Jetty 快速入门
Jetty 快速入门
Jetty 简介
jetty 是什么?
jetty 是轻量级的 web 服务器和 servlet 引擎。
它的最大特点是:可以很方便的作为嵌入式服务器。
它是 eclipse 的一个开源项目。不用怀疑,就是你常用的那个 eclipse。
它是使用 Java 开发的,所以天然对 Java 支持良好。
什么是嵌入式服务器?
以 jetty 来说明,就是只要引入 jetty 的 jar 包,可以通过直接调用其 API 的方式来启动 web 服务。
用过 Tomcat、Resin 等服务器的朋友想必不会陌生那一套安装、配置、部署的流程吧,还是挺繁琐的。使用 jetty,就不需要这些过程了。
jetty 非常适用于项目的开发、测试,因为非常快捷。如果想用于生产环境,则需要谨慎考虑,它不一定能像成熟的 Tomcat、Resin 等服务器一样支持企业级 Java EE 的需要。
Jetty 的使用
我觉得嵌入式启动方式的一个好处在于:可以直接运行项目,无需每次部署都得再配置服务器。
jetty 的嵌入式启动使用有两种方式:
API 方式
maven 插件方式
API 方式
添加 maven 依赖
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>9.3.2.v20150730</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-annotations</artifactId>
<version>9.3.2.v20150730</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>apache-jsp</artifactId>
<version>9.3.2.v20150730</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>apache-jstl</artifactId>
<version>9.3.2.v20150730</version>
<scope>test</scope>
</dependency>
官方的启动代码
public class SplitFileServer
{
public static void main( String[] args ) throws Exception
{
// 创建Server对象,并绑定端口
Server server = new Server();
ServerConnector connector = new ServerConnector(server);
connector.setPort(8090);
server.setConnectors(new Connector[] { connector });
// 创建上下文句柄,绑定上下文路径。这样启动后的url就会是:http://host:port/context
ResourceHandler rh0 = new ResourceHandler();
ContextHandler context0 = new ContextHandler();
context0.setContextPath("/");
// 绑定测试资源目录(在本例的配置目录dir0的路径是src/test/resources/dir0)
File dir0 = MavenTestingUtils.getTestResourceDir("dir0");
context0.setBaseResource(Resource.newResource(dir0));
context0.setHandler(rh0);
// 和上面的例子一样
ResourceHandler rh1 = new ResourceHandler();
ContextHandler context1 = new ContextHandler();
context1.setContextPath("/");
File dir1 = MavenTestingUtils.getTestResourceDir("dir1");
context1.setBaseResource(Resource.newResource(dir1));
context1.setHandler(rh1);
// 绑定两个资源句柄
ContextHandlerCollection contexts = new ContextHandlerCollection();
contexts.setHandlers(new Handler[] { context0, context1 });
server.setHandler(contexts);
// 启动
server.start();
// 打印dump时的信息
System.out.println(server.dump());
// join当前线程
server.join();
}
}
直接运行 Main 方法,就可以启动 web 服务。
注:以上代码在 eclipse 中运行没有问题,如果想在 Intellij 中运行还需要为它指定配置文件。
如果想了解在 Eclipse 和 Intellij 都能运行的通用方法可以参考我的 github 代码示例。
我的实现也是参考 springside 的方式。
代码行数有点多,不在这里贴代码了。
Maven 插件方式
如果你熟悉 maven,那么实在太简单了
注: Maven 版本必须在 3.3 及以上版本。
(1) 添加 maven 插件
<plugin>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-maven-plugin</artifactId>
<version>9.3.12.v20160915</version>
</plugin>
(2) 执行 maven 命令:
mvn jetty:run
讲真,就是这么简单。jetty 默认会为你创建一个 web 服务,地址为 127.0.0.1:8080。
当然,你也可以在插件中配置你的 webapp 环境
<plugin>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-maven-plugin</artifactId>
<version>9.3.12.v20160915</version>
<configuration>
<webAppSourceDirectory>${project.basedir}/src/staticfiles</webAppSourceDirectory>
<!-- 配置webapp -->
<webApp>
<contextPath>/</contextPath>
<descriptor>${project.basedir}/src/over/here/web.xml</descriptor>
<jettyEnvXml>${project.basedir}/src/over/here/jetty-env.xml</jettyEnvXml>
</webApp>
<!-- 配置classes -->
<classesDirectory>${project.basedir}/somewhere/else</classesDirectory>
<scanClassesPattern>
<excludes>
<exclude>**/Foo.class</exclude>
</excludes>
</scanClassesPattern>
<scanTargets>
<scanTarget>src/mydir</scanTarget>
<scanTarget>src/myfile.txt</scanTarget>
</scanTargets>
<!-- 扫描target目录下的资源文件 -->
<scanTargetPatterns>
<scanTargetPattern>
<directory>src/other-resources</directory>
<includes>
<include>**/*.xml</include>
<include>**/*.properties</include>
</includes>
<excludes>
<exclude>**/myspecial.xml</exclude>
<exclude>**/myspecial.properties</exclude>
</excludes>
</scanTargetPattern>
</scanTargetPatterns>
</configuration>
</plugin>
官方给的 jetty-env.xml 范例
<?xml version="1.0"?>
<!DOCTYPE Configure PUBLIC "-//Mort Bay Consulting//DTD Configure//EN" "http://jetty.mortbay.org/configure.dtd">
<Configure class="org.eclipse.jetty.webapp.WebAppContext">
<!-- Add an EnvEntry only valid for this webapp -->
<New id="gargle" class="org.eclipse.jetty.plus.jndi.EnvEntry">
<Arg>gargle</Arg>
<Arg type="java.lang.Double">100</Arg>
<Arg type="boolean">true</Arg>
</New>
<!-- Add an override for a global EnvEntry -->
<New id="wiggle" class="org.eclipse.jetty.plus.jndi.EnvEntry">
<Arg>wiggle</Arg>
<Arg type="java.lang.Double">55.0</Arg>
<Arg type="boolean">true</Arg>
</New>
<!-- an XADataSource -->
<New id="mydatasource99" class="org.eclipse.jetty.plus.jndi.Resource">
<Arg>jdbc/mydatasource99</Arg>
<Arg>
<New class="com.atomikos.jdbc.SimpleDataSourceBean">
<Set name="xaDataSourceClassName">org.apache.derby.jdbc.EmbeddedXADataSource</Set>
<Set name="xaDataSourceProperties">databaseName=testdb99;createDatabase=create</Set>
<Set name="UniqueResourceName">mydatasource99</Set>
</New>
</Arg>
</New>
</Configure>
Jetty 的架构
Jetty 架构简介
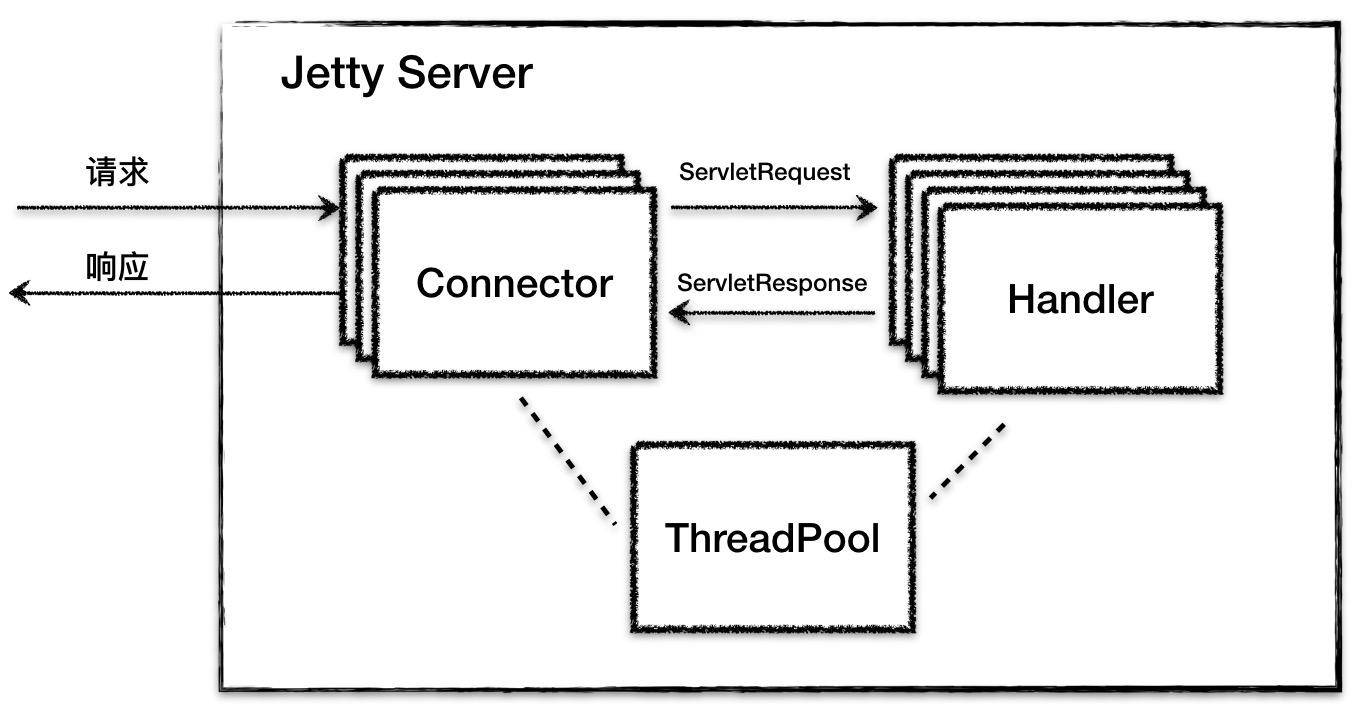
Jetty Server 就是由多个 Connector(连接器)、多个 Handler(处理器),以及一个线程池组成。
跟 Tomcat 一样,Jetty 也有 HTTP 服务器和 Servlet 容器的功能,因此 Jetty 中的 Connector 组件和 Handler 组件分别来实现这两个功能,而这两个组件工作时所需要的线程资源都直接从一个全局线程池 ThreadPool 中获取。
Jetty Server 可以有多个 Connector 在不同的端口上监听客户请求,而对于请求处理的 Handler 组件,也可以根据具体场景使用不同的 Handler。这样的设计提高了 Jetty 的灵活性,需要支持 Servlet,则可以使用 ServletHandler;需要支持 Session,则再增加一个 SessionHandler。也就是说我们可以不使用 Servlet 或者 Session,只要不配置这个 Handler 就行了。
为了启动和协调上面的核心组件工作,Jetty 提供了一个 Server 类来做这个事情,它负责创建并初始化 Connector、Handler、ThreadPool 组件,然后调用 start 方法启动它们。
Jetty 和 Tomcat 架构区别
对比一下 Tomcat 的整体架构图,你会发现 Tomcat 在整体上跟 Jetty 很相似,它们的第一个区别是 Jetty 中没有 Service 的概念,Tomcat 中的 Service 包装了多个连接器和一个容器组件,一个 Tomcat 实例可以配置多个 Service,不同的 Service 通过不同的连接器监听不同的端口;而 Jetty 中 Connector 是被所有 Handler 共享的。
第二个区别是,在 Tomcat 中每个连接器都有自己的线程池,而在 Jetty 中所有的 Connector 共享一个全局的线程池。
Connector 组件
跟 Tomcat 一样,Connector 的主要功能是对 I/O 模型和应用层协议的封装。I/O 模型方面,最新的 Jetty 9 版本只支持 NIO,因此 Jetty 的 Connector 设计有明显的 Java NIO 通信模型的痕迹。至于应用层协议方面,跟 Tomcat 的 Processor 一样,Jetty 抽象出了 Connection 组件来封装应用层协议的差异。
服务端在 NIO 通信上主要完成了三件事情:监听连接、I/O 事件查询以及数据读写。因此 Jetty 设计了Acceptor、SelectorManager 和 Connection 来分别做这三件事情
Acceptor
Acceptor 用于接受请求。跟 Tomcat 一样,Jetty 也有独立的 Acceptor 线程组用于处理连接请求。在 Connector 的实现类 ServerConnector 中,有一个 _acceptors 的数组,在 Connector 启动的时候, 会根据 _acceptors 数组的长度创建对应数量的 Acceptor,而 Acceptor 的个数可以配置。
for (int i = 0; i < _acceptors.length; i++)
{
Acceptor a = new Acceptor(i);
getExecutor().execute(a);
}
Acceptor 是 ServerConnector 中的一个内部类,同时也是一个 Runnable,Acceptor 线程是通过 getExecutor() 得到的线程池来执行的,前面提到这是一个全局的线程池。
Acceptor 通过阻塞的方式来接受连接,这一点跟 Tomcat 也是一样的。
public void accept(int acceptorID) throws IOException
{
ServerSocketChannel serverChannel = _acceptChannel;
if (serverChannel != null && serverChannel.isOpen())
{
// 这里是阻塞的
SocketChannel channel = serverChannel.accept();
// 执行到这里时说明有请求进来了
accepted(channel);
}
}
接受连接成功后会调用 accepted() 函数,accepted() 函数中会将 SocketChannel 设置为非阻塞模式,然后交给 Selector 去处理,因此这也就到了 Selector 的地界了。
private void accepted(SocketChannel channel) throws IOException
{
channel.configureBlocking(false);
Socket socket = channel.socket();
configure(socket);
// _manager 是 SelectorManager 实例,里面管理了所有的 Selector 实例
_manager.accept(channel);
}
SelectorManager
Jetty 的 Selector 由 SelectorManager 类管理,而被管理的 Selector 叫作 ManagedSelector。SelectorManager 内部有一个 ManagedSelector 数组,真正干活的是 ManagedSelector。咱们接着上面分析,看看在 SelectorManager 在 accept 方法里做了什么。
public void accept(SelectableChannel channel, Object attachment)
{
// 选择一个 ManagedSelector 来处理 Channel
final ManagedSelector selector = chooseSelector();
// 提交一个任务 Accept 给 ManagedSelector
selector.submit(selector.new Accept(channel, attachment));
}
SelectorManager 从本身的 Selector 数组中选择一个 Selector 来处理这个 Channel,并创建一个任务 Accept 交给 ManagedSelector,ManagedSelector 在处理这个任务主要做了两步:
第一步,调用 Selector 的 register 方法把 Channel 注册到 Selector 上,拿到一个 SelectionKey。
_key = _channel.register(selector, SelectionKey.OP_ACCEPT, this);
第二步,创建一个 EndPoint 和 Connection,并跟这个 SelectionKey(Channel)绑在一起:
private void createEndPoint(SelectableChannel channel, SelectionKey selectionKey) throws IOException
{
//1. 创建 Endpoint
EndPoint endPoint = _selectorManager.newEndPoint(channel, this, selectionKey);
//2. 创建 Connection
Connection connection = _selectorManager.newConnection(channel, endPoint, selectionKey.attachment());
//3. 把 Endpoint、Connection 和 SelectionKey 绑在一起
endPoint.setConnection(connection);
selectionKey.attach(endPoint);
}
这里需要你特别注意的是,ManagedSelector 并没有直接调用 EndPoint 的方法去处理数据,而是通过调用 EndPoint 的方法返回一个 Runnable,然后把这个 Runnable 扔给线程池执行,所以你能猜到,这个 Runnable 才会去真正读数据和处理请求。
Connection
这个 Runnable 是 EndPoint 的一个内部类,它会调用 Connection 的回调方法来处理请求。Jetty 的 Connection 组件类比就是 Tomcat 的 Processor,负责具体协议的解析,得到 Request 对象,并调用 Handler 容器进行处理。下面我简单介绍一下它的具体实现类 HttpConnection 对请求和响应的处理过程。
请求处理:HttpConnection 并不会主动向 EndPoint 读取数据,而是向在 EndPoint 中注册一堆回调方法:
getEndPoint().fillInterested(_readCallback);
这段代码就是告诉 EndPoint,数据到了你就调我这些回调方法 _readCallback 吧,有点异步 I/O 的感觉,也就是说 Jetty 在应用层面模拟了异步 I/O 模型。
而在回调方法 _readCallback 里,会调用 EndPoint 的接口去读数据,读完后让 HTTP 解析器去解析字节流,HTTP 解析器会将解析后的数据,包括请求行、请求头相关信息存到 Request 对象里。
响应处理:Connection 调用 Handler 进行业务处理,Handler 会通过 Response 对象来操作响应流,向流里面写入数据,HttpConnection 再通过 EndPoint 把数据写到 Channel,这样一次响应就完成了。
到此你应该了解了 Connector 的工作原理,下面我画张图再来回顾一下 Connector 的工作流程。
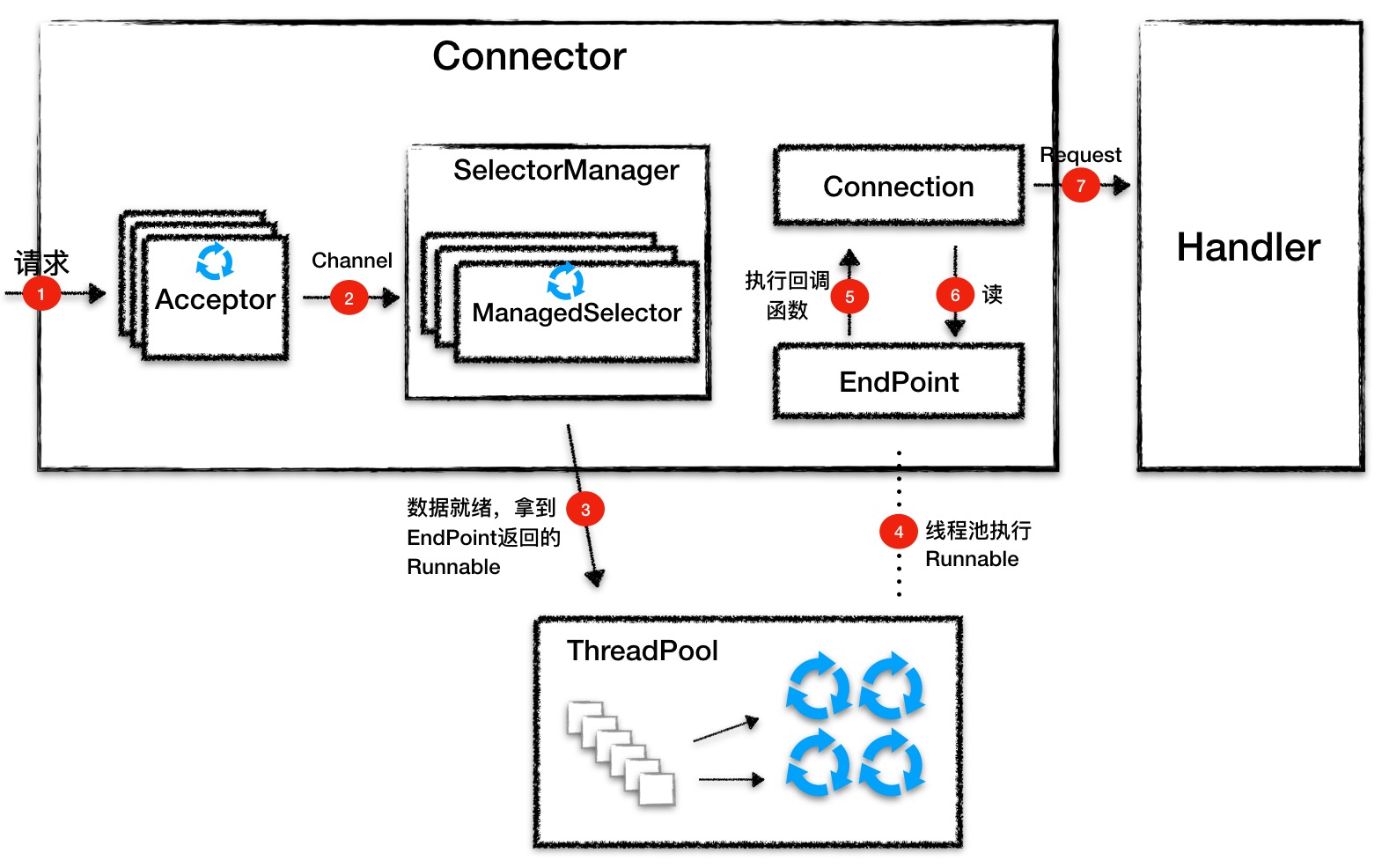
Acceptor 监听连接请求,当有连接请求到达时就接受连接,一个连接对应一个 Channel,Acceptor 将 Channel 交给 ManagedSelector 来处理。
ManagedSelector 把 Channel 注册到 Selector 上,并创建一个 EndPoint 和 Connection 跟这个 Channel 绑定,接着就不断地检测 I/O 事件。
I/O 事件到了就调用 EndPoint 的方法拿到一个 Runnable,并扔给线程池执行。
线程池中调度某个线程执行 Runnable。
Runnable 执行时,调用回调函数,这个回调函数是 Connection 注册到 EndPoint 中的。
回调函数内部实现,其实就是调用 EndPoint 的接口方法来读数据。
Connection 解析读到的数据,生成请求对象并交给 Handler 组件去处理。
Handler 组件
Jetty 的 Handler 设计是它的一大特色,Jetty 本质就是一个 Handler 管理器,Jetty 本身就提供了一些默认 Handler 来实现 Servlet 容器的功能,你也可以定义自己的 Handler 来添加到 Jetty 中,这体现了“微内核 + 插件”的设计思想。
Handler 就是一个接口,它有一堆实现类,Jetty 的 Connector 组件调用这些接口来处理 Servlet 请求。
public interface Handler extends LifeCycle, Destroyable
{
// 处理请求的方法
public void handle(String target, Request baseRequest, HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException;
// 每个 Handler 都关联一个 Server 组件,被 Server 管理
public void setServer(Server server);
public Server getServer();
// 销毁方法相关的资源
public void destroy();
}
方法说明:
Handler的handle方法跟 Tomcat 容器组件的 service 方法一样,它有ServletRequest和ServeletResponse两个参数。- 因为任何一个
Handler都需要关联一个Server组件,Handler需要被Server组件来管理。Handler通过setServer和getServer方法绑定Server。 Handler会加载一些资源到内存,因此通过设置destroy方法来销毁。
Handler 继承关系
Handler 只是一个接口,完成具体功能的还是它的子类。那么 Handler 有哪些子类呢?它们的继承关系又是怎样的?这些子类是如何实现 Servlet 容器功能的呢?
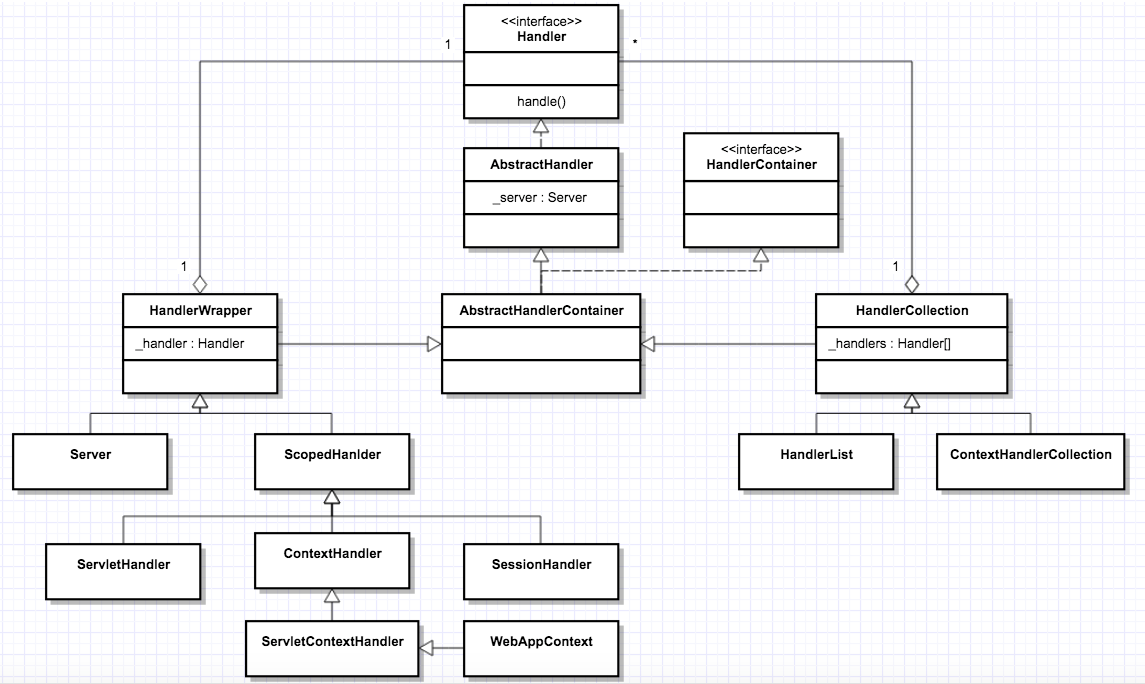
在 AbstractHandler 之下有 AbstractHandlerContainer,为什么需要这个类呢?这其实是个过渡,为了实现链式调用,一个 Handler 内部必然要有其他 Handler 的引用,所以这个类的名字里才有 Container,意思就是这样的 Handler 里包含了其他 Handler 的引用。
HandlerWrapper 和 HandlerCollection 都是 Handler,但是这些 Handler 里还包括其他 Handler 的引用。不同的是,HandlerWrapper 只包含一个其他 Handler 的引用,而 HandlerCollection 中有一个 Handler 数组的引用。
HandlerWrapper 有两个子类:Server 和 ScopedHandler。
- Server 比较好理解,它本身是 Handler 模块的入口,必然要将请求传递给其他 Handler 来处理,为了触发其他 Handler 的调用,所以它是一个 HandlerWrapper。
- ScopedHandler 也是一个比较重要的 Handler,实现了“具有上下文信息”的责任链调用。为什么我要强调“具有上下文信息”呢?那是因为 Servlet 规范规定 Servlet 在执行过程中是有上下文的。那么这些 Handler 在执行过程中如何访问这个上下文呢?这个上下文又存在什么地方呢?答案就是通过 ScopedHandler 来实现的。
HandlerCollection 其实维护了一个 Handler 数组。这是为了同时支持多个 Web 应用,如果每个 Web 应用有一个 Handler 入口,那么多个 Web 应用的 Handler 就成了一个数组,比如 Server 中就有一个 HandlerCollection,Server 会根据用户请求的 URL 从数组中选取相应的 Handler 来处理,就是选择特定的 Web 应用来处理请求。
Handler 可以分成三种类型:
- 第一种是协调 Handler,这种 Handler 负责将请求路由到一组 Handler 中去,比如 HandlerCollection,它内部持有一个 Handler 数组,当请求到来时,它负责将请求转发到数组中的某一个 Handler。
- 第二种是过滤器 Handler,这种 Handler 自己会处理请求,处理完了后再把请求转发到下一个 Handler,比如图上的 HandlerWrapper,它内部持有下一个 Handler 的引用。需要注意的是,所有继承了 HandlerWrapper 的 Handler 都具有了过滤器 Handler 的特征,比如 ContextHandler、SessionHandler 和 WebAppContext 等。
- 第三种是内容 Handler,说白了就是这些 Handler 会真正调用 Servlet 来处理请求,生成响应的内容,比如 ServletHandler。如果浏览器请求的是一个静态资源,也有相应的 ResourceHandler 来处理这个请求,返回静态页面。
实现 Servlet 规范
ServletHandler、ContextHandler 以及 WebAppContext 等,它们实现了 Servlet 规范。
Servlet 规范中有 Context、Servlet、Filter、Listener 和 Session 等,Jetty 要支持 Servlet 规范,就需要有相应的 Handler 来分别实现这些功能。因此,Jetty 设计了 3 个组件:ContextHandler、ServletHandler 和 SessionHandler 来实现 Servle 规范中规定的功能,而WebAppContext 本身就是一个 ContextHandler,另外它还负责管理 ServletHandler 和 SessionHandler。
ContextHandler 会创建并初始化 Servlet 规范里的 ServletContext 对象,同时 ContextHandler 还包含了一组能够让你的 Web 应用运行起来的 Handler,可以这样理解,Context 本身也是一种 Handler,它里面包含了其他的 Handler,这些 Handler 能处理某个特定 URL 下的请求。比如,ContextHandler 包含了一个或者多个 ServletHandler。
ServletHandler 实现了 Servlet 规范中的 Servlet、Filter 和 Listener 的功能。ServletHandler 依赖 FilterHolder、ServletHolder、ServletMapping、FilterMapping 这四大组件。FilterHolder 和 ServletHolder 分别是 Filter 和 Servlet 的包装类,每一个 Servlet 与路径的映射会被封装成 ServletMapping,而 Filter 与拦截 URL 的映射会被封装成 FilterMapping。
SessionHandler 用来管理 Session。除此之外 WebAppContext 还有一些通用功能的 Handler,比如 SecurityHandler 和 GzipHandler,同样从名字可以知道这些 Handler 的功能分别是安全控制和压缩 / 解压缩。
WebAppContext 会将这些 Handler 构建成一个执行链,通过这个链会最终调用到我们的业务 Servlet。
Jetty 的线程策略
传统 Selector 编程模型
常规的 NIO 编程思路是,将 I/O 事件的侦测和请求的处理分别用不同的线程处理。具体过程是:
启动一个线程,在一个死循环里不断地调用 select 方法,检测 Channel 的 I/O 状态,一旦 I/O 事件达到,比如数据就绪,就把该 I/O 事件以及一些数据包装成一个 Runnable,将 Runnable 放到新线程中去处理。
在这个过程中按照职责划分,有两个线程在干活,一个是 I/O 事件检测线程,另一个是 I/O 事件处理线程。这样的好处是它们互不干扰和阻塞对方。
Jetty 的 Selector 编程模型
将 I/O 事件检测和业务处理这两种工作分开的思路也有缺点:当 Selector 检测读就绪事件时,数据已经被拷贝到内核中的缓存了,同时 CPU 的缓存中也有这些数据了,我们知道 CPU 本身的缓存比内存快多了,这时当应用程序去读取这些数据时,如果用另一个线程去读,很有可能这个读线程使用另一个 CPU 核,而不是之前那个检测数据就绪的 CPU 核,这样 CPU 缓存中的数据就用不上了,并且线程切换也需要开销。
因此 Jetty 的 Connector 做了一个大胆尝试,那就是把 I/O 事件的生产和消费放到同一个线程来处理,如果这两个任务由同一个线程来执行,如果执行过程中线程不阻塞,操作系统会用同一个 CPU 核来执行这两个任务,这样就能利用 CPU 缓存了。
ManagedSelector
ManagedSelector 的本质就是一个 Selector,负责 I/O 事件的检测和分发。为了方便使用,Jetty 在 Java 原生的 Selector 上做了一些扩展,就变成了 ManagedSelector,我们先来看看它有哪些成员变量:
public class ManagedSelector extends ContainerLifeCycle implements Dumpable
{
// 原子变量,表明当前的 ManagedSelector 是否已经启动
private final AtomicBoolean _started = new AtomicBoolean(false);
// 表明是否阻塞在 select 调用上
private boolean _selecting = false;
// 管理器的引用,SelectorManager 管理若干 ManagedSelector 的生命周期
private final SelectorManager _selectorManager;
//ManagedSelector 不止一个,为它们每人分配一个 id
private final int _id;
// 关键的执行策略,生产者和消费者是否在同一个线程处理由它决定
private final ExecutionStrategy _strategy;
//Java 原生的 Selector
private Selector _selector;
//"Selector 更新任务 " 队列
private Deque<SelectorUpdate> _updates = new ArrayDeque<>();
private Deque<SelectorUpdate> _updateable = new ArrayDeque<>();
...
}
这些成员变量中其他的都好理解,就是“Selector 更新任务”队列_updates和执行策略_strategy可能不是很直观。
SelectorUpdate 接口
为什么需要一个“Selector 更新任务”队列呢,对于 Selector 的用户来说,我们对 Selector 的操作无非是将 Channel 注册到 Selector 或者告诉 Selector 我对什么 I/O 事件感兴趣,那么这些操作其实就是对 Selector 状态的更新,Jetty 把这些操作抽象成 SelectorUpdate 接口。
/**
* A selector update to be done when the selector has been woken.
*/
public interface SelectorUpdate
{
void update(Selector selector);
}
这意味着如果你不能直接操作 ManageSelector 中的 Selector,而是需要向 ManagedSelector 提交一个任务类,这个类需要实现 SelectorUpdate 接口 update 方法,在 update 方法里定义你想要对 ManagedSelector 做的操作。
比如 Connector 中 Endpoint 组件对读就绪事件感兴趣,它就向 ManagedSelector 提交了一个内部任务类 ManagedSelector.SelectorUpdate:
_selector.submit(_updateKeyAction);
这个_updateKeyAction就是一个 SelectorUpdate 实例,它的 update 方法实现如下:
private final ManagedSelector.SelectorUpdate _updateKeyAction = new ManagedSelector.SelectorUpdate()
{
@Override
public void update(Selector selector)
{
// 这里的 updateKey 其实就是调用了 SelectionKey.interestOps(OP_READ);
updateKey();
}
};
我们看到在 update 方法里,调用了 SelectionKey 类的 interestOps 方法,传入的参数是OP_READ,意思是现在我对这个 Channel 上的读就绪事件感兴趣了。
那谁来负责执行这些 update 方法呢,答案是 ManagedSelector 自己,它在一个死循环里拉取这些 SelectorUpdate 任务类逐个执行。
Selectable 接口
那 I/O 事件到达时,ManagedSelector 怎么知道应该调哪个函数来处理呢?其实也是通过一个任务类接口,这个接口就是 Selectable,它返回一个 Runnable,这个 Runnable 其实就是 I/O 事件就绪时相应的处理逻辑。
public interface Selectable
{
// 当某一个 Channel 的 I/O 事件就绪后,ManagedSelector 会调用的回调函数
Runnable onSelected();
// 当所有事件处理完了之后 ManagedSelector 会调的回调函数,我们先忽略。
void updateKey();
}
ManagedSelector 在检测到某个 Channel 上的 I/O 事件就绪时,也就是说这个 Channel 被选中了,ManagedSelector 调用这个 Channel 所绑定的附件类的 onSelected 方法来拿到一个 Runnable。
这句话有点绕,其实就是 ManagedSelector 的使用者,比如 Endpoint 组件在向 ManagedSelector 注册读就绪事件时,同时也要告诉 ManagedSelector 在事件就绪时执行什么任务,具体来说就是传入一个附件类,这个附件类需要实现 Selectable 接口。ManagedSelector 通过调用这个 onSelected 拿到一个 Runnable,然后把 Runnable 扔给线程池去执行。
那 Endpoint 的 onSelected 是如何实现的呢?
@Override
public Runnable onSelected()
{
int readyOps = _key.readyOps();
boolean fillable = (readyOps & SelectionKey.OP_READ) != 0;
boolean flushable = (readyOps & SelectionKey.OP_WRITE) != 0;
// return task to complete the job
Runnable task= fillable
? (flushable
? _runCompleteWriteFillable
: _runFillable)
: (flushable
? _runCompleteWrite
: null);
return task;
}
上面的代码逻辑很简单,就是读事件到了就读,写事件到了就写。
ExecutionStrategy
铺垫了这么多,终于要上主菜了。前面我主要介绍了 ManagedSelector 的使用者如何跟 ManagedSelector 交互,也就是如何注册 Channel 以及 I/O 事件,提供什么样的处理类来处理 I/O 事件,接下来我们来看看 ManagedSelector 是如何统一管理和维护用户注册的 Channel 集合。再回到今天开始的讨论,ManagedSelector 将 I/O 事件的生产和消费看作是生产者消费者模式,为了充分利用 CPU 缓存,生产和消费尽量放到同一个线程处理,那这是如何实现的呢?Jetty 定义了 ExecutionStrategy 接口:
public interface ExecutionStrategy
{
// 只在 HTTP2 中用到,简单起见,我们先忽略这个方法。
public void dispatch();
// 实现具体执行策略,任务生产出来后可能由当前线程执行,也可能由新线程来执行
public void produce();
// 任务的生产委托给 Producer 内部接口,
public interface Producer
{
// 生产一个 Runnable(任务)
Runnable produce();
}
}
我们看到 ExecutionStrategy 接口比较简单,它将具体任务的生产委托内部接口 Producer,而在自己的 produce 方法里来实现具体执行逻辑,也就是生产出来的任务要么由当前线程执行,要么放到新线程中执行。Jetty 提供了一些具体策略实现类:ProduceConsume、ProduceExecuteConsume、ExecuteProduceConsume 和 EatWhatYouKill。它们的区别是:
- ProduceConsume:任务生产者自己依次生产和执行任务,对应到 NIO 通信模型就是用一个线程来侦测和处理一个 ManagedSelector 上所有的 I/O 事件,后面的 I/O 事件要等待前面的 I/O 事件处理完,效率明显不高。通过图来理解,图中绿色表示生产一个任务,蓝色表示执行这个任务。

- ProduceExecuteConsume:任务生产者开启新线程来运行任务,这是典型的 I/O 事件侦测和处理用不同的线程来处理,缺点是不能利用 CPU 缓存,并且线程切换成本高。同样我们通过一张图来理解,图中的棕色表示线程切换。

- ExecuteProduceConsume:任务生产者自己运行任务,但是该策略可能会新建一个新线程以继续生产和执行任务。这种策略也被称为“吃掉你杀的猎物”,它来自狩猎伦理,认为一个人不应该杀死他不吃掉的东西,对应线程来说,不应该生成自己不打算运行的任务。它的优点是能利用 CPU 缓存,但是潜在的问题是如果处理 I/O 事件的业务代码执行时间过长,会导致线程大量阻塞和线程饥饿。

- EatWhatYouKill:这是 Jetty 对 ExecuteProduceConsume 策略的改良,在线程池线程充足的情况下等同于 ExecuteProduceConsume;当系统比较忙线程不够时,切换成 ProduceExecuteConsume 策略。为什么要这么做呢,原因是 ExecuteProduceConsume 是在同一线程执行 I/O 事件的生产和消费,它使用的线程来自 Jetty 全局的线程池,这些线程有可能被业务代码阻塞,如果阻塞得多了,全局线程池中的线程自然就不够用了,最坏的情况是连 I/O 事件的侦测都没有线程可用了,会导致 Connector 拒绝浏览器请求。于是 Jetty 做了一个优化,在低线程情况下,就执行 ProduceExecuteConsume 策略,I/O 侦测用专门的线程处理,I/O 事件的处理扔给线程池处理,其实就是放到线程池的队列里慢慢处理。
分析了这几种线程策略,我们再来看看 Jetty 是如何实现 ExecutionStrategy 接口的。答案其实就是实现 produce 接口生产任务,一旦任务生产出来,ExecutionStrategy 会负责执行这个任务。
private class SelectorProducer implements ExecutionStrategy.Producer
{
private Set<SelectionKey> _keys = Collections.emptySet();
private Iterator<SelectionKey> _cursor = Collections.emptyIterator();
@Override
public Runnable produce()
{
while (true)
{
// 如何 Channel 集合中有 I/O 事件就绪,调用前面提到的 Selectable 接口获取 Runnable, 直接返回给 ExecutionStrategy 去处理
Runnable task = processSelected();
if (task != null)
return task;
// 如果没有 I/O 事件就绪,就干点杂活,看看有没有客户提交了更新 Selector 的任务,就是上面提到的 SelectorUpdate 任务类。
processUpdates();
updateKeys();
// 继续执行 select 方法,侦测 I/O 就绪事件
if (!select())
return null;
}
}
}
SelectorProducer 是 ManagedSelector 的内部类,SelectorProducer 实现了 ExecutionStrategy 中的 Producer 接口中的 produce 方法,需要向 ExecutionStrategy 返回一个 Runnable。在这个方法里 SelectorProducer 主要干了三件事情
- 如果 Channel 集合中有 I/O 事件就绪,调用前面提到的 Selectable 接口获取 Runnable,直接返回给 ExecutionStrategy 去处理。
- 如果没有 I/O 事件就绪,就干点杂活,看看有没有客户提交了更新 Selector 上事件注册的任务,也就是上面提到的 SelectorUpdate 任务类。
- 干完杂活继续执行 select 方法,侦测 I/O 就绪事件。