分布式调度
📖 内容
...小于 1 分钟
服务路由是指通过一定的规则从集群中选择合适的节点。
负载均衡的作用和服务路由的功能看上去很近似,二者有什么区别呢?
负载均衡的目标是提供服务分发而不是解决路由问题,常见的静态、动态负载均衡算法也无法实现精细化的路由管理,但是负载均衡也可以简单看做是路由方案的一种。
服务路由通常用于以下场景,目的在于实现流量隔离:
在高并发场景下,为了应对瞬时海量请求的压力,保障系统的平稳运行,必须预估系统的流量阈值,通过限流规则阻断处理不过来的请求。
流量控制(Flow Control),根据流量、并发线程数、响应时间等指标,把随机到来的流量调整成合适的形状,即流量塑形。避免应用被瞬时的流量高峰冲垮,从而保障应用的高可用性。
流量控制有以下几个角度:
传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。
数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。 虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
为此,需要使用分布式 ID 来解决此问题。本文总结业界常用的分布式 ID 解决方案。
由于 Http 是一种无状态的协议,服务器单单从网络连接上无从知道客户身份。
会话跟踪是 Web 程序中常用的技术,用来跟踪用户的整个会话。常用会话跟踪技术是 Cookie 与 Session。
由于 Http 是一种无状态的协议,服务器单从网络连接上无从知道客户身份。
所以服务器与浏览器为了进行会话跟踪(知道是谁在访问我),就必须主动的去维护一个状态,这个状态用于告知服务端前后两个请求是否来自同一浏览器。而这个状态需要通过 cookie 或者 session 去实现。
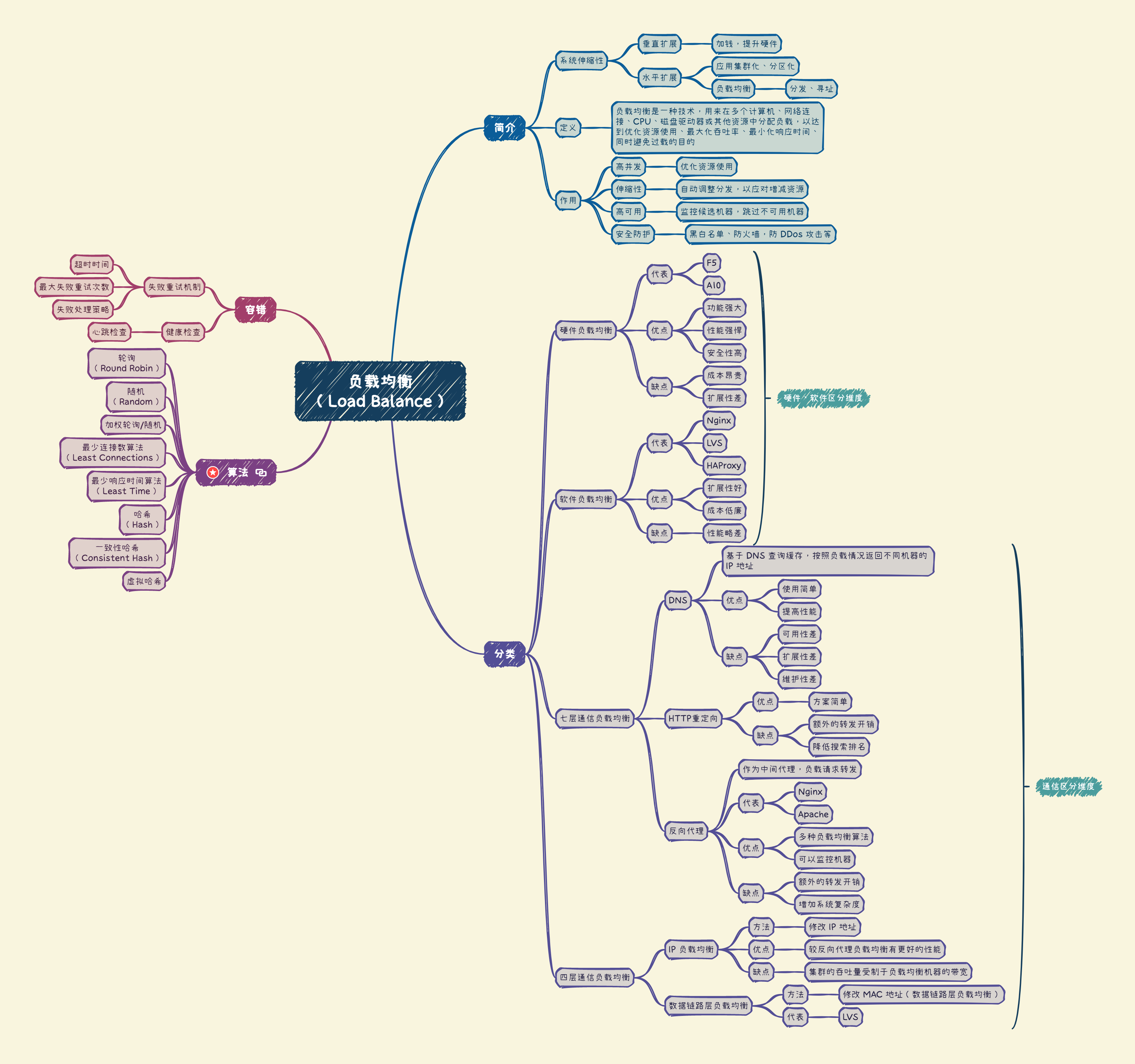
大型系统通常要面对高并发、高可用、海量数据等挑战。
为了提升系统整体的性能,可以采用垂直扩展和水平扩展两种方式。