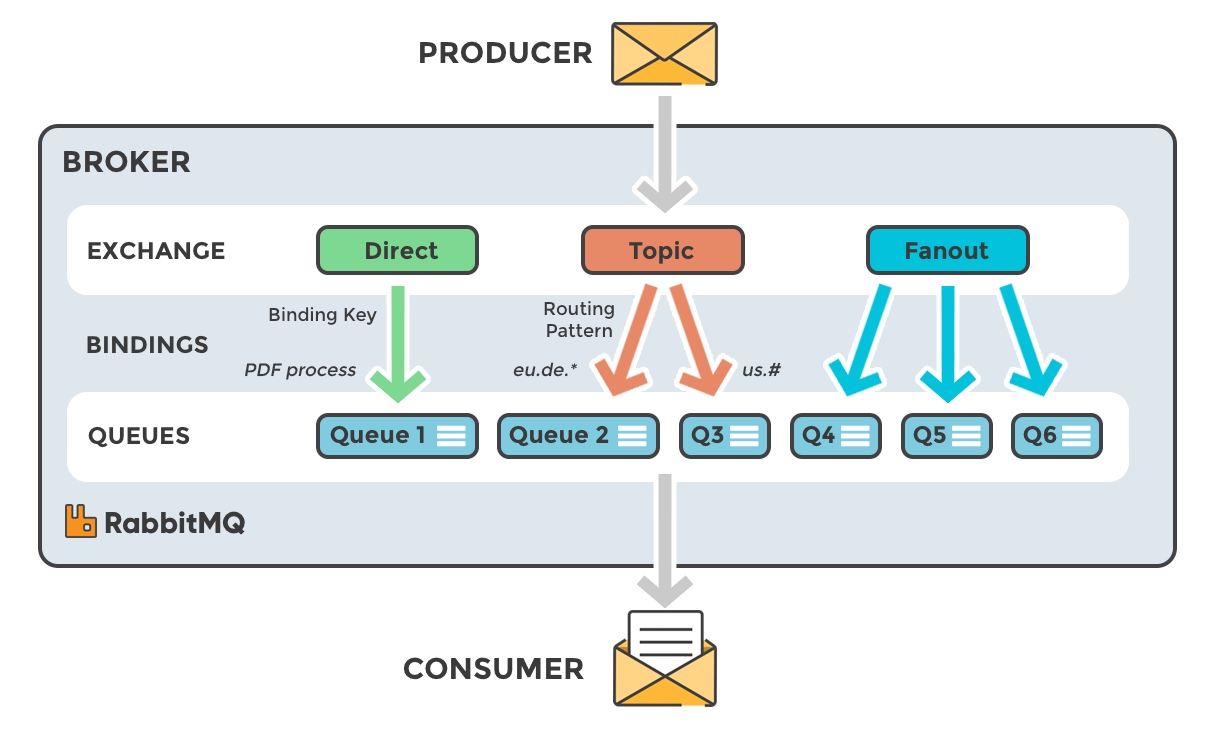
RabbitMQ 的基本架构主要由以下核心组件组成:
- Producer(生产者):负责发送消息到交换机。
- Consumer(消费者):接收并处理队列中的消息。
- Exchange(交换机):接受并路由消息到队列,根据绑定键将消息分配到一个或多个队列。
- Queue(队列):消息的存储地点,消费者从队列中读取消息。
- Binding(绑定):定义交换机和队列之间的路由规则。
- Routing Key(路由键):用于交换机到队列的路由规则。
- Virtual Host(虚拟主机):逻辑分组,用于隔离不同应用的资源。
- Connection(连接):RabbitMQ 的客户端与服务器之间的网络连接。
- Channel(信道):在连接中的虚拟连接,进行消息的读写操作。
【简单】RabbitMQ 的 routing key 和 binding key 的最大长度是多少字节?
长度限制
- 最大 255 字节(超限会抛出异常)。
- 适用于 Routing Key(生产者指定)和 Binding Key(队列绑定交换机时指定)。
匹配规则(不同交换机类型)
| 交换机类型 | 匹配方式 | 示例 |
|---|---|---|
| Direct | 完全匹配 | routing_key == binding_key |
| Topic | 通配符匹配(* 匹配一个词,# 匹配多个词) | *.order.# 匹配 user.order.create |
| Headers | 不依赖 Routing Key,基于消息头键值对匹配 | x-match: all/any |
最佳实践
- 保持简短:避免接近 255 字节,提升性能。
- 命名规范:如
{服务}.{模块}.{事件}(例:user.order.paid)。 - Topic 通配符:合理使用
*和#,避免过度复杂。
⚠️ 注意:Headers 交换机忽略 Routing Key,仅依赖消息头(Headers)匹配。
RabbitMQ 存储
【中等】RabbitMQ 中的持久化队列与非持久化队列有什么区别?
RabbitMQ 提供持久化队列和非持久化队列两种队列类型,主要区别在于消息存储方式及服务器重启或崩溃时的行为
| 特性 | 持久化队列 | 非持久化队列 |
|---|---|---|
| 存储位置 | 磁盘 | 内存 |
| 服务器重启/崩溃 | 消息保留,确保不丢失 | 消息全部丢失 |
| 性能 | 较低(因需写磁盘) | 极高(内存操作) |
| 适用场景 | 要求消息可靠性的场景 | 允许消息丢失,追求高性能的场景 |
核心权衡:在消息的“可靠性”与“性能”之间做选择。
【中等】RabbitMQ 如何持久化?⭐⭐
RabbitMQ 持久化是将消息和队列元数据保存到磁盘,确保服务重启后数据不丢失。
RabbitMQ 实现持久化的方法:
| 要素 | 目的 | 实现方式 |
|---|---|---|
| 队列持久化 | 保证队列元数据不丢失 | 声明队列时 durable=true |
| 消息持久化 | 保证消息内容不丢失 | 发送消息时 delivery_mode=2 |
| 交换机持久化 | 保证交换机元数据不丢失 | 声明交换机时 durable=true |
- 生效前提:必须将持久化消息发送到持久化队列才能生效。仅消息持久化而队列非持久化,重启后消息依然会丢失。
- 性能代价:持久化需要写磁盘,会显著降低吞吐量,是可靠性与性能之间的权衡。
【中等】什么是 RabbitMQ 中的虚拟主机(vhost)?有什么作用?
RabbitMQ 中的虚拟主机(vhost)是逻辑上的隔离概念,用于隔离不同应用或租户。每个虚拟主机可拥有独立的队列、交换器、绑定、权限等资源,多个独立应用可共存于一台 RabbitMQ 服务器且互不影响,可看作 RabbitMQ 内部的 “命名空间”。
- 资源隔离:不同 vhost 有自己的交换器(exchange)、队列(queue)和绑定(binding),资源在不同 vhost 中互不干扰。
- 安全控制:通过对 vhost 的不同用户角色进行权限管理,细化资源访问控制。
- 管理便捷:使多租户应用管理更便捷,可在同一个 RabbitMQ 实例上运行多个独立应用。
RabbitMQ 生产消费
【中等】如何在 RabbitMQ 中声明一个队列?有哪些必要参数?
- 声明方式:通过客户端库的
queueDeclare方法实现,队列不存在则创建,存在则验证参数匹配性 - 核心参数:
- 队列名称:唯一标识,空字符串会生成随机名称
- 持久化(durable):
true表示队列元数据持久化,重启不丢失 - 排他性(exclusive):
true表示仅当前连接可见,连接关闭后自动删除 - 自动删除(autoDelete):
true表示最后一个消费者断开后自动删除 - 其他参数(arguments):可选,用于配置消息过期时间、死信交换机等
- 特性:根据业务需求(可靠性、生命周期等)配置参数,确保队列行为符合预期
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
public class DeclareQueueExample {
public static void main(String[] args) throws Exception {
// 创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 建立连接和信道
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
// 声明队列
String queueName = "order_queue";
boolean durable = true; // 持久化
boolean exclusive = false; // 非排他
boolean autoDelete = false; // 不自动删除
Map<String, Object> arguments = null; // 无额外参数
channel.queueDeclare(queueName, durable, exclusive, autoDelete, arguments);
System.out.println("队列 " + queueName + " 声明成功");
}
}
}【中等】RabbitMQ 如何实现消息路由?⭐⭐
RabbitMQ 通过交换机(Exchange)实现消息路由,而非直接发送到队列。交换机接收生产者消息,依据特定策略(路由键)将消息路由到一个或多个队列,其类型和绑定(Binding)规则决定消息流向。RabbitMQ 常见路由策略包括:
- Direct 交换机:消息通过完全匹配路由键进行路由。
- Fanout 交换机:广播消息到所有绑定的队列,不需要路由键。
- Topic 交换机:根据路由键模式匹配进行路由。
- Headers 交换机:根据消息头属性进行路由。
【中等】RabbitMQ 中无法路由的消息会去到哪里?
在 RabbitMQ 中,无法路由的消息(即无法被投递到任何队列的消息)的处理方式取决于消息的 mandatory 和 immediate 属性(RabbitMQ 3.0+ 已弃用 immediate),具体规则如下:
默认情况(未设置 mandatory)
- 消息被直接丢弃(即 "静默丢失")。
- 生产者无感知:Broker 不会返回任何通知。
设置了 mandatory=true
若消息无法路由到任何队列,Broker 会通过
basic.return方法将消息返回给生产者。生产者需监听返回消息:
channel.basicPublish("exchange", "routingKey", new AMQP.BasicProperties.Builder().mandatory(true).build(), message.getBytes()); // 添加 ReturnListener 监听返回消息 channel.addReturnListener((replyCode, replyText, exchange, routingKey, properties, body) -> { System.out.println("消息未被路由:" + new String(body)); });适用场景:需严格确保消息路由成功的业务(如关键订单通知)。
备用交换机(Alternate Exchange)
预先声明一个备用交换机,绑定一个队列(如
unrouted_queue)接收无法路由的消息。配置方式:
Map<String, Object> args = new HashMap<>(); args.put("alternate-exchange", "my_ae"); // 指定备用交换机 channel.exchangeDeclare("main_exchange", "direct", false, false, args); // 声明备用交换机和队列 channel.exchangeDeclare("my_ae", "fanout"); channel.queueDeclare("unrouted_queue", false, false, false, null); channel.queueBind("unrouted_queue", "my_ae", "");逻辑:若消息无法通过
main_exchange路由,则自动转发到my_ae,最终进入unrouted_queue。
关键区别
| 处理方式 | 条件 | 结果 | 适用场景 |
|---|---|---|---|
| 直接丢弃 | 默认情况 | 消息丢失,无通知 | 允许消息丢失的非关键业务 |
| 返回生产者 | mandatory=true | 通过 basic.return 回退消息 | 需严格监控路由失败的场景 |
| 转发到备用交换机 | 配置了 Alternate Exchange | 消息存入备用队列 | 需审计或补偿无法路由的消息 |
最佳实践
- 关键消息:始终设置
mandatory=true并监听basic.return。 - 日志与监控:使用备用交换机收集无法路由的消息,便于排查问题。
- 避免消息丢失:确保交换机和队列的绑定关系正确,或使用 死信队列(DLX) 处理异常消息。
📌 注意:RabbitMQ 3.0+ 已移除
immediate参数,旧版本中设置immediate=true会导致无法路由的消息被丢弃(除非同时设置mandatory)。
【中等】RabbitMQ 中消息什么时候会进入死信交换机?
通过合理配置 DLX,可以实现消息的优雅降级和故障隔离。
RabbitMQ 中消息进入死信交换机的触发情况
在 RabbitMQ 中,消息进入 死信交换机(Dead Letter Exchange, DLX) 通常由以下 5 种情况触发:
(1)消息被消费者拒绝:消费者显式拒绝消息且不重新入队。
channel.basicReject(deliveryTag, false); // 或 basicNack 且 requeue=false- 典型场景:消息处理失败且无需重试(如业务校验不通过)。
(2)消息过期(TTL 超时):
- 消息设置了 TTL(Time-To-Live),且未在过期前被消费。
- 队列设置了
x-message-ttl,消息在队列中停留超时。
// 设置消息 TTL
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.expiration("60000") // 60 秒过期
.build();
channel.basicPublish("", "normal_queue", props, message.getBytes());(3)队列达到最大长度:队列设置了 x-max-length 或 x-max-length-bytes,且新消息到达时队列已满。
// 声明队列时设置最大长度
Map<String, Object> args = new HashMap<>();
args.put("x-max-length", 1000); // 最多 1000 条消息
channel.queueDeclare("normal_queue", false, false, false, args);(4)队列被删除:消息所在的队列被删除(queueDelete),且消息未被消费。
(5)主节点崩溃:镜像队列(Mirrored Queue) 中主节点崩溃,且消息未同步到从节点。
关键配置步骤
声明死信交换机(DLX)和死信队列:
// 声明死信交换机(类型通常为 direct/fanout) channel.exchangeDeclare("dlx_exchange", "direct"); // 声明死信队列 channel.queueDeclare("dlx_queue", false, false, false, null); channel.queueBind("dlx_queue", "dlx_exchange", "dlx_routing_key");
2. **为普通队列绑定死信交换机**:
```java
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "dlx_exchange"); // 指定 DLX
args.put("x-dead-letter-routing-key", "dlx_routing_key"); // 可选
channel.queueDeclare("normal_queue", false, false, false, args);注意事项
- 死信消息的 原始属性(如 headers)会被保留,但
exchange和routingKey会被替换为 DLX 的配置。 - 若未指定
x-dead-letter-routing-key,则使用消息原来的 routing key。
典型应用场景
- 延迟队列:通过 TTL+DLX 实现消息延迟投递。
- 失败处理:将处理失败的消息自动路由到死信队列,供人工或异步处理。
- 流量控制:队列满时转移旧消息,避免阻塞新消息。
【中等】RabbitMQ 如何实现消息确认机制?
RabbitMQ 的消息确认机制主要用于确保可靠的消息传输。
生产者确认机制:生产者开启发布确认模式 (Publisher Confirms) 后,Broker 会返回一个确认信号(使用 异步回调 (correlated) 是性能最佳实践)。
Basic.Ack:消息成功被 Broker 接收(并可能已持久化)。收到Ack才认为发送成功,否则需重发。Basic.Nack:消息接收失败(罕见,如 Broker 内部错误)
消费者确认机制
自动确认 (
autoAck=true):消息一发出就被 Broker 删除。- 风险:消费者处理失败会导致消息永久丢失。
手动确认 (
autoAck=false) 【推荐】:消费者必须显式发送确认命令(调用channel.basicAck()),Broker 才会删除消息。basicAck:处理成功,确认删除。basicNack/basicReject:处理失败。可选择是否将消息重新放回队列 (requeue=true) 或丢弃/转入死信队列 (requeue=false)。
【中等】如何在 RabbitMQ 中实现消息的批量消费?
RabbitMQ 协议本身不支持服务端批量推送,但可通过客户端机制模拟批量消费。核心是:开启手动确认,积攒消息,统一处理后再确认。
首选方法:Prefetch(预取) + 手动确认
- 设置预取数量:使用
channel.basicQos(prefetchCount),限制信道上次可持有的最大未确认消息数。 - 开启手动确认:消费消息时,不自动确认,由业务逻辑控制。
- 缓存与批量处理:
- 将收到的消息暂存到内存(如列表)。
- 当积攒数量达到
prefetchCount或等待超时时,执行批量业务逻辑(如批量入库)。
- 统一确认:批量处理成功后,对该批所有消息进行手动确认。
优点:实现简单、能进行流量控制、显著提高吞吐量。
关键:业务逻辑必须支持幂等性,以防重复消费。
备选方法:主动拉取
使用 channel.basicGet() 在循环中主动从队列拉取消息,凑够一批后处理和确认。
优点:控制更精确。
缺点:实现复杂,空队列时效率低。不推荐为首选。
总结建议
- 绝大多数场景下,应使用 Prefetch + 手动确认的方案。
- 牢记幂等性是保证数据准确性的前提。
- 根据业务处理能力和内存情况,合理设置
prefetchCount大小。
【中等】RabbitMQ 中如何处理未被消费者确认的消息?
在 RabbitMQ 中,当消费者接收到一条消息后,若因某种原因未确认(ACK)该消息,这条消息会被重新入队并传递给其他消费者(或相同消费者再次接收)。详细实现方式如下:
- 在消费者代码中需启用消息确认机制(manual acknowledgment),即通过
channel.basic_ack手动确认消息处理完成。 - 若消费者未发送
basic_ack(比如消费者宕机或消息处理异常),消息会被再次发送给下一个可用的消费者。此时 RabbitMQ 会把消息的delivery tag返还给 queue,以保证消息被再次处理。
【简单】如何在 RabbitMQ 中设置队列的最大长度?
在 RabbitMQ 中,可通过 x-max-length 参数设置队列最大长度,该参数能在声明队列时指定队列允许的最大消息数,超出数量的消息会被自动删除(默认按先进先出原则删老消息)。
具体实现步骤:
- 使用 RabbitMQ 管理工具(如
rabbitmqctl或 RabbitMQ 管理控制台)。 - 通过代码创建队列时,设置队列属性。
以 Python 的 Pika 库声明队列为例,代码如下:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 设置队列的最大长度 x-max-length
channel.queue_declare(queue='my_queue', arguments={'x-max-length': 10})
connection.close()在这段代码里,queue_declare 方法的 arguments 参数指定了 x-max-length,并将其值设为 10。
【简单】如何在 RabbitMQ 中配置消息的 TTL(过期时间)?
要在 RabbitMQ 中配置消息的 TTL(过期时间),需通过设置队列或消息的 TTL(Time To Live,消息在队列中存活的时间),有两种方式:
队列级别的 TTL:在声明队列时通过设置 x-message-ttl 参数指定队列中所有消息的 TTL。
// Java 示例(使用 RabbitMQ 的官方客户端)
Map<String, Object> args = new HashMap<>();
args.put("x-message-ttl", 60000); // 设置队列的 TTL 为 60,000 毫秒(60 秒)
channel.queueDeclare("myQueue", false, false, false, args);消息级别的 TTL:在发送消息时通过 AMQP.BasicProperties 属性指定单个消息的 TTL。
// Java 示例(使用 RabbitMQ 的官方客户端)
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder()
.expiration("60000") // 设置消息的 TTL 为 60,000 毫秒(60 秒)
.build();
channel.basicPublish("", "myQueue", props, "Hello, World!".getBytes());【中等】RabbitMQ 有哪些工作模式?
RabbitMQ 有以下几种主要的工作模式:
- 简单模式(Simple)
- 工作队列模式(Work Queue)
- 发布/订阅模式(Publish/Subscribe)
- 路由模式(Routing)
- 主题模式(Topic)
- RPC 模式(远程调用)
以下,对几种工作模式逐一进行说明:
简单模式(Simple)
- 角色:1 生产者 → 1 队列 → 1 消费者
- 特点:单向通信,无路由逻辑,即点对点模式
- 场景:单任务处理(如日志记录)
工作队列模式(Work Queue)
- 角色:1 生产者 → 1 队列 → 多个消费者竞争消费
- 特点:
- 消息轮询分发(默认)或公平分发(需设置
prefetch=1) - 消费者并行处理
- 消息轮询分发(默认)或公平分发(需设置
- 场景:任务分发(如订单处理)
发布/订阅模式(Publish/Subscribe)
- 角色:1 生产者 → Fanout 交换机 → 绑定多个队列 → 多个消费者
- 特点:
- 消息广播到所有队列
- 消费者各自独立接收全量消息
- 场景:事件通知(如系统公告)
路由模式(Routing)
- 角色:1 生产者 → Direct 交换机 → 根据
routing_key路由到特定队列 - 特点:
- 精确匹配路由键
- 支持多队列绑定相同路由键
- 场景:条件过滤(如错误日志分级处理)
主题模式(Topic)
- 角色:1 生产者 → Topic 交换机 → 基于通配符(
*/#)匹配路由键 - 特点:
- 模糊匹配(如
order.*匹配order.create) - 灵活性高
- 模糊匹配(如
- 场景:复杂路由(如多维度消息分类)
RPC 模式(远程调用)
- 角色:客户端 → 请求队列 → 服务端 → 响应队列 → 客户端
- 特点:
- 通过
reply_to和correlation_id关联请求/响应 - 同步阻塞式通信
- 通过
- 场景:服务间调用(需即时响应)
模式对比
| 模式 | 交换机类型 | 路由规则 | 典型应用 |
|---|---|---|---|
| 简单模式 | 无 | 无 | 单任务处理 |
| 工作队列 | 无 | 轮询/公平分发 | 并行任务 |
| 发布/订阅 | Fanout | 广播 | 多系统通知 |
| 路由模式 | Direct | 精确匹配routing_key | 条件过滤 |
| 主题模式 | Topic | 通配符匹配 | 复杂路由 |
| RPC 模式 | 无 | 请求-响应关联 | 同步服务调用 |
选择建议
- 广播需求 → Fanout
- 条件过滤 → Direct/Topic
- 任务并行 → Work Queue
- 服务调用 → RPC
RabbitMQ 集群
【中等】RabbitMQ 如何实现主从复制?
RabbitMQ 通过为队列配置镜像策略来实现主从复制和高可用,这是一种以队列为单位的复制机制。
核心命令(示例):
# 将匹配的所有队列镜像到集群中所有节点 rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all"}'关键参数:
ha-mode: 模式(all全部节点、exactly指定数量、nodes指定节点)。ha-sync-mode: 同步模式(automatic自动同步更安全)。
推荐方式: 使用管理控制台 或 命令行工具 设置策略,灵活且无需修改代码。
工作原理与故障转移
- 主从结构: 每个镜像队列有一个主队列(处理所有读写)和多个从队列(异步同步数据)。
- 客户端透明: 客户端始终与主队列交互,连接从节点时请求会被自动转发。
- 自动故障转移: 当主队列所在节点宕机,系统会自动从从队列中选举出一个新的主队列,实现高可用。
【困难】RabbitMQ 如何实现高可用?
高可用关键点
- 部署:至少** 3 个节点**(最好都是磁盘节点),分布在不同物理机。
- 接入层:使用负载均衡器为客户端提供统一入口,自动屏蔽故障节点。
- 故障转移:当主节点宕机,从节点会自动选举为新主,恢复服务。
两大实现机制
集群
- 作用:解决服务连续性。多个节点共享元数据(队列、交换机定义)。
- 关键:客户端可连接集群中任一存活节点进行所有操作。
- 节点类型:必须保证有磁盘节点在线(通常建议部署多个),以防元数据丢失。
队列复制
- 作用:解决数据不丢失。将队列内容(消息)复制到多个节点。
- 两种实现:
- 镜像队列:传统方案,主从异步复制。通过策略启用,如
rabbitmqctl set_policy ha-all "^ha\." '{"ha-mode":"all"}'。 - 仲裁队列:现代方案,基于 Raft 协议强一致复制。消息需多数节点确认,更安全,为 3.8+版本后的推荐选择。
- 镜像队列:传统方案,主从异步复制。通过策略启用,如
【简单】如何在 RabbitMQ 中创建一个镜像队列?
镜像队列是通过策略为普通队列开启主从复制,实现高可用。它基于 RabbitMQ 集群环境。
策略三要素:
- 名称:策略标识。
- 模式:匹配队列名的正则表达式(如
^important\.匹配重要队列)。 - 定义:核心设置
ha-mode。all:镜像到所有节点(开销大)。exactly:推荐。指定副本数(如2,即 1 主 1 从)。
配置方式:
- 管理界面:在
Admin->Policies中添加。 - 命令行:使用
rabbitmqctl set_policy命令。
示例(生产环境常用):
# 为重要队列创建 2 个副本
rabbitmqctl set_policy ha-important "^important\." '{"ha-mode":"exactly", "ha-params":2}'注意事项
- 集群是前提:单节点无效。
- 性能开销:同步复制有开销,只镜像关键队列。
- 队列命名:用前缀(如
critical.)区分重要队列,便于策略匹配。
一句话总结:通过创建策略,为匹配的队列自动开启主从复制,实现高可用。
【中等】RabbitMQ 有哪些集群模式?
RabbitMQ 有以下集群模式:
- 普通集群
- 镜像队列集群(高可用模式)
- 联邦集群
- 分片集群
所有集群模式均依赖 Erlang Cookie 实现节点间认证,需确保一致。
普通集群
- 核心特点
- 元数据(队列、交换机等)全节点同步
- 消息实体仅存于创建队列的节点(其他节点通过指针访问)
- 优点
- 节省存储(消息不冗余)
- 横向扩展方便
- 缺点
- 单点故障风险:若某节点宕机,其上的队列消息不可用
- 跨节点访问消息需网络传输
镜像队列集群(高可用模式)
- 核心特点
- 队列跨节点镜像复制(消息实体全节点冗余)
- 通过策略(Policy)定义镜像规则(如
ha-mode=all表示全节点复制)
- 优点
- 高可用:任一节点宕机,其他节点可继续服务
- 自动故障转移(消费者无感知)
- 缺点
- 存储开销大(消息全量复制)
- 写入性能略低(需同步所有副本)
联邦集群(Federation)
- 核心特点
- 跨机房/地域部署,消息按需异步转发
- 基于插件(
rabbitmq_federation)实现
- 适用场景
- 异地容灾
- 多区域消息同步
分片集群(Sharding)
- 核心特点
- 通过插件(
rabbitmq_sharding)将队列水平拆分到不同节点 - 生产者自动路由到对应分片
- 通过插件(
- 适用场景
- 超大规模队列(减轻单节点压力)
方案对比
| 模式 | 数据冗余 | 高可用 | 跨地域 | 适用场景 |
|---|---|---|---|---|
| 普通集群 | 无 | ❌ | ❌ | 开发测试、低重要性数据 |
| 镜像队列 | 全量复制 | ✔️ | ❌ | 生产环境(如订单、支付) |
| 联邦集群 | 按需同步 | ✔️ | ✔️ | 异地多活 |
| 分片集群 | 无 | ❌ | ❌ | 超大规模队列 |
选择建议
- 生产环境:优先使用 镜像队列集群(需权衡性能与冗余)
- 异地容灾:结合 联邦集群 + 镜像队列
- 海量数据:考虑 分片集群(但需业务适配)
RabbitMQ 可靠传输
【困难】RabbitMQ 如何保证消息不丢失?⭐⭐⭐
RabbitMQ 从生产、存储、消费三个环节共同保障。
生产:生产 ACK + 失败重试
- 生产 ACK:开启发布确认模式(Publisher Confirm)——异步监听
Basic.Ack,收到回执才认为发送成功。 - 失败重试:发送失败时,进行重试或记录日志等补偿操作。
存储:持久化、副本+故障转移
- 持久化
- 队列持久化:声明队列时设置
durable = true。 - 消息持久化:发送消息时设置
deliveryMode = 2(PERSISTENT)。
- 队列持久化:声明队列时设置
- 副本机制:搭建镜像队列 (Mirrored Queues),将消息复制到集群多个节点,避免单点故障。
消费:手动 ACK
- 处理业务逻辑成功后,调用
channel.basicAck()进行确认。 - 处理失败时,调用
channel.basicNack()决定是重试(重新入队)还是转入死信队列。
【困难】RabbitMQ 如何保证消息不重复?⭐⭐⭐
RabbitMQ 本身不保证消息不重复。
一般需要在消费侧自行实现业务逻辑幂等:
- 查询操作:
SELECT是天然的幂等操作。 - 更新操作:使用乐观锁或带条件的更新。
- 存储唯一性业务 ID,接收消息时做去重判断。
【困难】RabbitMQ 如何保证消息有序?⭐⭐⭐
通过“单一消费者”强制串行,或通过“消息组”保证局部串行,是实现消息有序的关键。
保证有序的两种方案
| 方案 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 单一消费者 | 一个队列只配置一个消费者,串行处理。 | 简单,绝对保序。 | 吞吐量低,无法水平扩展。 | 消息量极小,顺序性要求绝对严格的场景。 |
| 消息组 | 为消息设置 group_id(如订单 ID),相同 ID 的消息由同一消费者串行处理。 | 平衡顺序与性能,允许不同组并发。 | 配置稍复杂。 | 推荐。需保证局部顺序的场景(如:同一订单的操作有序)。 |
最佳实践建议
- 优先评估需求:很多业务可通过幂等性和状态机设计避免强顺序依赖。
- 首选消息组方案:在需要保证顺序时,这是平衡吞吐量和顺序性的最佳选择。
- 避免无序操作:慎用
requeue=true,失败消息可转入死信队列。
【困难】RabbitMQ 如何应对消息堆积?⭐⭐⭐
加速消费是根本,限流生产是保底。
短期方案:扩容 + 降级
长期方案:优化消费端
增加消费者:如果消息不要求有序,可以启动多个消费线程或多个消费者实例。
优化消费逻辑:采用批量处理,减少 I/O 操作。
使用手动确认模式:确保业务逻辑成功完成后才发送 ACK,避免消息丢失。
辅助方案:管理生产与队列
- 生产端限流:控制发送速率,避免压垮系统。
- 设置队列最大长度:通过
x-max-length限制容量,超出时丢弃最旧的消息。 - 设置消息 TTL:通过
x-message-ttl使过期消息自动丢弃,保证消息时效性。 - 结合死信队列:记录被丢弃的消息,用于审计和后续处理。
【中等】RabbitMQ 如何实现背压机制?
RabbitMQ 通过一套连锁反应机制实现背压,将消费者的处理压力反向传导至生产者,迫使生产者降速,避免系统被压垮。
背压触发与传导流程
起点:消费者限流
- 机制:消费者设置较小的 QoS 预取值(如
prefetch=1)。 - 效果:当消费者处理变慢,未确认消息数达到上限时,Broker 立即停止向该消费者推送新消息。
- 机制:消费者设置较小的 QoS 预取值(如
中间环节:Broker 积压
- 效果:消息在队列中快速堆积,消耗 Broker 的内存和磁盘资源。
终点:生产者被限速
- 机制:当 Broker 资源(内存/磁盘)达到阈值时,自动阻塞生产者的连接。
- 效果:生产者的发送操作被暂停或变慢,背压成功传导至源头。
关键配置与监控
- 必须使用手动确认模式:这是 QoS 生效的前提。
- 设置小预取值:是启动背压链条的关键(如 1-10)。
- 监控队列长度:队列积压是背压触发的明显信号。
- 监听连接阻塞:生产者通过监听器感知背压,进行日志记录或告警。
核心价值
这套机制确保了系统的吞吐量由最慢的消费者决定,而非由最快的生产者决定,从而优雅地实现了系统自我保护。
一句话总结:通过 消费者 QoS 触发,经 Broker 积压 传导,最终由 Broker 流控 作用于生产者,形成完整的背压闭环。
RabbitMQ 架构
【中等】RabbitMQ 如何实现延迟队列?⭐
RabbitMQ 实现延迟队列主要有两种方式:
| 方法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 死信队列+TTL | 让消息先进入一个有过期时间(TTL) 的队列,消息过期后自动被转发到死信交换机,再路由到最终消费队列 | 稳定可靠,无需额外插件 | 不灵活,需为不同延迟时间创建多个队列;定时不精确 | 允许一定时间误差的简单延迟任务 |
rabbitmq_delayed_message_exchange 插件 | 使用一种特殊的交换机。发送消息时通过 x-delay 参数为每条消息单独设置延迟时间 | 定时精确,使用简便 | 需安装插件,大量延迟消息可能影响内存 | 推荐方案,要求定时精确的场景 |
【中等】RabbitMQ 中无法路由的消息会去到哪里?⭐
在 RabbitMQ 中,无法路由的消息去向由生产者发送时的 mandatory 参数决定:
mandatory = false(默认值):消息被 Broker 直接丢弃。mandatory = true:消息通过ReturnCallback机制返回给生产者进行处理。
重要提示:无法路由的消息不会自动进入死信队列(DLQ),因为死信队列用于处理已成功入队但后被拒绝或过期的消息。
【中等】RabbitMQ 中消息什么时候会进入死信交换机?⭐
RabbitMQ 中,消息会在以下三种情况下进入死信交换机(DLX):
- 被拒绝 (Rejected):消费者拒绝消息(
basic.reject或basic.nack)且不重新入队(requeue=false)。 - 已过期 (Expired):消息的存活时间(TTL)到期。
- 队列满 (Overflowed):队列达到最大长度限制,最老的消息会被挤出。
核心前提:必须在声明原始队列时通过 x-dead-letter-exchange 参数预先配置好死信交换机。
【中等】RabbitMQ 的镜像队列和 Quorum Queue 有什么区别?
RabbitMQ 官方自 3.8.x 版本起,**推荐优先使用 Quorum Queue **作为高可用解决方案。
- 镜像队列:主从异步复制,重性能、弱一致(可能丢消息)。
- 仲裁队列:基于 Raft 共识,重安全、强一致(不丢消息)。
核心区别对比
| 特性 | 镜像队列 | 仲裁队列 |
|---|---|---|
| 复制机制 | 主从异步复制 | Raft 共识算法 |
| 数据一致性 | 最终一致性(主节点宕机可能丢失消息) | 强一致性(消息确认即安全,绝不丢失) |
| 性能 | 延迟低,吞吐量高(只需主节点确认) | 延迟高,吞吐量相对低(需多数节点确认) |
| 故障恢复 | 快,但可能选数据落后的节点为主 | 慢,但保证新主数据最全,更安全 |
| 设计目标 | 灵活、高性能 | 数据安全、强一致 |
| 适用场景 | 允许微量丢失的非关键业务、低延迟场景 | 金融、交易等关键业务,要求数据零丢失 |
选择建议
- 优先选择仲裁队列:特别是对于新项目和关键业务,其数据安全性是首要优势。
- 仅在对延迟有极端要求,且可容忍消息丢失时,才考虑镜像队列。
【中等】RabbitMQ 如何通过插件扩展功能?常用的插件有哪些?
RabbitMQ 借助插件机制扩展功能,可通过其提供的 rabbitmq-plugins 工具管理插件。
启用插件的命令:
rabbitmq-plugins enable <插件名>禁用插件的命令:
rabbitmq-plugins disable <插件名>常用的 RabbitMQ 插件有:
rabbitmq_management:用于管理 RabbitMQ 的 Web 控制台插件,提供图形界面监控和管理。rabbitmq_federation:允许 RabbitMQ 节点和集群跨广域网通信。rabbitmq_shovel:用于桥接不同 RabbitMQ 节点,实现消息转发。rabbitmq_delayed_message_exchange:支持延迟消息,可在指定时间后投递消息。rabbitmq_auth_backend_ldap:允许 RabbitMQ 通过 LDAP(轻量级目录访问协议)进行用户认证。
【中等】RabbitMQ 如何实现延迟队列?
原生方案:TTL+死信队列(DLX)
核心原理:通过消息 TTL(存活时间)和死信交换机(DLX)实现延迟投递。
实现步骤
- 创建延迟队列:设置
x-message-ttl(消息过期时间)和x-dead-letter-exchange(死信交换机) - 消息投递:发送到延迟队列,等待 TTL 到期
- 自动转发:过期后由 DLX 将消息路由到目标队列
- 消费者:从目标队列获取延迟消息
- 创建延迟队列:设置
特点
- 固定延迟时间(每条消息 TTL 需单独设置)
- 无需插件,但灵活性较差
插件方案:rabbitmq_delayed_message_exchange
核心原理:官方插件提供
x-delayed-message交换机类型,支持动态延迟时间。实现步骤
- 启用插件:安装
rabbitmq_delayed_message_exchange - 声明交换机:类型设为
x-delayed-message,并指定路由规则(如 direct/topic) - 发送消息:通过
headers设置x-delay参数(毫秒级延迟) - 自动投递:插件内部调度,到期后投递到目标队列
- 启用插件:安装
特点
- 支持动态延迟时间(每条消息可独立设置)
- 高精度(毫秒级)
- 需额外安装插件
方案对比
| 维度 | TTL+DLX | 插件方案 |
|---|---|---|
| 灵活性 | 固定延迟(队列级别) | 动态延迟(消息级别) |
| 精度 | 秒级 | 毫秒级 |
| 复杂度 | 无需插件,需配置 DLX | 需安装插件 |
| 适用场景 | 简单延迟需求(如统一 30 秒延迟) | 复杂延迟需求(如不同订单超时时间) |
| 缺点 | 队列中消息若阻塞,会延迟后续消息投递(需确保 FIFO 消费) | 大量延迟消息可能占用较高内存 |
示例代码(插件方案)
# 声明延迟交换机
channel.exchange_declare(
exchange='delayed_exchange',
exchange_type='x-delayed-message', # 关键参数
arguments={'x-delayed-type': 'direct'}
)
# 发送延迟消息(延迟 5 秒)
channel.basic_publish(
exchange='delayed_exchange',
routing_key='order_queue',
body=message,
properties=pika.BasicProperties(
headers={'x-delay': 5000} # 延迟毫秒数
)
)RabbitMQ 事务
【中等】RabbitMQ 如何实现事务机制?
RabbitMQ 的事务机制(Transaction)通过 信道(Channel) 提供了一种保证消息可靠投递的机制,但其设计简单且对性能影响较大。
RabbitMQ 的事务通过同步机制确保消息投递的原子性,但性能代价高。在绝大多数生产环境中,推荐使用 Publisher Confirms 替代事务,以兼顾可靠性和吞吐量。
事务的核心操作
开启事务:
channel.txSelect(); // 开启事务模式提交事务:
channel.txCommit(); // 提交事务,消息真正投递到队列回滚事务:
channel.txRollback(); // 回滚事务,丢弃未提交的消息
事务的工作流程
- 生产者发送消息到 RabbitMQ(消息暂存于信道缓冲区,未写入队列)。
- 执行
txCommit():消息持久化到队列;若失败或调用txRollback(),消息丢弃。 - 同步阻塞:事务提交/回滚需等待 Broker 确认,性能较低。
事务的局限性
- 性能差:每次提交需等待 Broker 确认,吞吐量显著下降(通常降低 100~200 倍)。
- 无分布式事务:仅保证生产者到 Broker 的可靠性,不涉及消费者或下游系统。
- 不推荐高频使用:适合低频关键业务,高并发场景建议用 确认机制(Publisher Confirms)。
事务 vs. 确认机制(Publisher Confirms)
| 特性 | 事务(Transaction) | 确认机制(Publisher Confirms) |
|---|---|---|
| 可靠性 | 强一致(同步阻塞) | 最终一致(异步) |
| 性能 | 极低(同步等待) | 高(异步回调) |
| 适用场景 | 低频关键消息(如支付) | 高频业务(如日志、订单) |
| 复杂度 | 简单 | 需处理确认/未确认逻辑 |
代码示例
try {
channel.txSelect(); // 开启事务
channel.basicPublish("", "queue1", null, msg1.getBytes());
channel.basicPublish("", "queue2", null, msg2.getBytes());
channel.txCommit(); // 提交事务
} catch (Exception e) {
channel.txRollback(); // 回滚事务
// 处理异常
}使用建议
优先选择 Confirm 模式:
channel.confirmSelect(); // 开启确认模式 channel.addConfirmListener(...); // 异步回调事务适用场景:
- 严格保证单批次消息的原子性(如同时投递订单和库存消息)。
- 兼容旧版 RabbitMQ(Confirm 模式需 v3.3+)。