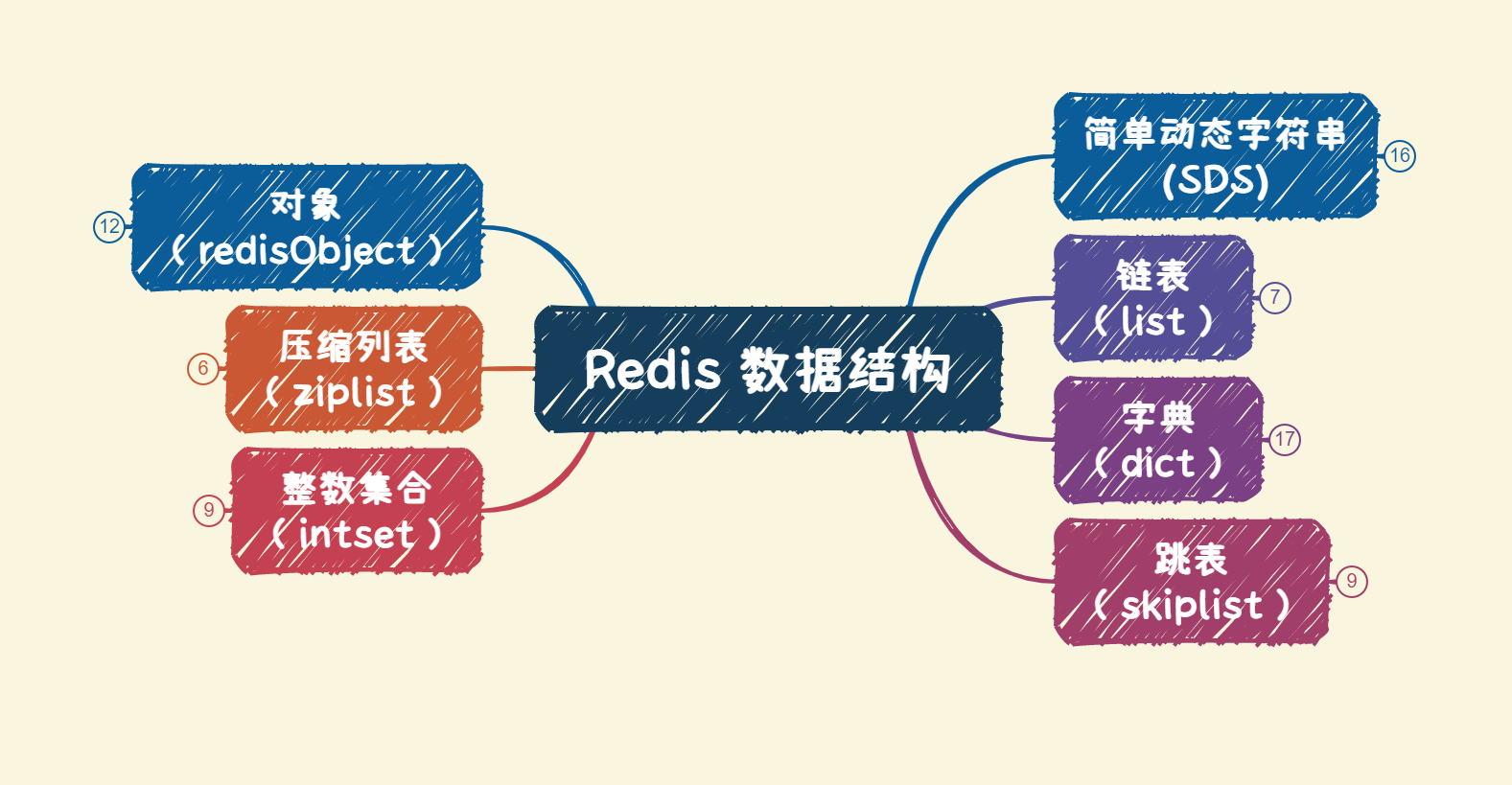
Redis 数据结构
关键词:
对象、SDS、链表、字典、跳表、整数集合、压缩列表
SDS
SDS 简介
SDS 是 Simple Dynamic String 的缩写,即简单动态字符串。Redis 为 SDS 做了一些优化,以替代 C 字符串来表示字符串内容。此外,SDS 还被 Redis 用作缓冲区(buffer),如:AOF 模块中的 AOF 缓冲区;客户端状态中的输入缓冲区。
...大约 29 分钟
关键词:
对象、SDS、链表、字典、跳表、整数集合、压缩列表
SDS 是 Simple Dynamic String 的缩写,即简单动态字符串。Redis 为 SDS 做了一些优化,以替代 C 字符串来表示字符串内容。此外,SDS 还被 Redis 用作缓冲区(buffer),如:AOF 模块中的 AOF 缓冲区;客户端状态中的输入缓冲区。
关键词:链表、数组、散列表、红黑树、B+ 树、LSM 树、跳表
数据库是“按照 数据结构 来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
——上面这句定义对数据库的定义来自百度百科。通过这个定义,我们也能明显看出数据结构是实现数据库的基石。
从本质来看,数据库只负责两件事:读数据、写数据;而数据结构研究的是如何合理组织数据,尽可能提升读、写数据的效率,这恰好是数据库的核心问题。因此,数据结构与数据库这两个领域有非常多的交集。其中,数据库索引最能体现二者的紧密关联。
衡量算法的优劣,有两种评估方式:事前估计和后期测试。
后期测试有性能测试、基准测试(Benchmark)等手段。
但是,后期测试有以下限制:
所以,需要一种方法,可以不受环境或数据规模的影响,粗略地估计算法的执行效率。这种方法就是复杂度分析。
LSM 树具有以下 3 个特点:
LSM 树的这些特点,使得它相对于 B+ 树,在写入性能上有大幅提升。所以,许多 NoSQL 系统都使用 LSM 树作为检索引擎,而且还对 LSM 树进行了优化以提升检索性能。
B+树是在二叉查找树的基础上进行了改造:树中的节点并不存储数据本身,而是只是作为索引。每个叶子节点串在一条链表上,链表中的数据是从小到大有序的。
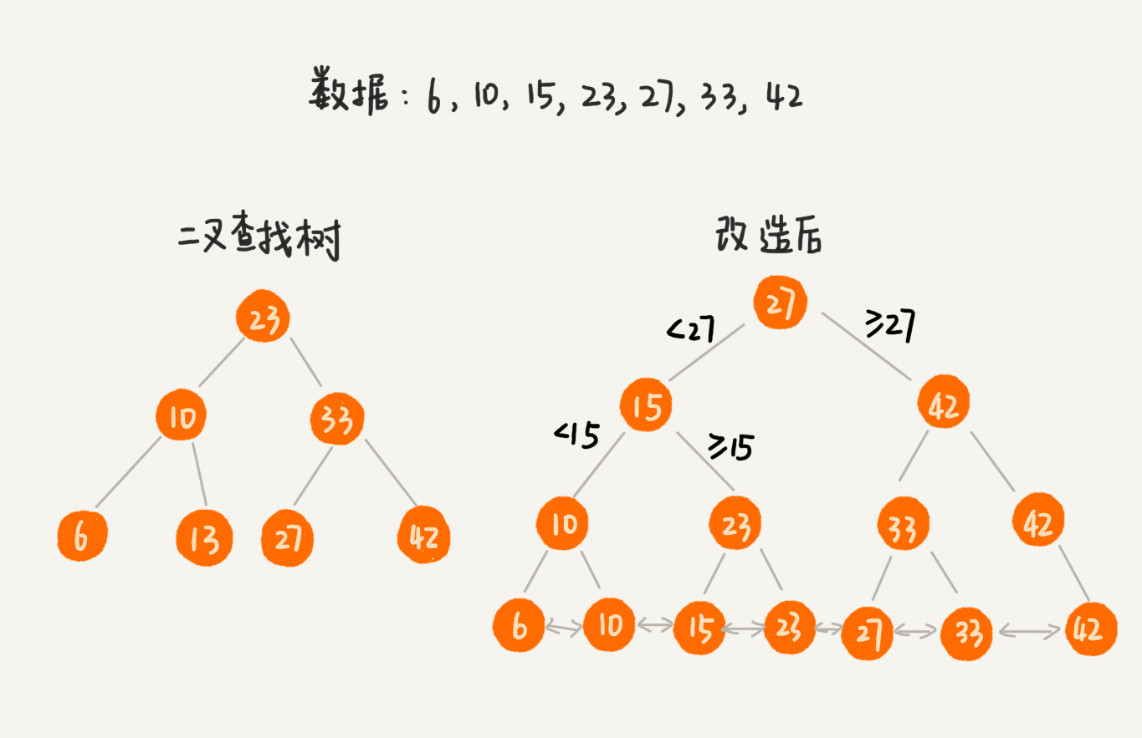
改造之后,如果我们要求某个区间的数据。我们只需要拿区间的起始值,在树中进行查找,当查找到某个叶子节点之后,我们再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止。所有遍历到的数据,就是符合区间值的所有数据。
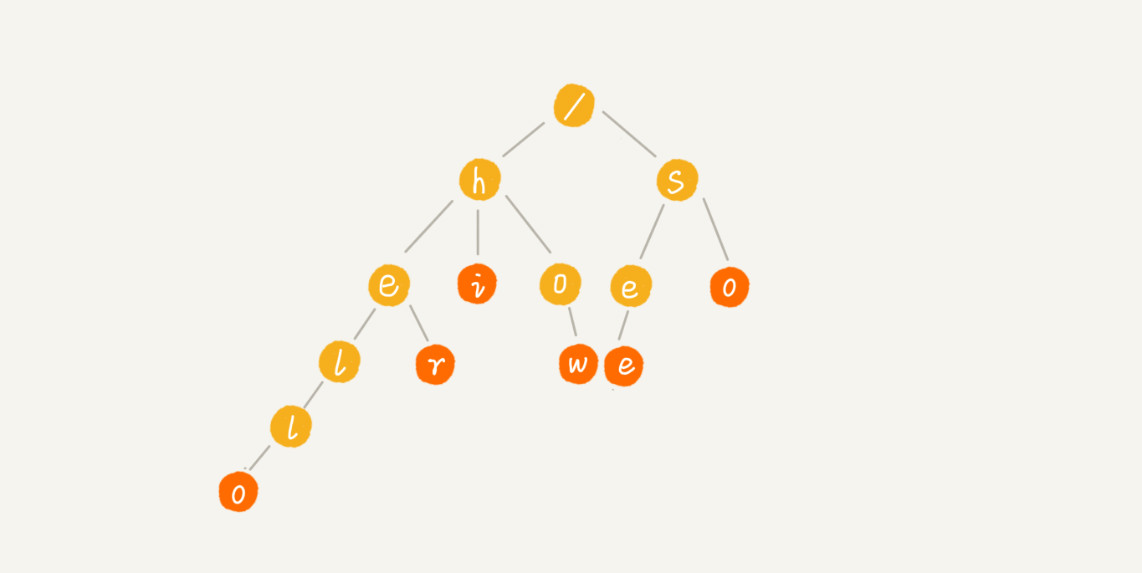
Trie 树(又叫“前缀树”或“字典树”)是一种用于快速查询“某个字符串/字符前缀”是否存在的数据结构。
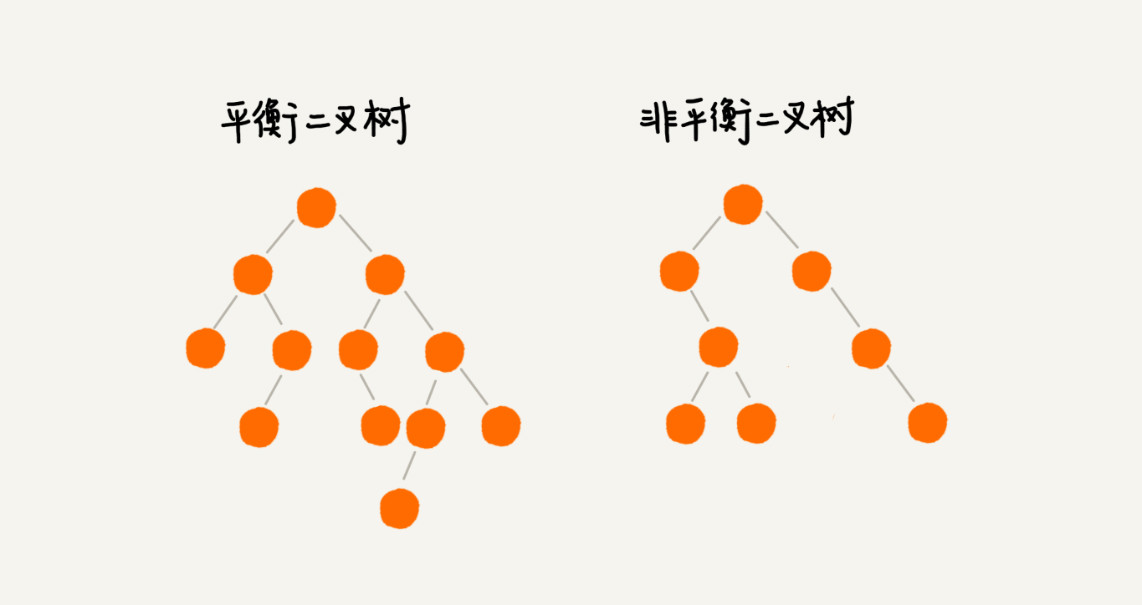
平衡二叉树的严格定义是这样的:二叉树中任意一个节点的左右子树的高度相差不能大于 1。
完全二叉树、满二叉树其实都是平衡二叉树,但是非完全二叉树也有可能是平衡二叉树。
数组和链表分别代表了连续空间和不连续空间的存储方式,它们是线性表(Linear List)的典型代表。其他所有的数据结构,比如栈、队列、二叉树、B+ 树等,实际上都是这两者的结合和变化。
数组用 连续 的内存空间来存储数据。
数组元素的访问是以行或列索引的单一下标表示。
数据结构就是指一组数据的存储结构。算法就是操作数据的一组方法。
查找是根据给定的某个值,在表中确定一个关键字的值等于给定值的记录或数据元素。
若在查找的同时对表记录做修改操作(如插入和删除),则相应的表称之为动态查找表;
否则,称之为静态查找表。
此外,如果查找的全过程都在内存中进行,称之为内查找;
反之,如果查找过程中需要访问外存,称之为外查找。